C# TrieTree介绍及实现方法
在自然语言处理(NLP)研究中,NGram是最基本但也是最有用的一种比对方式,这里的N是需要比对的字符串的长度,而今天我介绍的TrieTree,正是和NGram密切相关的一种数据结构,有人称之为字典树。TrieTree简单的说是一种多叉树,每个节点保存一个字符,这么做的好处是当我们要做NGram比对时,只需要直接从树的根节点开始沿着某个树叉遍历下去,就能完成比对;如果没找到,停止本次遍历。这话讲得有些抽象,我们来看一个实际的例子。
假设我们现在词库里面有以下一些词:
上海市
上海滩
上海人
上海公司
北京
北斗星
杨柳
杨浦区
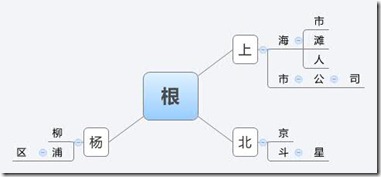
如图所示:挂在根节点上的字有上、北、杨,
如果我们现在对“上海市杨浦区”这个词做3gram就有上海市、海市杨、市杨浦、杨浦区,现在我们要知道哪些词是能够被这个字典识别的,通常我们可以用NGram来做分词。有了这颗树,我们只需要依次取每个字符,从根开始进行比对,比如上海市,我们能够匹配 上->海->市,这个路径,所以匹配;比如海市杨,由于没有“海”字挂在根节点上,所以停止;市杨浦也无法匹配;最终匹配杨浦区,得到 杨->浦->区 这个路径,匹配。
最终我们可以把“上海市杨浦区”切分为 上海市|杨浦区。
尽管TrieTree要比普通字符串数组节省很多时间,但这并不是没有代价的,因为你要先根据字典构建这棵树,这个代价并不低,当然对于某个应用来说一旦TrieTree构建完成就可以重复使用,所以针对大规模比对来说,性能提升还是很客观的。
下面是TrieTree的C#实现。
public class TrieTree
{
TrieNode _root = null;
private TrieTree()
{
_root = new TrieNode(char.MaxValue,0);
charCount = 0;
}
static TrieTree _instance = null;
public static TrieTree GetInstance()
{
if (_instance == null)
{
_instance = new TrieTree();
}
return _instance;
}
public TrieNode Root
{
get { return _root;
}
}
public void AddWord(char ch)
{
TrieNode newnode=_root.AddChild(ch);
newnode.IncreaseFrequency();
newnode.WordEnded = true;
} int charCount;
public void AddWord(string word)
{
if (word.Length == 1)
{
AddWord(word[0]);
charCount++;
}
else
{
char[] chars=word.ToCharArray();
TrieNode node = _root;
charCount += chars.Length;
for (int i = 0; i < chars.Length; i++)
{
TrieNode newnode=node.AddChild(chars[i]);
newnode.IncreaseFrequency();
node = newnode;
}
node.WordEnded = true;
}
}
public int GetFrequency(char ch)
{
TrieNode matchedNode = _root.Children.FirstOrDefault(n => n.Character == ch);
if (matchedNode == null)
{
return 0;
}
return matchedNode.Frequency;
}
public int GetFrequency(string word)
{
if (word.Length == 1)
{
return GetFrequency(word[0]);
}
else
{
char[] chars = word.ToCharArray();
TrieNode node = _root;
for (int i = 0; i < chars.Length; i++)
{
if (node.Children == null)
return 0;
TrieNode matchednode = node.Children.FirstOrDefault(n => n.Character == chars[i]);
if (matchednode == null)
{
return 0;
}
node = matchednode;
}
if (node.WordEnded == true)
return node.Frequency;
else
return -1;
}
}
}
这里我们使用了单例模式,因为TrieTree类似缓存,不需要重复创建。下面是TreeNode的实现:
public class TrieNode
{
public TrieNode(char ch,int depth)
{
this.Character=ch;
this._depth=depth;
}
public char Character;
int _depth;
public int Depth
{
get{return _depth;
}
}
TrieNode _parent=null;
public TrieNode Parent
{
get {
return _parent;
}
set { _parent = value;
}
}
public bool WordEnded = false;
HashSet<TrieNode> _children=null;
public HashSet<TrieNode> Children
{
get {
return _children;
}
}
public TrieNode GetChildNode(char ch)
{
if (_children != null)
return _children.FirstOrDefault(n => n.Character == ch);
