Scrapy的简单使用教程
在这篇入门教程中,我们假定你已经安装了python。如果你还没有安装,那么请参考安装指南。
首先第一步:进入开发环境,workon article_spider
进入这个环境:

安装Scrapy,在安装的过程中出现了一些错误:通常这些错误都是部分文件没有安装导致的,因为大学时经常出现,所以对解决这种问题,很实在,直接到http://www.lfd.uci.edu/~gohlke/pythonlibs/这个网站下载对应的文件,下载后用pip安装,具体过程不在赘述。

然后进入工程目录,并打开我们的新创建的虚拟环境:

新建scrapy工程:ArticleSpider

创建好工程框架:在pycharm中导入
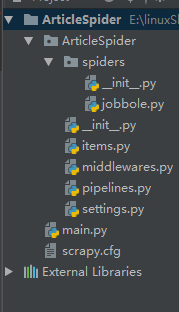
scrapy.cfg: 项目的配置文件。
ArticleSpeder/: 该项目的python模块。之后您将在此加入代码。
ArticleSpeder/items.py: 项目中的item文件。
ArticleSpeder/pipelines.py: 项目中的pipelines文件。
ArticleSpeder/settings.py: 项目的设置文件。
ArticleSpeder/spiders/: 放置spider代码的目录。
回到dos窗口用basic创建模板

上面pycharm的截图中已经创建好了:
为了今后更好的开发,创建一个用于debug的类main.py
from scrapy.cmdline import execute import sys import os print(os.path.dirname(os.path.abspath(__file__))) sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy","crawl","jobbole"])
这是代码内容
import sys 为了设置工程目录,调用命令才会生效
里面的路径最好不要写死:可以通过os获取路径,更加灵活
execute用来执行目标程序的
jobbole.py的内容
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/110287']
def parse(self, response):
re_selector = response.xpath("/html/body/div[1]/div[3]/div[1]/div[1]/h1")
re2_selector = response.xpath('//*[@id="post-110287"]/div[1]/h1')
title = response.xpath('//div[@class="entry-header"]/h1/text()')
create_date = response.xpath("")
#//*[@id="112706votetotal"]
dian_zan = int(response.xpath("//span[contains(@class,'vote-post-up ')]/h10/text()").extract()[0])
pass
通过xpath技术获取对应文章的一些字段信息,包括标题,时间,评论数,点赞数等,因为比较简单所以不在赘述
写到这儿,大家也知道每次在pycharm里面debug和麻烦,因为scrapy比较大,所以这时候我们可以使用Scrapy shell来调试

标记部分是目标网站的地址:现在我们可以更加愉悦的进行调试了。
今天scrapy的初体验就到这里了
相关推荐
-
Python实现从脚本里运行scrapy的方法
本文实例讲述了Python实现从脚本里运行scrapy的方法.分享给大家供大家参考.具体如下: 复制代码 代码如下: #!/usr/bin/python import os os.environ.setdefault('SCRAPY_SETTINGS_MODULE', 'project.settings') #Must be at the top before other imports from scrapy import log, signals, project from scrapy.x
-
使用scrapy实现爬网站例子和实现网络爬虫(蜘蛛)的步骤
复制代码 代码如下: #!/usr/bin/env python# -*- coding: utf-8 -*- from scrapy.contrib.spiders import CrawlSpider, Rulefrom scrapy.contrib.linkextractors.sgml import SgmlLinkExtractorfrom scrapy.selector import Selector from cnbeta.items import CnbetaItemclass
-
python使用scrapy解析js示例
复制代码 代码如下: from selenium import selenium class MySpider(CrawlSpider): name = 'cnbeta' allowed_domains = ['cnbeta.com'] start_urls = ['http://www.jb51.net'] rules = ( # Extract links matching 'category.php' (but not matching 'subsectio
-

