python多进程和多线程究竟谁更快(详解)
python3.6
threading和multiprocessing
四核+三星250G-850-SSD
自从用多进程和多线程进行编程,一致没搞懂到底谁更快。网上很多都说python多进程更快,因为GIL(全局解释器锁)。但是我在写代码的时候,测试时间却是多线程更快,所以这到底是怎么回事?最近再做分词工作,原来的代码速度太慢,想提速,所以来探求一下有效方法(文末有代码和效果图)
这里先来一张程序的结果图,说明线程和进程谁更快

一些定义
并行是指两个或者多个事件在同一时刻发生。并发是指两个或多个事件在同一时间间隔内发生
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一个程序的执行实例就是一个进程。
实现过程
而python里面的多线程显然得拿到GIL,执行code,最后释放GIL。所以由于GIL,多线程的时候拿不到,实际上,它是并发实现,即多个事件,在同一时间间隔内发生。
但进程有独立GIL,所以可以并行实现。因此,针对多核CPU,理论上采用多进程更能有效利用资源。
现实问题
在网上的教程里面,经常能见到python多线程的身影。比如网络爬虫的教程、端口扫描的教程。
这里拿端口扫描来说,大家可以用多进程实现下面的脚本,会发现python多进程更快。那么不就是和我们分析相悖了吗?
import sys,threading
from socket import *
host = "127.0.0.1" if len(sys.argv)==1 else sys.argv[1]
portList = [i for i in range(1,1000)]
scanList = []
lock = threading.Lock()
print('Please waiting... From ',host)
def scanPort(port):
try:
tcp = socket(AF_INET,SOCK_STREAM)
tcp.connect((host,port))
except:
pass
else:
if lock.acquire():
print('[+]port',port,'open')
lock.release()
finally:
tcp.close()
for p in portList:
t = threading.Thread(target=scanPort,args=(p,))
scanList.append(t)
for i in range(len(portList)):
scanList[i].start()
for i in range(len(portList)):
scanList[i].join()
谁更快
因为python锁的问题,线程进行锁竞争、切换线程,会消耗资源。所以,大胆猜测一下:
在CPU密集型任务下,多进程更快,或者说效果更好;而IO密集型,多线程能有效提高效率。
大家看一下下面的代码:
import time
import threading
import multiprocessing
max_process = 4
max_thread = max_process
def fun(n,n2):
#cpu密集型
for i in range(0,n):
for j in range(0,(int)(n*n*n*n2)):
t = i*j
def thread_main(n2):
thread_list = []
for i in range(0,max_thread):
t = threading.Thread(target=fun,args=(50,n2))
thread_list.append(t)
start = time.time()
print(' [+] much thread start')
for i in thread_list:
i.start()
for i in thread_list:
i.join()
print(' [-] much thread use ',time.time()-start,'s')
def process_main(n2):
p = multiprocessing.Pool(max_process)
for i in range(0,max_process):
p.apply_async(func = fun,args=(50,n2))
start = time.time()
print(' [+] much process start')
p.close()#关闭进程池
p.join()#等待所有子进程完毕
print(' [-] much process use ',time.time()-start,'s')
if __name__=='__main__':
print("[++]When n=50,n2=0.1:")
thread_main(0.1)
process_main(0.1)
print("[++]When n=50,n2=1:")
thread_main(1)
process_main(1)
print("[++]When n=50,n2=10:")
thread_main(10)
process_main(10)
结果如下:
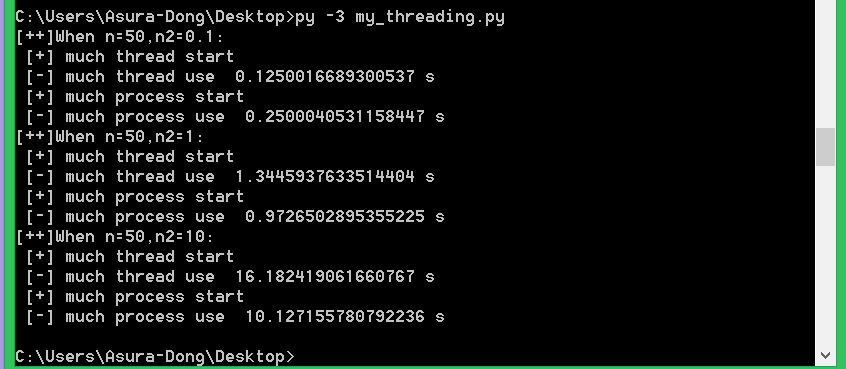
可以看出来,当对cpu使用率越来越高的时候(代码循环越多的时候),差距越来越大。验证我们猜想
CPU和IO密集型
1、CPU密集型代码(各种循环处理、计数等等)
2、IO密集型代码(文件处理、网络爬虫等)
判断方法:
1、直接看CPU占用率, 硬盘IO读写速度
2、计算较多->CPU;时间等待较多(如网络爬虫)->IO
3、请自行百度
以上这篇python多进程和多线程究竟谁更快(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python 爬虫图片简单实现
Python 爬虫图片简单实现 经常在逛知乎,有时候希望把一些问题的图片集中保存起来.于是就有了这个程序.这是一个非常简单的图片爬虫程序,只能爬取已经刷出来的部分的图片.由于对这一部分内容不太熟悉,所以只是简单说几句然后记录代码,不做过多的讲解.感兴趣的可以直接拿去用.亲测对于知乎等网站是可用的. 上一篇分享了通过url打开图片的方法,目的就是先看看爬取到的图片时什么样,然后再筛选一下保存. 这里用到了requests库来获取页面信息,需要注意的是,获取页面信息的时候需要一个header,用以把
-
python数据类型_字符串常用操作(详解)
这次主要介绍字符串常用操作方法及例子 1.python字符串 在python中声明一个字符串,通常有三种方法:在它的两边加上单引号.双引号或者三引号,如下: name = 'hello' name1 = "hello bei jing " name2 = '''hello shang hai haha''' python中的字符串一旦声明,是不能进行更改的,如下: #字符串为不可变变量,即不能通过对某一位置重新赋值改变内容 name = 'hello' name[0] = 'k' #通
-

详解python的webrtc库实现语音端点检测
引言 语音端点检测最早应用于电话传输和检测系统当中,用于通信信道的时间分配,提高传输线路的利用效率.端点检测属于语音处理系统的前端操作,在语音检测领域意义重大. 但是目前的语音端点检测,尤其是检测 人声 开始和结束的端点始终是属于技术难点,各家公司始终处于 能判断,但是不敢保证 判别准确性 的阶段. 现在基于云端语义库的聊天机器人层出不穷,其中最著名的当属amazon的 Alexa/Echo 智能音箱. 国内如雨后春笋般出现了各种搭载语音聊天的智能音箱(如前几天在知乎上广告的若琪机器人)和各类智
-
python读取二进制mnist实例详解
python读取二进制mnist实例详解 training data 数据结构: <br>[offset] [type] [value] [description] 0000 32 bit integer 0x00000803(2051) magic number 0004 32 bit integer 60000 number of images 0008 32 bit integer 28 number of rows 0012 32 bit integer 28 number of co
-
python 内置函数filter
python 内置函数filter class filter(object): """ filter(function or None, iterable) --> filter object Return an iterator yielding those items of iterable for which function(item) is true. If function is None, return the items that are true. &
-
Python 稀疏矩阵-sparse 存储和转换
稀疏矩阵-sparsep from scipy import sparse 稀疏矩阵的储存形式 在科学与工程领域中求解线性模型时经常出现许多大型的矩阵,这些矩阵中大部分的元素都为0,被称为稀疏矩阵.用NumPy的ndarray数组保存这样的矩阵,将很浪费内存,由于矩阵的稀疏特性,可以通过只保存非零元素的相关信息,从而节约内存的使用.此外,针对这种特殊结构的矩阵编写运算函数,也可以提高矩阵的运算速度. scipy.sparse库中提供了多种表示稀疏矩阵的格式,每种格式都有不同的用处,其中dok_m
-
Python 通过URL打开图片实例详解
Python 通过URL打开图片实例详解 不论是用OpenCV还是PIL,skimage等库,在之前做图像处理的时候,几乎都是读取本地的图片.最近尝试爬虫爬取图片,在保存之前,我希望能先快速浏览一遍图片,然后有选择性的保存.这里就需要从url读取图片了.查了很多资料,发现有这么几种方法,这里做个记录. 本文用到的图片URL如下: img_src = 'http://wx2.sinaimg.cn/mw690/ac38503ely1fesz8m0ov6j20qo140dix.jpg' 1.用Open
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python多进程和多线程究竟谁更快(详解)
python3.6 threading和multiprocessing 四核+三星250G-850-SSD 自从用多进程和多线程进行编程,一致没搞懂到底谁更快.网上很多都说python多进程更快,因为GIL(全局解释器锁).但是我在写代码的时候,测试时间却是多线程更快,所以这到底是怎么回事?最近再做分词工作,原来的代码速度太慢,想提速,所以来探求一下有效方法(文末有代码和效果图) 这里先来一张程序的结果图,说明线程和进程谁更快 一些定义 并行是指两个或者多个事件在同一时刻发生.并发是指两个或多个
-
Python异步爬虫多线程与线程池示例详解
