十分钟搞定pandas(入门教程)
本文是对pandas官方网站上《10Minutes to pandas》的一个简单的翻译,原文在这里。这篇文章是对pandas的一个简单的介绍,详细的介绍请参考:Cookbook 。习惯上,我们会按下面格式引入所需要的包:

一、创建对象
可以通过Data Structure Intro Setion 来查看有关该节内容的详细信息。
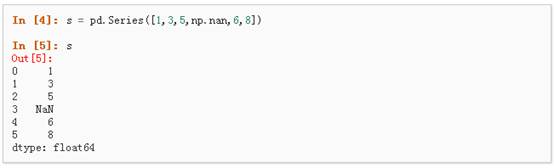
1、可以通过传递一个list对象来创建一个Series,pandas会默认创建整型索引:
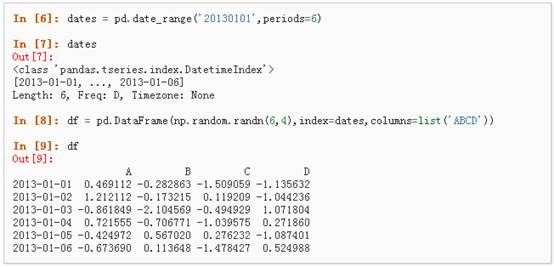
2、通过传递一个numpyarray,时间索引以及列标签来创建一个DataFrame:
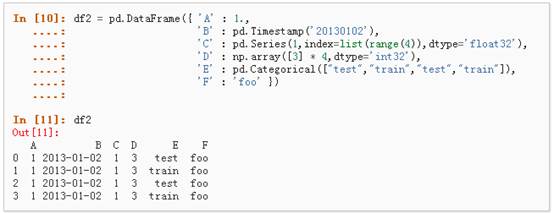
3、通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:
4、查看不同列的数据类型:

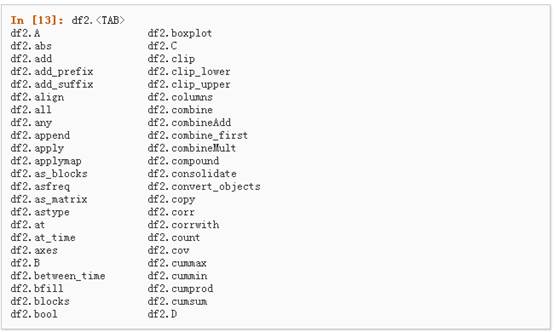
5、如果你使用的是IPython,使用Tab自动补全功能会自动识别所有的属性以及自定义的列,下图中是所有能够被自动识别的属性的一个子集:
二、查看数据
详情请参阅:Basics Section
1、 查看frame中头部和尾部的行:

2、 显示索引、列和底层的numpy数据:

3、 describe()函数对于数据的快速统计汇总:
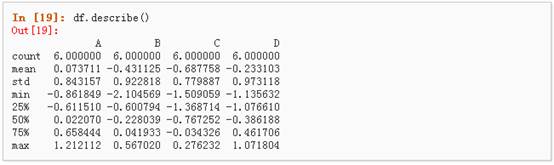
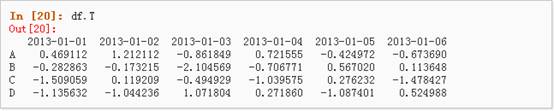
4、 对数据的转置:
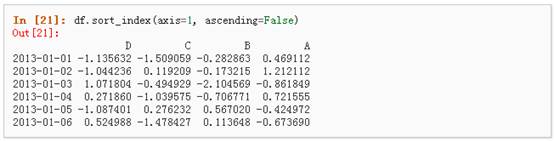
5、 按轴进行排序
6、 按值进行排序

三、选择
虽然标准的Python/Numpy的选择和设置表达式都能够直接派上用场,但是作为工程使用的代码,我们推荐使用经过优化的pandas数据访问方式: .at,.iat,.loc,.iloc和.ix详情请参阅Indexingand Selecing Data 和 MultiIndex/ Advanced Indexing。
l 获取
1、 选择一个单独的列,这将会返回一个Series,等同于df.A:

