C#使用Selenium+PhantomJS抓取数据
手头项目需要抓取一个用js渲染出来的网站中的数据。使用常用的httpclient抓回来的页面是没有数据。上网百度了一下,大家推荐的方案是使用PhantomJS。PhantomJS是一个没有界面的webkit浏览器,能够和浏览器效果一致的使用js渲染页面。Selenium是一个web测试框架。使用Selenium来操作PhantomJS绝配。但是网上的例子多是Python的。无奈,下载了python按照教程搞了一下,卡在了Selenium的导入问题上。遂放弃,还是用自己惯用的c#吧,就不信c#上没有。经过半个小时的折腾,搞定(python折腾了一个小时)。记录下这篇博文,让我等搞c#的新手能用上PhantomJS。
第一步:打开visual studio 2017 新建一个控制台项目,打开nuget包管理器。
第二部:搜索Selenium,安装Selenium.WebDriver。注意:如果要使用代理的话最好安装3.0.0版本。
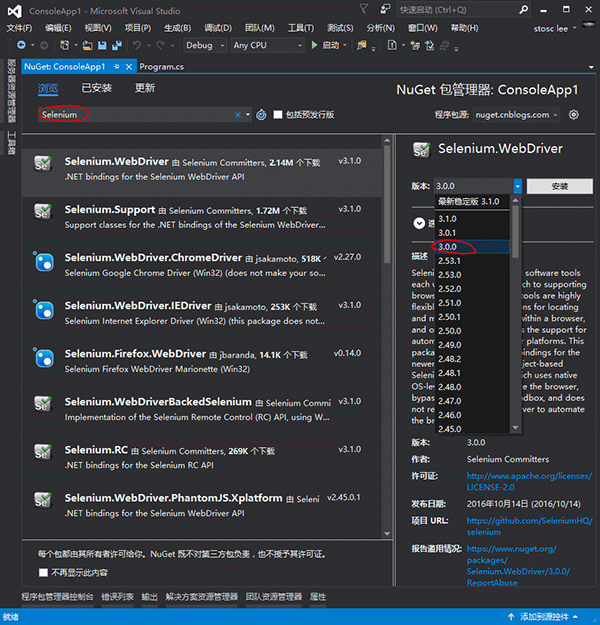
第三步:写下如下图所示的代码。但是执行的时候会报错。原因是找不到PhantomJS.exe。这时候可以去下载一个,也可以继续看第四步。
using OpenQA.Selenium;
using OpenQA.Selenium.PhantomJS;
using System;
namespace ConsoleApp1
{
class Program
{
static void Main(string[] args)
{
var url = "http://www.baidu.com";
IWebDriver driver = new PhantomJSDriver(GetPhantomJSDriverService());
driver.Navigate().GoToUrl(url);
Console.WriteLine(driver.PageSource);
Console.Read();
}
private static PhantomJSDriverService GetPhantomJSDriverService()
{
PhantomJSDriverService pds = PhantomJSDriverService.CreateDefaultService();
//设置代理服务器地址
//pds.Proxy = $"{ip}:{port}";
//设置代理服务器认证信息
//pds.ProxyAuthentication = GetProxyAuthorization();
return pds;
}
}
}
第四步:打开nuget安装Selenium.PhantomJS.WebDriver包。

第五步:运行。可以看到phantomjs.exe被自动下载了。
好了,这样就可以开始你的数据抓取大业了。
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持我们!
