对pandas的层次索引与取值的新方法详解
1、层次索引
1.1 定义
在某一个方向拥有多个(两个及两个以上)索引级别,就叫做层次索引。
通过层次化索引,pandas能够以较低维度形式处理高纬度的数据
通过层次化索引,可以按照层次统计数据
层次索引包括Series层次索引和DataFrame层次索引
1.2 Series的层次索引
import numpy as np
import pandas as pd
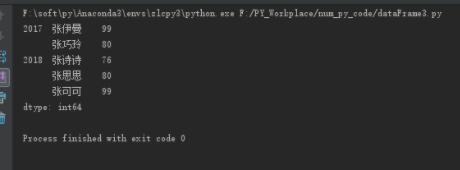
s1 = pd.Series(data=[99, 80, 76, 80, 99],
index=[['2017', '2017', '2018', '2018', '2018'], ['张伊曼', '张巧玲', '张诗诗', '张思思', '张可可']])
print(s1)
1.3 DataFrame的层次索引
# DataFrame的层次索引
df1 = pd.DataFrame({
'year': [2016, 2016, 2017, 2017, 2018],
'fruit': ['apple', 'banana', 'apple', 'banana', 'apple'],
'production': [10, 30, 20, 70, 100],
'profits': [40, 30, 60, 80,10],
})
print("df1===================================")
print(df1)
df2 = df1.set_index(['year', 'fruit'])
print("df2===================================")
print(df2)
print("df2.index===================================")
print(df2.index)
print("df2.sum(level='year')===================================")
print(df2.sum(level='year'))
print("df2.mean(level='fruit')===================================")
print(df2.mean(level='fruit'))
print("df2.sum(level=['year', 'fruit'])===================================")
print(df2.sum(level=['year', 'fruit']))


2、取值的新方法
ix是比较老的方法 新方式是使用iloc loc
iloc 对下标值进行操作 Series与DataFrame都可以操作
loc 对索引值进行操作 Series与DataFrame都可以操作
2.1 Series
# # 取值的新方法
s1 = pd.Series(data=[99, 80, 76, 80, 99],
index=[['2017', '2017', '2018', '2018', '2018'], ['张伊曼', '张巧玲', '张诗诗', '张思思', '张可可']])
print("s1=================================")
print(s1)
print("s1.iloc[2]=================================")
print(s1.iloc[2])
print("s1.loc['2018']['张思思']=================================")
print(s1.loc['2018']['张思思'])

2.2 DataFrame
df1 = pd.DataFrame({
'year': [2016, 2016, 2017, 2017, 2018],
'fruit': ['apple', 'banana', 'apple', 'banana', 'apple'],
'production': [10, 30, 20, 70, 100],
'profits': [40, 30, 60, 80,10],
})
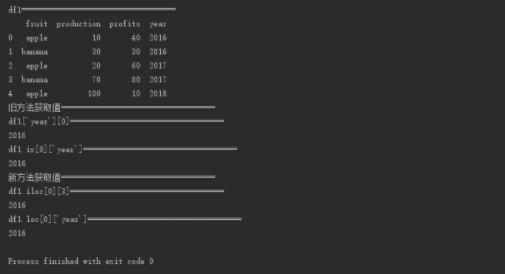
print("df1===================================")
print(df1)
print("旧方法获取值===================================")
print("df1['year'][0]===================================")
print(df1['year'][0])
print("df1.ix[0]['year']===================================")
print(df1.ix[0]['year'])
print("新方法获取值===================================")
print("df1.iloc[0][3]===================================")
print(df1.iloc[0][3])
print("df1.loc[0]['year']===================================")
print(df1.loc[0]['year'])