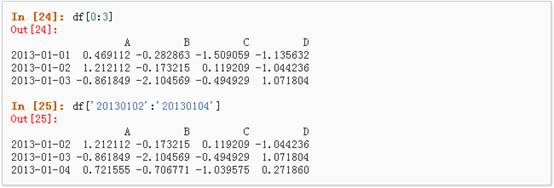
2、 通过[]进行选择,这将会对行进行切片
l 通过标签选择
1、 使用标签来获取一个交叉的区域
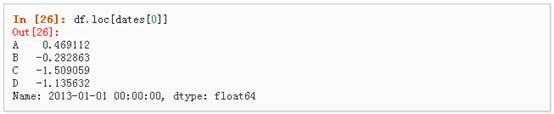
2、 通过标签来在多个轴上进行选择

3、 标签切片

4、 对于返回的对象进行维度缩减

5、 获取一个标量

6、 快速访问一个标量(与上一个方法等价)

l 通过位置选择
1、 通过传递数值进行位置选择(选择的是行)

2、 通过数值进行切片,与numpy/python中的情况类似

3、 通过指定一个位置的列表,与numpy/python中的情况类似

4、 对行进行切片

5、 对列进行切片

6、 获取特定的值

l 布尔索引
1、 使用一个单独列的值来选择数据:

2、 使用where操作来选择数据:
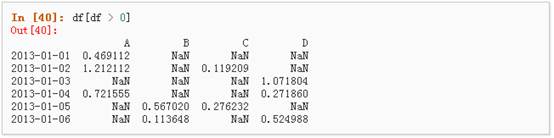
3、 使用isin()方法来过滤:

l 设置
1、 设置一个新的列:

2、 通过标签设置新的值:

3、 通过位置设置新的值:

4、 通过一个numpy数组设置一组新值:

上述操作结果如下:
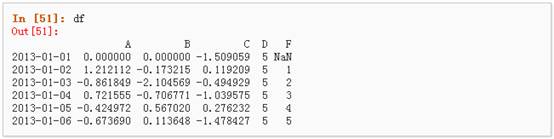
5、 通过where操作来设置新的值:

四、缺失值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中,详情请参阅:Missing Data Section。
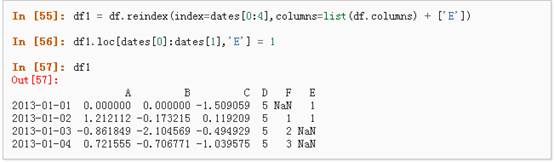
1、 reindex()方法可以对指定轴上的索引进行改变/增加/删除操作,这将返回原始数据的一个拷贝:、
2、 去掉包含缺失值的行:

3、 对缺失值进行填充:
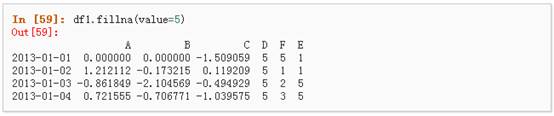
4、 对数据进行布尔填充:

五、相关操作
详情请参与Basic Section On Binary Ops
l 统计(相关操作通常情况下不包括缺失值)
1、 执行描述性统计:

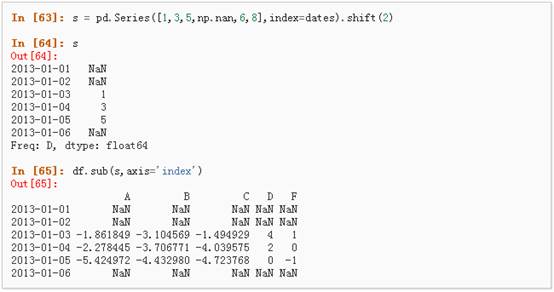
2、 在其他轴上进行相同的操作:

3、 对于拥有不同维度,需要对齐的对象进行操作。Pandas会自动的沿着指定的维度进行广播:
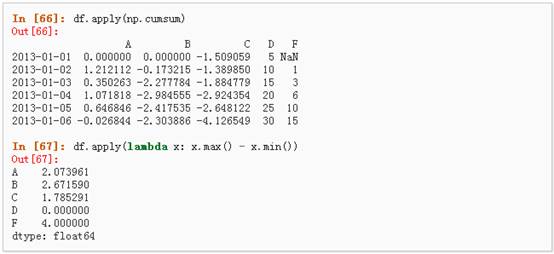
l Apply
1、 对数据应用函数:
l 直方图
具体请参照:Histogrammingand Discretization

l 字符串方法
Series对象在其str属性中配备了一组字符串处理方法,可以很容易的应用到数组中的每个元素,如下段代码所示。更多详情请参考:Vectorized String Methods.

六、合并
Pandas提供了大量的方法能够轻松的对Series,DataFrame和Panel对象进行各种符合各种逻辑关系的合并操作。具体请参阅:Mergingsection
l Concat

l Join 类似于SQL类型的合并,具体请参阅:Databasestyle joining

l Append 将一行连接到一个DataFrame上,具体请参阅Appending:

七、分组
对于”group by”操作,我们通常是指以下一个或多个操作步骤:
l (Splitting)按照一些规则将数据分为不同的组;
l (Applying)对于每组数据分别执行一个函数;
l (Combining)将结果组合到一个数据结构中;
详情请参阅:Groupingsection

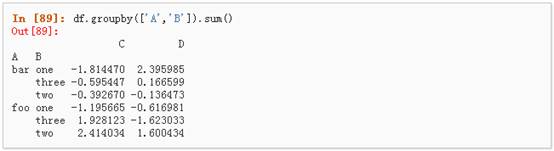
1、 分组并对每个分组执行sum函数:

2、 通过多个列进行分组形成一个层次索引,然后执行函数:
八、Reshaping
详情请参阅HierarchicalIndexing和Reshaping。
l Stack
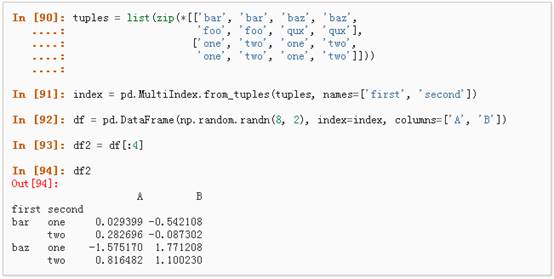

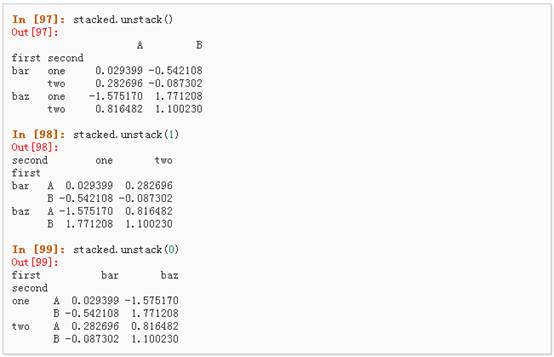
l 数据透视表,详情请参阅:PivotTables.
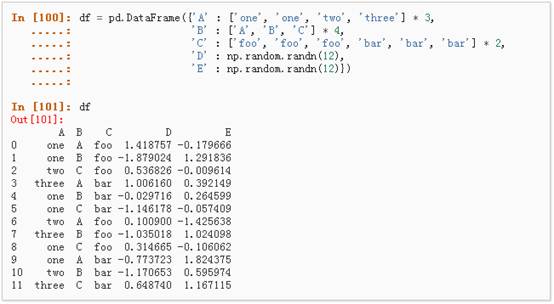
可以从这个数据中轻松的生成数据透视表:

九、时间序列
Pandas在对频率转换进行重新采样时拥有简单、强大且高效的功能(如将按秒采样的数据转换为按5分钟为单位进行采样的数据)。这种操作在金融领域非常常见。具体参考:TimeSeries section。

