Python批量查询关键词微信指数实例方法
教你用Python批量查询关键词微信指数。
前期准备安装好Python开发环境及Fiddler抓包工具。前期准备安装好Python开发环境及Fiddler抓包工具。
首先打开Fiddler软件,点击Tools,在下拉菜单选择Options,然后选中HTTPS,进行HTTPS设置,如下图所示:

再进行connections设置,如下图所示:

手机配置主要是使电脑和手机处于同一个局域网,打开手机WLAN设置,开启手动代理,然后设置代理服务器主机名和代理服务器端口。代理服务器主机名为电脑IPv4地址,电脑运行cmd,输入ipconfig回车即可获取。如下图:

代理服务器端口为Fiddler软件connections设置的默认端口8888。当然这个端口写可以修改成别的,只要一致就可以,这边就直接使用默认端口了。最终配置如下图所示:

然后手机浏览器访问http://+IPv4地址+端口,如本例http://192.168.100.226:8888/,在页面中点击FiddlerRoot certificate下载证书,按照提示安装即可。这样就实现了全部配置,在手机访问页面,就可以在Fiddler中看到抓包数据了。然后手机浏览器访问http://+IPv4地址+端口,如本例http://192.168.100.226:8888/,在页面中点击FiddlerRoot certificate下载证书,按照提示安装即可。这样就实现了全部配置,在手机访问页面,就可以在Fiddler中看到抓包数据了。
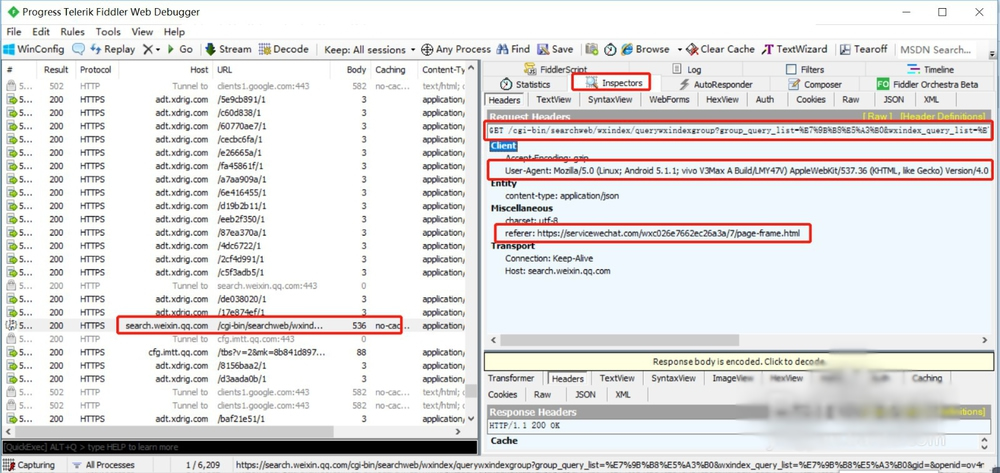
打开微信指数小程序,搜索关键词,如“演唱会”,找到Host为search.weixin.qq.com的请求点击进去,取出Request Headers中的几个参数:GET,即请求连接;User-Agent用户代理及referer(如下图所示)。代码中需要修改请求头中的这三个配置。
代码示例:
import requests,urllib,json,random,time
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
headers = {'Accept-Encoding': 'gzip',
'referer': 'https://servicewechat.com/wxc026e7662ec26a3a/7/page-frame.html',#需按实际抓包修改
'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (Linux; Android 5.1.1; vivo V3Max A Build/LMY47V) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/39.0.0.0 Mobile Safari/537.36 MicroMessenger/7.0.4.1420(0x27000435) Process/appbrand2 NetType/WIFI Language/zh_CN', #需按实际抓包修改
'Host': 'search.weixin.qq.com',
'Connection': 'Keep-Alive'
}
with open('weixin.txt','w',encoding='utf-8') as f:
for line in open('keywords.txt',encoding='utf-8-sig'):
word = line.rstrip()
kw = urllib.parse.quote(word)
url = 'https://search.weixin.qq.com/cgi-bin/searchweb/wxindex/querywxindexgroup?group_query_list={}&wxindex_query_list={}&gid=&openid=ov4ns0NiA4_Cshlsxa5pT640jC5w&search_key=1560843991380393_3137533225'.format(kw,kw) #需按实际抓包修改
html = requests.get(url,headers=headers,verify=False).text
time.sleep(random.uniform(2, 4))
datas = json.loads(html)
if datas.get('data'):
try:
wxindex_str = datas['data']['group_wxindex'][0]['wxindex_str']
if wxindex_str:
index = wxindex_str.split(',')[-1]
else:
index = 0
except:
index = 0
else:
index = 0
data = '{}\t{}\n'.format(word,index)
print(data.rstrip())
f.write(data)
注意请求链接的修改,需要将取出的原始链接中groupquerylist及wxindexquerylist等号后边的字符修改成{}。关键词保存在keywords.txt文件中,一行一个。运行脚本,数据输出如下图所示,数据最终会保存到weixin.txt。