目录 背景 异步爬虫方式 多线程,多进程(不建议) 线程池,进程池(适当使用) 单线程+异步协程(推荐) 多线程 线程池 背景 当对多个url发送请求时,只有请求完第一个url才会接着请求第二个url(requests是一个阻塞的操作),存在等待的时间,这样效率是很低的.那我们能不能在发送请求等待的时候,为其单独开启进程或者线程,继续请求下一个url,执行并行请求 异步爬虫方式 多线程,多进程(不建议) 好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步会执行 弊端:不能无限制开
-
python多进程中的生产者和消费者模型详解
目录 Python生产者消费者模型 一.消费模式 二.传输原理 三.实现方式 Python生产者消费者模型 一.消费模式 生产者消费者模式 是Controlnet网络中特有的一种传输数据的模式.用于两个CPU之间传输数据,即使是不同类型同一厂家的CPU也可以通过设置来使用. 二.传输原理 类似与点对点传送,又略有不同,一个生产者可以对应N个消费者,但是一个消费者只能对应一个生产者: 每个生产者消费者对应一个地址,占一个网络节点,属于预定性数据,在网络中优先级最高: 此模式如果在网络中设置过多会影
-
Python多进程入门、分布式进程数据共享实例详解
本文实例讲述了Python多进程入门.分布式进程数据共享.分享给大家供大家参考,具体如下: python多进程入门 https://docs.python.org/3/library/multiprocessing.html 1.先来个简单的 # coding: utf-8 from multiprocessing import Process # 定义函数 def addUser(): print("addUser") if __name__ == "__main__&qu
-
python 多进程和多线程使用详解
进程和线程 进程是系统进行资源分配的最小单位,线程是系统进行调度执行的最小单位: 一个应用程序至少包含一个进程,一个进程至少包含一个线程: 每个进程在执行过程中拥有独立的内存空间,而一个进程中的线程之间是共享该进程的内存空间的: 计算机的核心是CPU,它承担了所有的计算任务.它就像一座工厂,时刻在运行. 假定工厂的电力有限,一次只能供给一个车间使用.也就是说,一个车间开工的时候,其他车间都必须停工.背后的含义就是,单个CPU一次只能运行一个任务.编者注: 多核的CPU就像有了多个发电厂,使多工厂
-
Python多进程与多线程的使用场景详解
前言 Python多进程适用的场景:计算密集型(CPU密集型)任务 Python多线程适用的场景:IO密集型任务 计算密集型任务一般指需要做大量的逻辑运算,比如上亿次的加减乘除,使用多核CPU可以并发提高计算性能. IO密集型任务一般指输入输出型,比如文件的读取,或者网络的请求,这类场景一般会遇到IO阻塞,使用多核CPU来执行并不会有太高的性能提升. 下面使用一台64核的虚拟机来执行任务,通过示例代码来区别它们, 示例1:执行计算密集型任务,进行1亿次运算 使用多进程 from multipro
-
Python 多进程、多线程效率对比
Python 界有条不成文的准则: 计算密集型任务适合多进程,IO 密集型任务适合多线程.本篇来作个比较. 通常来说多线程相对于多进程有优势,因为创建一个进程开销比较大,然而因为在 python 中有 GIL 这把大锁的存在,导致执行计算密集型任务时多线程实际只能是单线程.而且由于线程之间切换的开销导致多线程往往比实际的单线程还要慢,所以在 python 中计算密集型任务通常使用多进程,因为各个进程有各自独立的 GIL,互不干扰. 而在 IO 密集型任务中,CPU 时常处于等待状态,操作系统需要
-
python多进程和多线程介绍
目录 一.什么是进程和线程 二.多进程和多线程 三.python中的多进程和多线程 1.多进程 2.多线程 一.什么是进程和线程 进程是分配资源的最小单位,线程是系统调度的最小单位. 当应用程序运行时最少会开启一个进程,此时计算机会为这个进程开辟独立的内存空间,不同的进程享有不同的空间,而一个CPU在同一时刻只能够运行一个进程,其他进程处于等待状态. 一个进程内部包括一个或者多个线程,这些线程共享此进程的内存空间与资源.相当于把一个任务又细分成若干个子任务,每个线程对应一个子任务. 二.多进程和
-
对python多线程SSH登录并发脚本详解
测试系统中有一项记录ssh登录日志,需要对此进行并发压力测试. 于是用多线程进行python并发记录 因为需要安装的一些依赖和模块比较麻烦,脚本完成后再用pyinstaller打成exe包分发给其他测试人员一起使用. 1.脚本编写 # -*- coding: utf-8 -*- import paramiko import threading import time lt = [] def ssh(a,xh,sp): count = 0 for i in range(0,xh): try: ss
-
Python多线程编程之threading模块详解
一.介绍 线程是什么?线程有啥用?线程和进程的区别是什么? 线程是操作系统能够进行运算调度的最小单位.被包含在进程中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务. 二.Python如何创建线程 2.1 方法一: 创建Thread对象 步骤: 1.目标函数 2.实例化Thread对象 3.调用start()方法 import threading # 目标函数1 def fun1(num): for i in range(