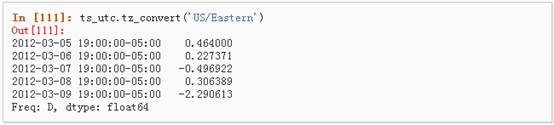
1、 时区表示:
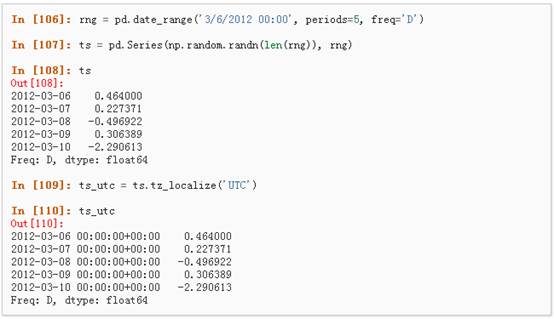
2、 时区转换:
3、 时间跨度转换:

4、 时期和时间戳之间的转换使得可以使用一些方便的算术函数。

十、Categorical
从0.15版本开始,pandas可以在DataFrame中支持Categorical类型的数据,详细介绍参看:categoricalintroduction和APIdocumentation。

1、 将原始的grade转换为Categorical数据类型:

2、 将Categorical类型数据重命名为更有意义的名称:

3、 对类别进行重新排序,增加缺失的类别:

4、 排序是按照Categorical的顺序进行的而不是按照字典顺序进行:

5、 对Categorical列进行排序时存在空的类别:

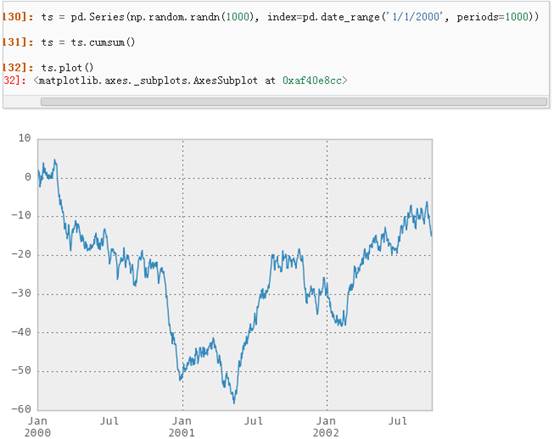
十一、画图
具体文档参看:Plottingdocs
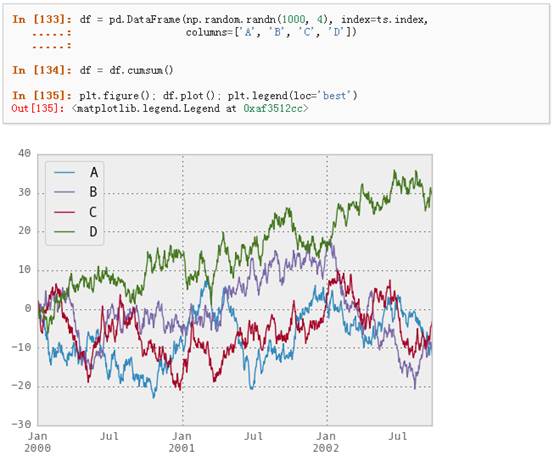
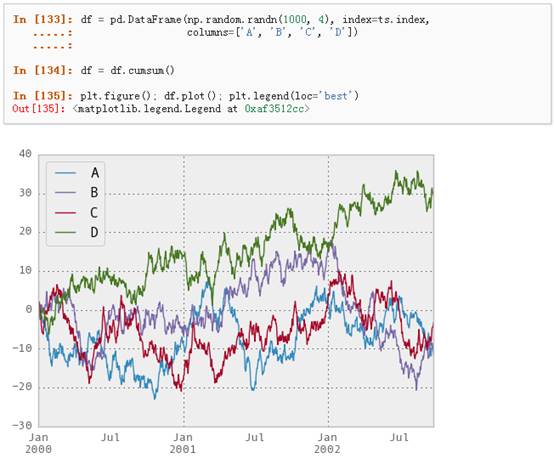
对于DataFrame来说,plot是一种将所有列及其标签进行绘制的简便方法:
十二、导入和保存数据
l CSV,参考:Writingto a csv file
1、 写入csv文件:

2、 从csv文件中读取:

l HDF5,参考:HDFStores
1、 写入HDF5存储:

2、 从HDF5存储中读取:
l Excel,参考:MSExcel
1、 写入excel文件:

2、 从excel文件中读取:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
使用pandas读取csv文件的指定列方法
根据教程实现了读取csv文件前面的几行数据,一下就想到了是不是可以实现前面几列的数据.经过多番尝试总算试出来了一种方法. 之所以想实现读取前面的几列是因为我手头的一个csv文件恰好有后面几列没有可用数据,但是却一直存在着.原来的数据如下: GreydeMac-mini:chapter06 greyzhang$ cat data.csv 1,name_01,coment_01,,,, 2,name_02,coment_02,,,, 3,name_03,coment_03,,,, 4,name_04
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-
Python 中pandas.read_excel详细介绍
Python 中pandas.read_excel详细介绍 #coding:utf-8 import pandas as pd import numpy as np filefullpath = r"/home/geeklee/temp/all_gov_file/pol_gov_mon/downloads/1.xls" #filefullpath = r"/home/geeklee/temp/all_gov_file/pol_gov_mon/downloads/26368f3
-
python中pandas.DataFrame的简单操作方法(创建、索引、增添与删除)
前言 最近在网上搜了许多关于pandas.DataFrame的操作说明,都是一些基础的操作,但是这些操作组合起来还是比较费时间去正确操作DataFrame,花了我挺长时间去调整BUG的.我在这里做一些总结,方便你我他.感兴趣的朋友们一起来看看吧. 一.创建DataFrame的简单操作: 1.根据字典创造: In [1]: import pandas as pd In [3]: aa={'one':[1,2,3],'two':[2,3,4],'three':[3,4,5]} In [4]: bb=
-

Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
python pandas dataframe 按列或者按行合并的方法
concat 与其说是连接,更准确的说是拼接.就是把两个表直接合在一起.于是有一个突出的问题,是横向拼接还是纵向拼接,所以concat 函数的关键参数是axis . 函数的具体参数是: concat(objs,axis=0,join='outer',join_axes=None,ignore_index=False,keys=None,levels=None,names=None,verigy_integrity=False) objs 是需要拼接的对象集合,一般为列表或者字典 axis=0 是
-
在Python中利用Pandas库处理大数据的简单介绍
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择.这次拿到近亿条日志数据,千万级数据已经是关系型数据库的查询分析瓶颈,之前使用过Hadoop对大量文本进行分类,这次决定采用Python来处理数据: 硬件环境 CPU:3.5 GHz Intel Core i7 内存:32 GB HDDR 3 1600 MHz 硬
-
用Python的pandas框架操作Excel文件中的数据教程
引言 本文的目的,是向您展示如何使用pandas来执行一些常见的Excel任务.有些例子比较琐碎,但我觉得展示这些简单的东西与那些你可以在其他地方找到的复杂功能同等重要.作为额外的福利,我将会进行一些模糊字符串匹配,以此来展示一些小花样,以及展示pandas是如何利用完整的Python模块系统去做一些在Python中是简单,但在Excel中却很复杂的事情的. 有道理吧?让我们开始吧. 为某行添加求和项 我要介绍的第一项任务是把某几列相加然后添加一个总和栏. 首先我们将excel 数据 导入到pa
-
python中pandas.DataFrame对行与列求和及添加新行与列示例
本文介绍的是python中pandas.DataFrame对行与列求和及添加新行与列的相关资料,下面话不多说,来看看详细的介绍吧. 方法如下: 导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFrame(np.random.randn(4, 5), columns=['A', 'B', 'C', 'D', 'E']) DataFrame数据预览: A