零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
在Linux系统上安装Python的Scrapy框架的教程
这是一款提取网站数据的开源工具.Scrapy框架用Python开发而成,它使抓取工作又快又简单,且可扩展.我们已经在virtual box中创建一台虚拟机(VM)并且在上面安装了Ubuntu 14.04 LTS. 安装 Scrapy Scrapy依赖于Python.开发库和pip.Python最新的版本已经在Ubuntu上预装了.因此我们在安装Scrapy之前只需安装pip和python开发库就可以了. pip是作为python包索引器easy_install的替代品,用于安装和管理Python
-
使用Python的Scrapy框架编写web爬虫的简单示例
在这个教材中,我们假定你已经安装了Scrapy.假如你没有安装,你可以参考这个安装指南. 我们将会用开放目录项目(dmoz)作为我们例子去抓取. 这个教材将会带你走过下面这几个方面: 创造一个新的Scrapy项目 定义您将提取的Item 编写一个蜘蛛去抓取网站并提取Items. 编写一个Item Pipeline用来存储提出出来的Items Scrapy由Python写成.假如你刚刚接触Python这门语言,你可能想要了解这门语言起,怎么最好的利用这门语言.假如你已经熟悉其它类似的语言,想要快速
-
讲解Python的Scrapy爬虫框架使用代理进行采集的方法
1.在Scrapy工程下新建"middlewares.py" # Importing base64 library because we'll need it ONLY in case if the proxy we are going to use requires authentication import base64 # Start your middleware class class ProxyMiddleware(object): # overwrite process
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
Scrapy的简单使用教程
在这篇入门教程中,我们假定你已经安装了python.如果你还没有安装,那么请参考安装指南. 首先第一步:进入开发环境,workon article_spider 进入这个环境: 安装Scrapy,在安装的过程中出现了一些错误:通常这些错误都是部分文件没有安装导致的,因为大学时经常出现,所以对解决这种问题,很实在,直接到http://www.lfd.uci.edu/~gohlke/pythonlibs/这个网站下载对应的文件,下载后用pip安装,具体过程不在赘述. 然后进入工程目录,并打开我们的新
-
Python爬虫之Scrapy环境搭建案例教程
Python爬虫之Scrapy环境搭建 如何搭建Scrapy环境 首先要安装Python环境,Python环境搭建见:https://blog.csdn.net/alice_tl/article/details/76793590 接下来安装Scrapy 1.安装Scrapy,在终端使用pip install Scrapy(注意最好是国外的环境) 进度提示如下: alicedeMacBook-Pro:~ alice$ pip install Scrapy Collecting Scrapy Usi
-
python爬虫框架Scrapy基本应用学习教程
在正式编写爬虫案例前,先对 scrapy 进行一下系统的学习. scrapy 安装与简单运行 使用命令 pip install scrapy 进行安装,成功之后,还需要随手收藏几个网址,以便于后续学习使用. scrapy 官网:https://scrapy.org scrapy 文档:https://doc.scrapy.org/en/latest/intro/tutorial.html scrapy 更新日志:https://docs.scrapy.org/en/latest/news.htm
-
Python中Scrapy框架的入门教程分享
目录 前言 安装Scrapy 创建一个Scrapy项目 创建一个爬虫 运行爬虫 结论 前言 Scrapy是一个基于Python的Web爬虫框架,可以快速方便地从互联网上获取数据并进行处理.它的设计思想是基于Twisted异步网络框架,可以同时处理多个请求,并且可以使用多种处理数据的方式,如提取数据.存储数据等. 本教程将介绍如何使用Scrapy框架来编写一个简单的爬虫,从而让您了解Scrapy框架的基本使用方法. 安装Scrapy 首先,您需要在您的计算机上安装Scrapy框架.您可以使用以下命
-
正则表达式简介及在C++11中的简单使用教程
正则表达式Regex(regular expression)是一种强大的描述字符序列的工具.在许多语言中都存在着正则表达式,C++11中也将正则表达式纳入了新标准的一部分,不仅如此,它还支持了6种不同的正则表达式的语法,分别是:ECMASCRIPT.basic.extended.awk.grep和egrep.其中ECMASCRIPT是默认的语法,具体使用哪种语法我们可以在构造正则表达式的时候指定. 正则表达式是一种文本模式.正则表达式是强大.便捷.高效的文本处理工具.正则表达式本身,加上如同一门
-
CentOS安装mysql5.7 及简单配置教程详解
安装 保证你的用户有权限 安装 没有 切换 root su root (su的意思:swich user) # rpm -ivh http://dev.mysql.com/get/mysql57-community-release-el6-9.noarch.rpm 可能会遇到 warning: /var/tmp/rpm-tmp.6V5aFC: Header V3 DSA/SHA1 Signature, key ID 5072e1f5: NOKEY 可以忽略(个人意见,百度了一下没找到合适的答案)
-
windows下Nginx多域名简单配置教程
本文实例为大家分享了Nginx多域名的简单配置教程,供大家参考,具体内容如下 1. windows下安装nginx的目录结构如下: 2. 在nginx-1.12.1目录下conf/nginx.conf 内容 #user nobody; worker_processes 1; events { worker_connections 1024; } http { include mime.types; default_type application/octet-stream; sendfile o
-
在Android Studio中Parcelable插件的简单使用教程
在Android Studio中,你可以很快速的使用Parcelable插件进行实体类的序列化的实现,使用该插件后,你的实体类可以快速的实现Parcelable接口而不用写额外的代码.因为该插件会帮你快速的生成必须提供的方法,可以说是很高效率的了. 首先需要下载该插件: 在File->Setting->Plugins里的搜索框内输入内容:android parcelable code generator,然后自己下载好重启studio即可使用该插件了. 下载插件界面: 重启studio: 点击
-
vuex的简单使用教程
什么是Vuex? vuex是一个专门为vue.js设计的集中式状态管理架构.状态?我把它理解为在data中的属性需要共享给其他vue组件使用的部分,就叫做状态.简单的说就是data中需要共用的属性. 使用vuex进行组件间数据的管理 npm i vuex -S main.js import Vue from 'vue' import App from './App.vue' import store from './store.js' new Vue({ store, el: '#app', r
-
python中format()函数的简单使用教程
先给大家介绍下python中format函数,在文章下面给大家介绍python.format()函数的简单使用 ---恢复内容开始--- python中format函数用于字符串的格式化 通过关键字 print('{名字}今天{动作}'.format(名字='陈某某',动作='拍视频'))#通过关键字 grade = {'name' : '陈某某', 'fenshu': '59'} print('{name}电工考了{fenshu}'.format(**grade))#通过关键字,可用字典当关键