详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤
pycharm是无法创建一个scrapy项目的

因此,我们需要用命令行的方法新建一个scrapy项目
请确保已经安装了scrapy,twisted,pypiwin32
一:进入你所需要的路径,这个路径存储你创建的项目
我的将放在E盘的Scrapy目录下
二:创建项目:scrapy startproject ***(这个是项目名)

这样就创建好了一个名为tencent的项目
三:进入项目新建一个爬虫:scrapy genspider tencent_spider hr.tencent.com
这里我们要注意,上面的命令,加黑的是爬虫名称,斜体是域名

这样,我们就新建了一个爬虫项目,打开文件夹查看
打开spiders

然后我们用pycharm打开

点击File —>open,找到项目所在文件夹,打开即可
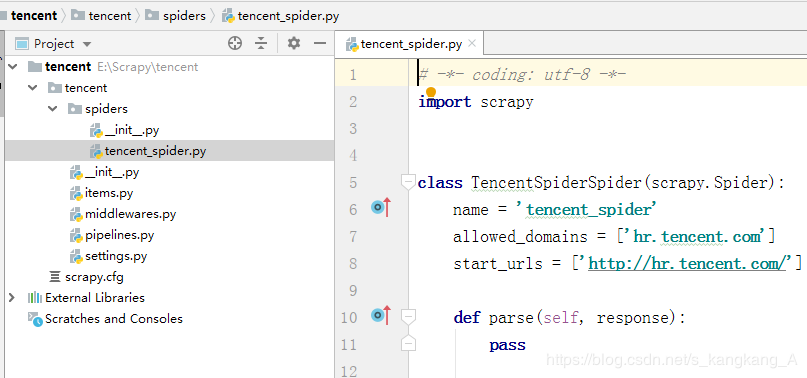
这样,我们就新建了一个scrapy项目,如果安装了所需要的库,scrapy飘红,记得去切换解释器
在File—>settings的标红的地方
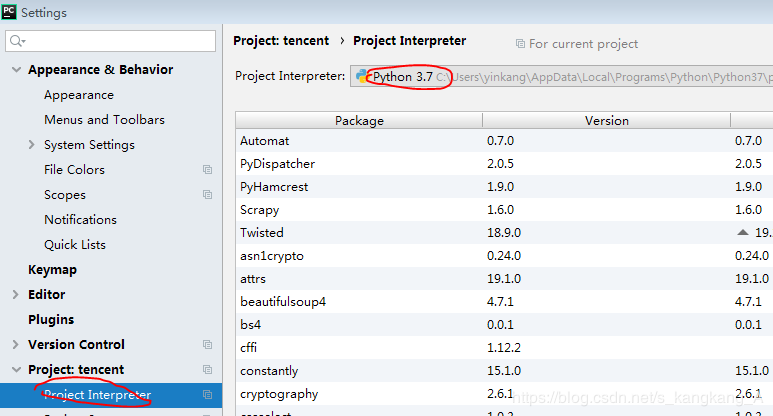
另外推荐大家,在根目录下新建一个start.py的文件并写入
from scrapy import cmdline
cmdline.execute("scrapy crawl tencent_spider".split())
这样,我们每次运行,运行start.py,即可,不用到命令行执行运行命令
鼠标右键tencent,新建python文件,即可创建。
以上所述是小编给大家介绍的python3 Scrapy爬虫创建项目详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-