总结:
以上就是关于Python批量查询关键词微信指数的全部知识点,感谢大家的学习和对我们的支持。
相关推荐
-
Python批量查询关键词微信指数实例方法
教你用Python批量查询关键词微信指数. 前期准备安装好Python开发环境及Fiddler抓包工具.前期准备安装好Python开发环境及Fiddler抓包工具. 首先打开Fiddler软件,点击Tools,在下拉菜单选择Options,然后选中HTTPS,进行HTTPS设置,如下图所示: 再进行connections设置,如下图所示: 手机配置主要是使电脑和手机处于同一个局域网,打开手机WLAN设置,开启手动代理,然后设置代理服务器主机名和代理服务器端口.代理服务器主机名为电脑IPv4地址,
-

Python批量查询域名是否被注册过
step1. 找一个单词数据库 这里有一个13万个单词的 http://download.csdn.net/detail/u011004567/9675906 新建个mysql数据库words,导入words里面就行 step2.找个查询接口 这里我用的是http://apistore.baidu.com/astore/serviceinfo/27586.html step3. 执行Python脚本 # -*- coding: utf-8 -*- ''' 域名注册查询 ''' __author_
-
python批量查询、汉字去重处理CSV文件
CSV文件用记事本打开后一般为由逗号隔开的字符串,其处理方法用Python的代码如下.为方便各种程度的人阅读在代码中有非常详细的注释. 1.查询指定列,并保存到新的csv文件. # -*- coding: utf-8 -*- ''''' Author: Good_Night Time: 2018/1/30 03:50 Edition: 1.0 ''' # 导入必须的csv库 import csv # 创建临时文件temp.csv找出所需要的列 temp_file = open("temp.csv
-
Python 批量验证和添加手机号码为企业微信联系人
目录 需求 源码 运行 需求 批量验证和添加手机号码为企业微信账号的联系人 源码 import tkinter as tk import pyautogui as pg import tkinter.messagebox as msgbox def setpos(): global x,y try: x,y = eval(tEntry.get()) except: pass pg.click(x-150,y) pg.typewrite('1') pg.moveTo(x,y,duration=0.
-
python逆向微信指数爬取实现步骤
目录 微信指数爬取 1.MAC系统Appium的环境搭建 1. homebrew的安装 2. 通过brew安装node 3. 安装npm 4. 安装android-sdk-macosx 5. 安装jdk 6. 环境变量配置 7. 安装appium-doctor 8. 安装appium命令行版 9. 安装mitmproxy 10.安装网易mumu安卓模拟器 2.微信指数小程序爬取 1.启动appium 在终端输入 2.启动网易mumu安卓模拟器并安装微信 3. 查看adb连接的设备 4. 模拟器安
-
使用python批量读取word文档并整理关键信息到excel表格的实例
目标 最近实验室里成立了一个计算机兴趣小组 倡议大家多把自己解决问题的经验记录并分享 就像在CSDN写博客一样 虽然刚刚起步 但考虑到后面此类经验记录的资料会越来越多 所以一开始就要做好模板设计(如下所示) 方便后面建立电子数据库 从而使得其他人可以迅速地搜索到相关记录 据说"人生苦短,我用python" 所以决定用python从docx文档中提取文件头的信息 然后把信息更新到一个xls电子表格中,像下面这样(直接po结果好了) 而且点击文件路径可以直接打开对应的文件(含超链接) 代码
-
PHP配合fiddler抓包抓取微信指数小程序数据的实现方法分析
本文实例讲述了PHP配合fiddler抓包抓取微信指数小程序数据的实现方法.分享给大家供大家参考,具体如下: 这两天研究了下微信指数这个东西.要抓取呢,按照一般思路的话,那就是使用fiddler抓取手机包,然后进行分析获取地址然后请求就可以了. 这么想你是没错,如果你果断这么做了,那就是too yang too simple了.大家可以看下,微信抓取有以下几个步骤: 1.开始登陆小程序 2.获取访问需要的令牌 3.那这令牌去获取数据 首先的难点就是小程序的登陆那一步.你得先登陆了微信之后才可以访
-
python批量导入数据进Elasticsearch的实例
ES在之前的博客已有介绍,提供很多接口,本文介绍如何使用python批量导入.ES官网上有较多说明文档,仔细研究并结合搜索引擎应该不难使用. 先给代码 #coding=utf-8 from datetime import datetime from elasticsearch import Elasticsearch from elasticsearch import helpers es = Elasticsearch() actions = [] f=open('index.txt') i=
-
python批量从es取数据的方法(文档数超过10000)
如下所示: """ 提取文档数超过10000的数据 按照某个字段的值具有唯一性进行升序, 按照@timestamp进行降序, 第一次查询,先将10000条数据取出, 取出最后一个时间戳, 在第二次查询中,设定@timestamp小于将第一次得到的最后一个时间戳, 同时设定某个字段的值具有唯一性进行升序, 按照@timestamp进行降序, """ from elasticsearch import Elasticsearch import os
-
Python爬虫爬取微信朋友圈
接下来,我们将实现微信朋友圈的爬取. 如果直接用 Charles 或 mitmproxy 来监听微信朋友圈的接口数据,这是无法实现爬取的,因为数据都是被加密的.而 Appium 不同,Appium 作为一个自动化测试工具可以直接模拟 App 的操作并可以获取当前所见的内容.所以只要 App 显示了内容,我们就可以用 Appium 抓取下来. 1. 本节目标 本节我们以 Android 平台为例,实现抓取微信朋友圈的动态信息.动态信息包括好友昵称.正文.发布日期.其中发布日期还需要进行转换,如日期