else
return null;
}
public TrieNode AddChild(char ch)
{
TrieNode matchedNode=null;
if (_children != null)
{
matchedNode = _children.FirstOrDefault(n => n.Character == ch);
}
if (matchedNode != null)
//found the char in the list
{
//matchedNode.IncreaseFrequency();
return matchedNode;
}
else
{
//not found
TrieNode node = new TrieNode(ch, this.Depth + 1);
node.Parent = this;
//node.IncreaseFrequency();
if (_children == null)
_children = new HashSet<TrieNode>();
_children.Add(node);
return node;
}
}
int _frequency = 0;
public int Frequency
{
get { return _frequency;
}
}
public void IncreaseFrequency()
{
_frequency++;
}
public string GetWord()
{
TrieNode tmp=this;
string result = string.Empty;
while(tmp.Parent!=null) //until root node
{
result = tmp.Character + result;
tmp = tmp.Parent;
}
return result;
}
public override string ToString()
{
return Convert.ToString(this.Character);
}
}
相关推荐
-
详解字典树Trie结构及其Python代码实现
字典树(Trie)可以保存一些字符串->值的对应关系.基本上,它跟 Java 的 HashMap 功能相同,都是 key-value 映射,只不过 Trie 的 key 只能是字符串. Trie 的强大之处就在于它的时间复杂度.它的插入和查询时间复杂度都为 O(k) ,其中 k 为 key 的长度,与 Trie 中保存了多少个元素无关.Hash 表号称是 O(1) 的,但在计算 hash 的时候就肯定会是 O(k) ,而且还有碰撞之类的问题:Trie 的缺点是空间消耗很高. 至于Trie树的实现
-
Java中实现双数组Trie树实例
传统的Trie实现简单,但是占用的空间实在是难以接受,特别是当字符集不仅限于英文26个字符的时候,爆炸起来的空间根本无法接受. 双数组Trie就是优化了空间的Trie树,原理本文就不讲了,请参考An Efficient Implementation of Trie Structures,本程序的编写也是参考这篇论文的. 关于几点论文没有提及的细节和与论文不一一致的实现: 1.对于插入字符串,如果有一个字符串是另一个字符串的子串的话,我是将结束符也作为一条边,产生一个新的结点,这个结点新节点的Ba
-

TrieTree服务-组件构成及其作用介绍
上一篇中我们对TrieTree服务有了一个整体的了解,不知道大家下载完之后有没有真正玩过这个TrieTree服务,如果你还没有玩过,没关系,本文将一步步教你配置和使用TrieTree服务. TrieTree服务由几大组件组成,如下图 Dictionary组件是核心库,主要提供基本数据定义.配置信息定义,数据结构表示,同时也提供了POSType(参考Pangu的Part of Speech定义).由于TrieTree是利用内存来加载数据的,所以这个组件的设计直接决定了内存的占用大小和数据查询性能.
-
Python Trie树实现字典排序
一般语言都提供了按字典排序的API,比如跟微信公众平台对接时就需要用到字典排序.按字典排序有很多种算法,最容易想到的就是字符串搜索的方式,但这种方式实现起来很麻烦,性能也不太好.Trie树是一种很常用的树结构,它被广泛用于各个方面,比如字符串检索.中文分词.求字符串最长公共前缀和字典排序等等,而且在输入法中也能看到Trie树的身影. 什么是Trie树 Trie树通常又称为字典树.单词查找树或前缀树,是一种用于快速检索的多叉树结构.如图数字的字典是一个10叉树: 同理小写英文字母或大写英文字母的字
-
Trie树(字典树)的介绍及Java实现
简介 Trie树,又称为前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串.与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定.一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串. 它的主要特点如下: 根节点不包含字符,除根节点外的每一个节点都只包含一个字符. 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串. 每个节点的所有子节点包含的字符都不相同. 如下是一棵典型的Trie树: Trie的来源是Retrie
-
Trie树_字典树(字符串排序)简介及实现
1.综述 又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种.典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计.它的优点是:利用字符串的公共前缀来节约存储空间,最大限度地减少无谓的字符串比较,查询效率比哈希表高. Trie树结构的优点在于:1) 不限制子节点的数量: 2) 自定义的输入序列化,突破了具体语言.应用的限制,成为一个通用的框架: 3) 可以进行最大Tokens序列长度的限制:4) 根据已定阈值输出重复的字符串:5) 提
-
C# TrieTree介绍及实现方法