以上这篇对pandas的层次索引与取值的新方法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python遍历pandas数据方法总结
前言 Pandas是python的一个数据分析包,提供了大量的快速便捷处理数据的函数和方法.其中Pandas定义了Series 和 DataFrame两种数据类型,这使数据操作变得更简单.Series 是一种一维的数据结构,类似于将列表数据值与索引值相结合.DataFrame 是一种二维的数据结构,接近于电子表格或者mysql数据库的形式. 在数据分析中不可避免的涉及到对数据的遍历查询和处理,比如我们需要将dataframe两列数据两两相除,并将结果存储于一个新的列表中.本文通过该例程介绍对pa
-
pandas.dataframe按行索引表达式选取方法
需要把一个从csv文件里读取来的数据集等距抽样分割,这里用到了列表表达式和dataframe.iloc 先生成索引列表: index_list = ['%d' %i for i in range(df.shape[0]) if i % 3 == 0] 在dataframe中选取 sample_df = df.iloc[index_list] 合起来 sample_df = df.iloc[['%d' %i for i in range(df.shape[0]) if i % 3 == 0]] 各
-
对pandas中iloc,loc取数据差别及按条件取值的方法详解
Dataframe使用loc取某几行几列的数据: print(df.loc[0:4,['item_price_level','item_sales_level','item_collected_level','item_pv_level']]) 结果如下,取了index为0到4的五行四列数据. item_price_level item_sales_level item_collected_level item_pv_level 0 3 3 4 14 1 3 3 4 14 2 3 3 4 14
-
浅谈Pandas 排序之后索引的问题
如下所示: In [1]: import pandas as pd ...: df=pd.DataFrame({"a":[1,2,3,4,5],"b":[5,4,3,2,1]}) In [2]: df Out[2]: a b 0 1 5 1 2 4 2 3 3 3 4 2 4 5 1 In [3]: df=df.sort_values(by="b") # 按照b列排序 In [4]: df Out[4]: a b 4 5 1 3 4 2 2 3
-
pandas数据清洗,排序,索引设置,数据选取方法
此教程适合有pandas基础的童鞋来看,很多知识点会一笔带过,不做详细解释 Pandas数据格式 Series DataFrame:每个column就是一个Series 基础属性shape,index,columns,values,dtypes,describe(),head(),tail() 统计属性Series: count(),value_counts(),前者是统计总数,后者统计各自value的总数 df.isnull() df的空值为True df.notnull() df的非空值为T
-
浅谈pandas用groupby后对层级索引levels的处理方法
层及索引levels,刚开始学习pandas的时候没有太多的操作关于groupby,仅仅是简单的count.sum.size等等,没有更深入的利用groupby后的数据进行处理.近来数据处理的时候有遇到这类问题花了一点时间,所以这里记录以及复习一下:(以下皆是个人实践后的理解) 我使用一个实例来讲解下面的问题:一张数据表中有三列(动物物种.物种品种.品种价格),选出每个物种从大到小品种的前两种,最后只需要品种和价格这两列. 以上这张表是我们后面需要处理的数据表 (物种 品种 价格) levels
-
pandas实现选取特定索引的行
如下所示: >>> import numpy as np >>> import pandas as pd >>> index=np.array([2,4,6,8,10]) >>> data=np.array([3,5,7,9,11]) >>> data=pd.DataFrame({'num':data},index=index) >>> print(data) num 2 3 4 5 6 7 8 9
-
pandas将DataFrame的列变成行索引的方法
pandas提供了set_index方法可以将DataFrame的列(多列)变成行索引,通过reset_index方法可以将层次化索引的级别会被转移到列里面. 1.DataFrame的set_index方法 data = pd.DataFrame(np.arange(1,10).reshape(3,3),index=["a","b","c"],columns=["A","B","C"])
-
对pandas的层次索引与取值的新方法详解
1.层次索引 1.1 定义 在某一个方向拥有多个(两个及两个以上)索引级别,就叫做层次索引. 通过层次化索引,pandas能够以较低维度形式处理高纬度的数据 通过层次化索引,可以按照层次统计数据 层次索引包括Series层次索引和DataFrame层次索引 1.2 Series的层次索引 import numpy as np import pandas as pd s1 = pd.Series(data=[99, 80, 76, 80, 99], index=[['2017', '2017',