一步步教你用python的scrapy编写一个爬虫
介绍 本文将介绍我是如何在python爬虫里面一步一步踩坑,然后慢慢走出来的,期间碰到的所有问题我都会详细说明,让大家以后碰到这些问题时能够快速确定问题的来源,后面的代码只是贴出了核心代码,更详细的代码暂时没有贴出来. 流程一览 首先我是想爬某个网站上面的所有文章内容,但是由于之前没有做过爬虫(也不知道到底那个语言最方便),所以这里想到了是用python来做一个爬虫(毕竟人家的名字都带有爬虫的含义
-
python scrapy爬虫代码及填坑
涉及到详情页爬取 目录结构: kaoshi_bqg.py import scrapy from scrapy.spiders import Rule from scrapy.linkextractors import LinkExtractor from ..items import BookBQGItem class KaoshiBqgSpider(scrapy.Spider): name = 'kaoshi_bqg' allowed_domains = ['biquge5200.cc'] s
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
Python3环境安装Scrapy爬虫框架过程及常见错误
Windows •安装lxml 最好的安装方式是通过wheel文件来安装,http://www.lfd.uci.edu/~gohlke/pythonlibs/,从该网站找到lxml的相关文件.假如是Python3.5版本,WIndows 64位系统,那就找到lxml‑3.7.2‑cp35‑cp35m‑win_amd64.whl 这个文件并下载,然后通过pip安装. 下载之后,运行如下命令安装: pip3 install wheel pip3 install lxml‑3.7.2‑cp35‑cp3
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
浅析python实现scrapy定时执行爬虫
项目需要程序能够放在超算中心定时运行,于是针对scrapy写了一个定时爬虫的程序main.py ,直接放在scrapy的存储代码的目录中就能设定时间定时多次执行. 最简单的方法:直接使用Timer类 import time import os while True: os.system("scrapy crawl News") time.sleep(86400) #每隔一天运行一次 24*60*60=86400s或者,使用标准库的sched模块 import sched #初始化sch
-
详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy,twisted,pypiwin32 一:进入你所需要的路径,这个路径存储你创建的项目 我的将放在E盘的Scrapy目录下 二:创建项目:scrapy startproject ***(这个是项目名) 这样就创建好了一个名为tencent的项目 三:进入项目新建一个爬虫:
-
详解Python3网络爬虫(二):利用urllib.urlopen向有道翻译发送数据获得翻译结果
上一篇内容,已经学会了使用简单的语句对网页进行抓取.接下来,详细看下urlopen的两个重要参数url和data,学习如何发送数据data 一.urlopen的url参数 Agent url不仅可以是一个字符串,例如:http://www.baidu.com.url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为urlopen的参数使用,方法如下: # -*- coding: UTF-8 -*- from urllib import re
-
详解Python的爬虫框架 Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程(注:图片来自互联网). 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎
-
Python 详解通过Scrapy框架实现爬取CSDN全站热榜标题热词流程
目录 前言 环境部署 实现过程 创建项目 定义Item实体 关键词提取工具 爬虫构造 中间件代码构造 制作自定义pipeline settings配置 执行主程序 执行结果 总结 前言 接着我的上一篇:Python 详解爬取并统计CSDN全站热榜标题关键词词频流程 我换成Scrapy架构也实现了一遍.获取页面源码底层原理是一样的,Scrapy架构更系统一些.下面我会把需要注意的问题,也说明一下. 提供一下GitHub仓库地址:github本项目地址 环境部署 scrapy安装 pip insta
-
Python 详解通过Scrapy框架实现爬取百度新冠疫情数据流程
目录 前言 环境部署 插件推荐 爬虫目标 项目创建 webdriver部署 项目代码 Item定义 中间件定义 定义爬虫 pipeline输出结果文本 配置文件改动 验证结果 总结 前言 闲来无聊,写了一个爬虫程序获取百度疫情数据.申明一下,研究而已.而且页面应该会进程做反爬处理,可能需要调整对应xpath. Github仓库地址:代码仓库 本文主要使用的是scrapy框架. 环境部署 主要简单推荐一下 插件推荐 这里先推荐一个Google Chrome的扩展插件xpath helper,可以验
-
详解Python3 pandas.merge用法
摘要 数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载.清理.转换以及重塑.pandas提供了一组高级的.灵活的.高效的核心函数,能够轻松的将数据规整化.这节主要对pandas合并数据集的merge函数进行详解.(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉.)码字不易,喜欢请点赞!!! 1.merge函数的参数一览表 2.创建两个DataFrame 3.pd.merge()方法设置连接字段. 默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于o
-
python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
详解用Python爬虫获取百度企业信用中企业基本信息
一.背景 希望根据企业名称查询其经纬度,所在的省份.城市等信息.直接将企业名称传给百度地图提供的API,得到的经纬度是非常不准确的,因此希望获取企业完整的地理位置,这样传给API后结果会更加准确. 百度企业信用提供了企业基本信息查询的功能.希望通过Python爬虫获取企业基本信息.目前已基本实现了这一需求. 本文最后会提供具体的代码.代码仅供学习参考,希望不要恶意爬取数据! 二.分析 以苏宁为例.输入"江苏苏宁"后,查询结果如下: 经过分析,这里列示的企业信息是用JavaScript动
-
详解基于Scrapy的IP代理池搭建
一.为什么要搭建爬虫代理池 在众多的网站防爬措施中,有一种是根据ip的访问频率进行限制,即在某一时间段内,当某个ip的访问次数达到一定的阀值时,该ip就会被拉黑.在一段时间内禁止访问. 应对的方法有两种: 1. 降低爬虫的爬取频率,避免IP被限制访问,缺点显而易见:会大大降低爬取的效率. 2. 搭建一个IP代理池,使用不同的IP轮流进行爬取. 二.搭建思路 1.从代理网站(如:西刺代理.快代理.云代理.无忧代理)爬取代理IP: 2.验证代理IP的可用性(使用代理IP去请求指定URL,根据响应验证
-
详解Python3.8+PyQt5+pyqt5-tools+Pycharm配置详细教程
个人使用环境 WIN10x64系统,Python3.8,PyCharm2020.01.03 安装过程 一.安装Python3.8 (自己参考其他教程) 二.安装PyQt5 然后在cmd下输入指令 pip install PyQt5 也可以输入这个指令 pip install PyQt5 -i https://pypi.douban.com/simple (后面是豆瓣的镜像地址,是为了加快下载速度) 提示你更新pip,就按照提示更新(这步骤是可选的,看个人需求) 在cmd下输入 python -m