在自然语言处理(NLP)研究中,NGram是最基本但也是最有用的一种比对方式,这里的N是需要比对的字符串的长度,而今天我介绍的TrieTree,正是和NGram密切相关的一种数据结构,有人称之为字典树.TrieTree简单的说是一种多叉树,每个节点保存一个字符,这么做的好处是当我们要做NGram比对时,只需要直接从树的根节点开始沿着某个树叉遍历下去,就能完成比对:如果没找到,停止本次遍历.这话讲得有些抽象,我们来看一个实际的例子. 假设我们现在词库里面有以下一些词: 上海市 上海滩 上海人 上海
-
关于RequireJS的简单介绍即使用方法
RequireJS介绍 RequireJS 是一个JavaScript模块加载器.它非常适合在浏览器中使用.使用RequireJS加载模块化脚本将提高代码的加载速度和质量. 兼容性 浏览器(browser) 是否兼容 IE 6+ 兼容 ✔ Firefox 2+ 兼容 ✔ Safari 3.2+ 兼容 ✔ Chrome 3+ 兼容 ✔ Opera 10+ 兼容 ✔ 优点 实现js文件的异步加载,避免网页失去响应 管理模块之间的依赖性,便于代码的编写和维护 快速上手 step 1 引入require
-
详谈Java几种线程池类型介绍及使用方法
一.线程池使用场景 •单个任务处理时间短 •将需处理的任务数量大 二.使用Java线程池好处 1.使用new Thread()创建线程的弊端: •每次通过new Thread()创建对象性能不佳. •线程缺乏统一管理,可能无限制新建线程,相互之间竞争,及可能占用过多系统资源导致死机或oom. •缺乏更多功能,如定时执行.定期执行.线程中断. 2.使用Java线程池的好处: •重用存在的线程,减少对象创建.消亡的开销,提升性能. •可有效控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞
-
jquery.cookie.js的介绍与使用方法
什么是 cookie? cookie 就是页面用来保存信息,比如自动登录.记住用户名等等. cookie 的特点 同个网站中所有的页面共享一套 cookie cookie 有数量.大小限制 cookie 有过期时间jquery.cookie.js 是一款轻量级的 cookie 插件,可以读取,写入和删除 cookie.本文主要针对 jquery.cookie.js 的用法进行详细的介绍. 使用方法: 设置 cookie: $.cookie('the_cookie', 'the_value');
-
java 中的封装介绍及使用方法
java 中的封装介绍及使用方法 在面向对象程式设计方法中,封装(英语:Encapsulation)是指一种将抽象性函式接口的实现细节部份包装.隐藏起来的方法. 封装可以被认为是一个保护屏障,防止该类的代码和数据被外部类定义的代码随机访问. 要访问该类的代码和数据,必须通过严格的接口控制. 封装最主要的功能在于我们能修改自己的实现代码,而不用修改那些调用我们代码的程序片段. 适当的封装可以让程式码更容易理解与维护,也加强了程式码的安全性. 封装的优点 1. 良好的封装能够减少耦合. 2. 类内部
-
Java多线程atomic包介绍及使用方法
引言 Java从JDK1.5开始提供了java.util.concurrent.atomic包,方便程序员在多线程环境下,无锁的进行原子操作.原子变量的底层使用了处理器提供的原子指令,但是不同的CPU架构可能提供的原子指令不一样,也有可能需要某种形式的内部锁,所以该方法不能绝对保证线程不被阻塞. Atomic包介绍 在Atomic包里一共有12个类,四种原子更新方式,分别是原子更新基本类型,原子更新数组,原子更新引用和原子更新字段.Atomic包里的类基本都是使用Unsafe实现的包装类. 原子
-
JS操作XML中DTD介绍及使用方法分析
本文实例讲述了JS操作XML中DTD介绍及使用方法.分享给大家供大家参考,具体如下: 什么是DTD,为什么需要DTD? DTD为英文Document Type Definition,中文意思为"文档类型定义".DTD肩负着两重任务:一方面它帮助你编写合法的代码,另一方面它让浏览器正确地显示器代码. 一个HTML文档的基本结构可分为两个主要部分: <html> <head> 头部信息 </head> <body> 可视内容 </bod
-
Java中Arrays的介绍及使用方法示例
arrays介绍 java.util.Arrays是一个与数组相关的工具类,里面提供了大量的静态的方法,用来实现数组常见的操作. public static String toString(数组):将参数数组编程字符串(按照默认的格式:{元素1.元素2.元素3-}) public static Void sort(数组):按照默认升序(从小到大)对数组元素进行排序 备注: 1.如果是数值的话,sort默认按照升序从小到大 2.如果是字符串,sort按照字母升序排列 3.如果是自定义类型,那么自定
-
Java异常类型介绍及处理方法
前言: Java异常,大家都很熟悉.但是对于具体怎么分类的,JVM对其怎么处理的,代码中怎么处理的,应该怎么使用,底层怎么实现的等等,可能就会有些不是那么清晰.本文基于此详细捋一下异常类型,实现以及使用时应怎么注意. 一.异常实现及分类 先看下异常类的结构图 上图可以简单展示一下异常类实现结构图,当然上图不是所有的异常,用户自己也可以自定义异常实现.上图已经足够帮我们解释和理解异常实现了: 1.所有的异常都是从Throwable继承而来的,是所有异常的共同祖先. 2.Throwable有两个子类
-
Vuex详细介绍和使用方法
目录 一.什么是Vuex 二.运行机制 三.创建项目 1.使用脚手架搭建Vue项目 2.安装Vuex 3.启动项目 4.配置使用Vuex 4.1.创建store文件夹 4.2.配置全局使用store对象 四.Vuex核心概念 1.state 2.mutations 3.Getter 3.1.通过属性进行访问 3.2.通过辅助函数进行访问 4.Action 4.1.通过dispatch触发 4.2.通过辅助函数触发 5.Module 五.总结 1.核心概念 2.底层原理 一.什么是Vuex 官网解