-
Pandas实现两个表的连接功能的方法详解
目录 准备数据 先导入模块 输出内容 连接 内连接 外连接 左连接 右连接 上次介绍了pandas的多条件筛选,这些都是一些数据处理的必要技能,也不贪多,咱们每次学习一点. 这次咱们说说pandas的两个表的连接技能merge,也就是根据一个表的条件去匹配另一个表的内容. 话不多说,直接正文. 准备数据 先导入模块 import pandas as pd df1 = pd.DataFrame({ '姓名': ['张三', '李四', '王五', '刘六', '齐四'], '号码'
-
python字典多键值及重复键值的使用方法(详解)
在Python中使用字典,格式如下: dict={ key1:value1 , key2;value2 ...} 在实际访问字典值时的使用格式如下: dict[key] 多键值 字典的多键值形式如下: dict={(ke11,key12):value ,(key21,key22):value ...} 在实际访问字典里的值时的具体形式如下所示(以第一个键为例): dict[key11,key12] 或者是: dict[(key11,key12)] 以下是实际例子: 多值 在一个键值对应多个值时,
-
JavaScript判断两个值相等的方法详解
目录 前言 非严格相等 严格相等 同值零 同值 总结 前言 在 JavaScript 中如何判断两个值相等,这个问题看起来非常简单,但并非如此,在 JavaScript 中存在 4 种不同的相等逻辑,如果你不知道他们的区别,或者认为判断相等非常简单,那么本文非常适合你阅读. ECMAScript 是 JavaScript 的语言规范,在ECMAScript 规范中存在四种相等算法,如下图所示: 上图中四种算法对应的中文名字如下,大部分前端应该熟悉严格相等和非严格相等,但对于同值零和同值却不熟悉,
-
jQuery对html元素的取值与赋值实例详解
本文实例讲述了jQuery对html元素的取值与赋值方法.分享给大家供大家参考,具体如下: Jquery给基本控件的取值.赋值 TEXTBOX: var str = $('#txt').val(); $('#txt').val("Set Lbl Value"); //文本框,文本区域: $("#text_id").attr("value",'');//清空内容 $("#text_id").attr("value&qu
-
js中复选框的取值及赋值示例详解
1.复选框的取值:(js部分) var checkboxdata = $("input[name=payoperator]:checked").map(function() { return $(this).val(); }).get().join(","); <div class="form-group"> <label class="col-lg-2 col-md-2 col-sm-12 control-label
-
使用Math.floor与Math.random取随机整数的方法详解
Math.random():获取0~1随机数 Math.floor() method rounds a number DOWNWARDS to the nearest integer, and returns the result. (小于等于 x,且与 x 最接近的整数.)其实返回值就是该数的整数位:Math.floor(0.666) --> 0Math.floor(39.2783) --> 39 所以我们可以使用Math.floor(Math.random())去获取你想要的一
-
Python使用爬虫爬取贵阳房价的方法详解
目录 1 序言 1.1 生存压力带来的哲思 1.2 买房&房奴 2 爬虫 2.1 基本概念 2.2 爬虫的基本流程 3 爬取贵阳房价并写入表格 3.1 结果展示 3.2 代码实现(Python) 总结 1 序言 1.1 生存压力带来的哲思 马尔萨斯最早发现,生物按照几何级数高度增殖的天赋能力,总是大于他们的实际生存能力或现实生存群量,依次推想,生物的种内竞争一定是极端残酷且无可避免.姑且不论马尔萨斯是否有必要给人类提出相应的警告,仅是这一现象中隐含的一系列基础问题,譬如,生物的超量繁殖能力的自然
-
微信小程序 页面跳转传递值几种方法详解
微信小程序 页面跳转传递值 微信小程序导航有两种形式:一种是在写在js中进行跳转,另一种是写在wxml页面中进行跳转. 1.js导航 (1).wx.navigateTo(OBJECT) :保留当前页面,跳转到应用内的某个页面,使用wx.navigateBack可以返回到原页面. wx.navigateTo({ url: 'test?id=1' }) 获取传递的值: //test.js Page({ onLoad: function(option){ console.log(option.id)
-
Swift中非可选的可选值类型处理方法详解
前言 在我们使用objective-c表示字符串信息的时候,可以用下面方法书写. NSString *str = @"秋恨雪"; str = nil; 因为objective-c是弱类型语言,所以这里的str既可以是具体的字符串也可以是nil.但到了Swift中就不可以了,因为Swift是类型安全的语言,一个String类型的变量不可能既能是具体的字符串,又可以为nil(更严格的说String类型的内容只能是字符串).所以,在Swift中有了可选类型的概念.(其实这一概念也是"