相关推荐
-
c#远程html数据抓取实例分享
复制代码 代码如下: /// <summary> /// 获取远程html /// </summary> /// <param name="url"></param> /// <param name="methed"></param> /// <param name="param"></p
-
c# 抓取Web网页数据分析
为了完成以上的需求,我们就需要模拟浏览器浏览网页,得到页面的数据在进行分析,最后把分析的结构,即整理好的数据写入数据库.那么我们的思路就是: 1.发送HttpRequest请求. 2.接收HttpResponse返回的结果.得到特定页面的html源文件. 3.取出包含数据的那一部分源码. 4.根据html源码生成HtmlDocument,循环取出数据. 5.写入数据库. 程序如下: 复制代码 代码如下: //根据Url地址得到网页的html源码 private string GetWebCont
-
C#抓取网页数据 解析标题描述图片等信息 去除HTML标签
一.首先将网页内容整个抓取下来,数据放在byte[]中(网络上传输时形式是byte),进一步转化为String,以便于对其操作,实例如下: 复制代码 代码如下: private static string GetPageData(string url) { if (url == null || url.Trim() == "") return null; WebClient wc = new WebClient(); wc.Credentials
-

C#使用Selenium+PhantomJS抓取数据
手头项目需要抓取一个用js渲染出来的网站中的数据.使用常用的httpclient抓回来的页面是没有数据.上网百度了一下,大家推荐的方案是使用PhantomJS.PhantomJS是一个没有界面的webkit浏览器,能够和浏览器效果一致的使用js渲染页面.Selenium是一个web测试框架.使用Selenium来操作PhantomJS绝配.但是网上的例子多是Python的.无奈,下载了python按照教程搞了一下,卡在了Selenium的导入问题上.遂放弃,还是用自己惯用的c#吧,就不信c#上没
-
python+selenium+PhantomJS抓取网页动态加载内容
环境搭建 准备工具:pyton3.5,selenium,phantomjs 我的电脑里面已经装好了python3.5 安装Selenium pip3 install selenium 安装Phantomjs 按照系统环境下载phantomjs,下载完成之后,将phantomjs.exe解压到python的script文件夹下 使用selenium+phantomjs实现简单爬虫 from selenium import webdriver driver = webdriver.PhantomJS
-
Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1.引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一部分实验了用xslt方式一次性提取静态网页内容并转换成xml格式.留下了一个问题:javascript管理的动态内容怎样提取?那么本文就回答这个问题. 2.提取动态内容的技术部件 在上一篇python使用xslt提取网页数据中,要提取的内容是直接从网页的source code里拿到的.但是一些Aja
-
利用selenium爬虫抓取数据的基础教程
写在前面 本来这篇文章该几个月前写的,后来忙着忙着就给忘记了. ps:事多有时候反倒会耽误事. 几个月前,记得群里一朋友说想用selenium去爬数据,关于爬数据,一般是模拟访问某些固定网站,将自己关注的信息进行爬取,然后再将爬出的数据进行处理. 他的需求是将文章直接导入到富文本编辑器去发布,其实这也是爬虫中的一种. 其实这也并不难,就是UI自动化的过程,下面让我们开始吧. 准备工具/原料 1.java语言 2.IDEA开发工具 3.jdk1.8 4.selenium-server-standa
-
selenium+PhantomJS爬取豆瓣读书
本文实例为大家分享了selenium+PhantomJS爬取豆瓣读书的具体代码,供大家参考,具体内容如下 获取关于Python的全部书籍信息: 通过代码测试 request携带'User-Agent'及 'data'数据信息的方式均无法获取到相关信息,获取数据时,部分数据为空,导致获取过程中报错,无法获取全部数据,初步判定豆瓣读书的反爬机制较为严格:通过selenium 模拟浏览器请求的方法测试后发现,可利用 selenium 方法请求获取数据: #导入需要的模块 from selenium i
-
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站.如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据. 如何通过selenium请求url,而不再通过下载器Downloader去请求这个url? 方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎.过程中相当于后续中间件的process_req
-
php使用curl代理实现抓取数据的方法
本文实例讲述了php使用curl代理实现抓取数据的方法.分享给大家供大家参考,具体如下: <?php define ( 'IS_PROXY', true ); //是否启用代理 function async_get_url($url_array, $wait_usec = 0) { if (!is_array($url_array)) return false; $wait_usec = intval($wait_usec); $data = array(); $handle = array()
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass
-
php通过curl添加cookie伪造登陆抓取数据的方法
本文实例讲述了php通过curl添加cookie伪造登陆抓取数据的方法.分享给大家供大家参考,具体如下: 有的网页必须登陆才能看到,这个时候想要抓取信息必须在header里面传递cookie值才能获取 1.首先登陆网站,打开firebug就能看到对应的cookie把这些cookie拷贝出来就能使用了 2. <?php header("Content-type:text/html;Charset=utf8"); $ch =curl_init(); curl_setopt($ch,C
-
Java模拟新浪微博登陆抓取数据
前言: 兄弟们来了来了,最近有人在问如何模拟新浪微博登陆抓取数据,我听后默默地抽了一口老烟,暗暗的对自己说,老汉是时候该你出场了,所以今天有时间就整理整理,浅谈一二. 首先: 要想登陆新浪微博需要预登陆,即是将账号base64加密,密码rsa加密以及请求http://login.sina.com.cn/sso/prelogin.php链接获取一些登陆需要参数,返回的接送字符串如: {"retcode":0,"servertime":1487292003,"