MySQL redo死锁问题排查及解决过程分析
问题背景
周一上班,首先向同事了解了一下上周的测试情况,被告知在多实例场景下 MySQL Server hang 住,无法测试下去,原生版本不存在这个问题,而新版本上出现了这个问题,不禁心头一颤,心中不禁感到奇怪,还好现场环境还在,为排查问题提供了一个好的环境,随即便投入到紧张的问题排查过程当中。问题实例表现如下:
并发量为 384 的时候出现的问题;
MySQL 服务器无法执行事务相关的语句,即使简单的 select 语句也无法执行;
所有线程处于等待状态,无法 KILL。
现场环境的收集
首先,通过 pstack 工具获取当前问题实例的堆栈信息以便后面具体线程的查找 & 问题线程的定位:
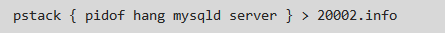
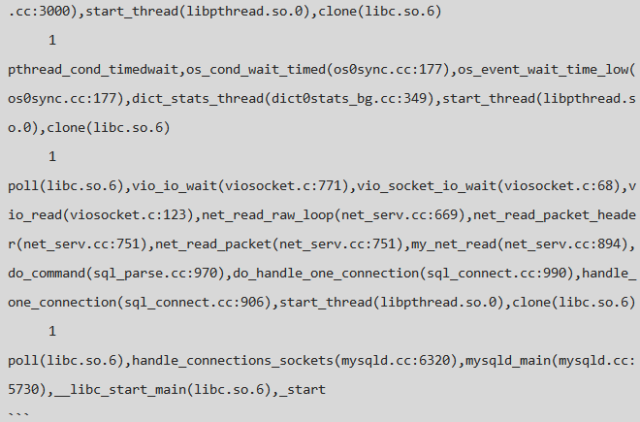
使用 pt-pmp 工具统计 hang.info 中的进程信息,如下:








问题分析
从堆栈上可以看出,有这样几类线程:
等待进入 INNODB engine 层的用户线程,测试环境中 innodb_thread_concurrency=16, 当 INNODB 层中的活跃线程数目大于此值时则需要排队,所以会有大量的排队线程,这个参数的影响&作用本身就是一篇很不错的文章,由于篇幅有限,在此不做扩展,感兴趣者可以参考官方文档:14.14 InnoDB Startup Options and System Variables;
操作过程中需要写 redo log 的后台线程,主要包括 page cleaner 线程、异步 io threads等;
正在读取Page页面的 purge 线程 & 操作 change buffer 的 master thread;
大量的需要写 redo log 的用户线程。
从以上的分类不难看出,所有需要写 redo log 的线程都在等待 log_sys->mutex,那么这个保护 redo log buffer 的 mutex 被究竟被哪个线程获取了呢,因此,我们可以顺着这个线索进行问题排查,需要解决以下问题:
问题一:哪个线程获取了 log_sys->mutex ?
问题二:获取 log_sys->mutex 的线程为什么没有继续执行下去,是在等其它锁还是其它原因?
问题三:如果不是硬件问题,整个资源竟争的过程是如何的?
1.问题一:由表及里
在查找 log_sys->mutex 所属线程情况时,有两点可以帮助我们快速的定位到这个线程:
由于 log_sys->mutex 同时只能被同一个线程获得,所以在 pt-pmp 的信息输出中就可以排除线程数目大于1的线程;
此线程既然已经获取了 log_sys->mutex, 那就应该还是在写日志的过程中,因此重点可以查看写日志的逻辑,即包括:mtr_log_reserve_and_write 或 log_write_up_to 的堆栈。
顺着上面的思路很快的从 pstack 中找到了以下线程:



这里我们简单介绍一下MySQL写 redo log 的过程(省略undo & buffer pool 部分),当对数据进行修改时,MySQL 会首先对针对操作类型记录不同的 redo 日志,主要过程是:
记录操作前的数据,根据不同的类型生成不同的 redo 日志,redo 的类型可以参考文件:src/storage/innobase/include/mtr0mtr.h 记录操作之后的数据,对于不同的类型会包含不同的内容,具体可以参考函数:recv_parse_or_apply_log_rec_body(); 写日志到 redo buffer,并将此次涉及到脏页的数据加入到 buffer_pool 的 flush list 链表中; 根据 innodb_flush_log_at_trx_commit 的值来判断在commit 的时候是否进行 sync 操作。
上面的堆栈则是写Redo后将脏页加到 flush list 过程中时 hang 住了,即此线程在获取了 log_sys->mutex 后,在获取 log_sys->log_flush_order_mutex 的过程中 hang 住了,而此时有大量的线程在等待该线程释放log_sys->mutex锁,问题一 已经有了答案,那么log_sys->log_flush_order_mutex 是个什么东东,它又被哪个占用了呢?
说明:
1、MySQL 的 buffer pool 维护了一个有序的脏页链表 (flush list according LSN order),这样在做 checkpoint & log_free_check 的过程中可以很快的定位到 redo log 需要推进的位置,在将脏页加入;
2、flush list 过程中需要对其上锁以保证 flush list 中 LSN 的有序性, 但是如果使用 log_sys->mutex,在并发量大的时候则会造成 log_sys->mutex 的 contention,进而引起性能问题,因此添加了另外一个 mutex 来保护脏页按 LSN 的有序性,代码说明如下:
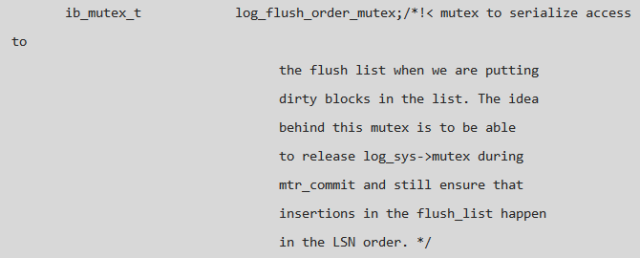
2.问题二:弹尽粮绝
在问题一的排查过程中我们确定了 log_sys->mutex 的所属线程, 这个线程在获得 log_sys->log_flush_order_mutex 的过程中 hang 住了,因此线程堆栈可以分以为下几类:
Thread 446, 获得 log_sys->mutex, 等待获取 log_sys->log_flush_order_mutex 以把脏页加入到 buffer_pool 的 flush list中; 需要获得 log_sys->mutex 以写日志或者读取日志信息的线程; 未知线程获得 log_sys->log_flush_order_mutex,在做其它事情的时候被 hang 住。
因此,问题的关键是找到哪个线程获取了 log_sys->log_flush_order_mutex。
为了找到相关的线程做了以下操作:
查找获取 log_sys->log_flush_order_mutex 的地方;
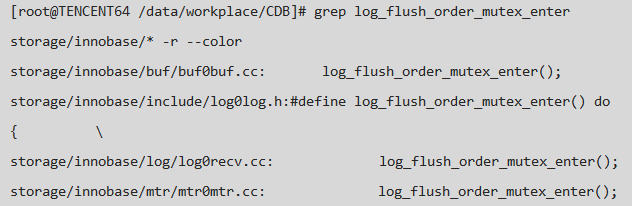
结合现有 pstack 中的线程信息,仔细查看上述查找结果中的相关代码,发现基本没有线程获得 log_sys->log_flush_order_mutex; gdb 进入 MySQL Server, 将 log_sys->log_flush_order_mutex 打印出来,发现 {waiters=1; lock_word= 0}!!!,即 Thread 446 在等待一个空闲的 mutex,而这个Mutex也确实被等待,由于我们的版本为 Release 版本,所以很多有用的信息没有办法得到,而若用 debug 版本跑则很难重现问题,log_flush_order_mutex 的定义如下:


由以上的分析可以得出 问题二 的答案:
只有两个线程和log_sys->log_flush_order_mutex有关,其中一个是 Thread 446 线程, 另外一个则是最近一次调用 log_flush_order_mutex_exit() 的线程; 现有线程中某个线程在释放log_sys->log_flush_order_mutex的过程中没有唤醒 Thread 446,导致Thread 446 hang 并造成其它线程不能获得 log_sys->mutex,进而造成实例不可用; log_sys->log_flush_order_mutex 没有被任何线程获得。 3.问题三:绝处逢生
由问题二的分析过程可知 log_sys->log_flush_order_mutex 没有被任何线程获得,可是为什么 Thread 446 没有被唤醒呢,信号丢失还是程序问题?如果是信号丢失,为什么可以稳定复现?官方的bug list 列表中是没有类似的 Bug的,搜了一下社区,发现可用信息很少,这个时候分析好像陷入了死胡同,心里压力开始无形中变大……好像没有办法,但是任何问题都是有原因的,找到了原因,也就是有解的了……再一次将注意力移到了 Thread 446 的堆栈中,然后查看了函数:

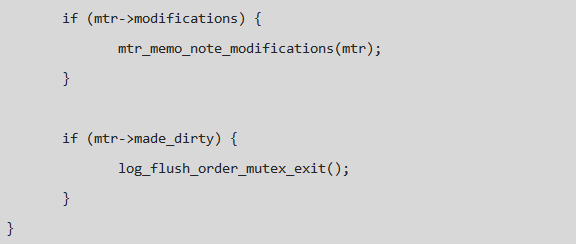
由问题二的分析过程可以得出某线程在 log_flush_order_mutex_exit 的退出过程没有将 Thread 446 唤醒,那么就顺着这个函数找,看它如何唤醒其它本程的,在没有办法的时候也只有这样一步一步的分析代码,希望有些收获,随着函数调用的不断深入,将目光定在了 mutex_exit_func 上, 函数中的注释引起了我的注意:


从上面的注释中可以得到两点信息:
由于 memory barrier 的存在,mutex_get_waiters & mutex_reset_lock_word 的调用顺序可能与执行顺序相反,这种情况下会引起 hang 问题; 专门写了一个函数 sync_arr_wake_threads_if_sema_free() 来解决上述问题。
由上面的注释可以看到,并不是信号丢失,而是多线程 memory barrier 的存在可能会造成指令执行的顺序的异常,这种问题确定存在,但既然有sync_arr_wake_threads_if_sema_free() 规避这个问题,为什么还会存在 hang 呢?有了这个线索,瞬间感觉有了些盼头……经过查找 sync_arr_wake_threads_if_sema_free 只在 srv_error_monitor_thread 有调用,这个线程是专门对 MySQL 内部异常情况进行监控并打印出 error 信息的线程,臭名昭著的 600S 自杀案也是它的杰作, 那么问题来了:
机器周末都在 hang 着,为什么没有检测到异常并 abort 呢? 既然 sync_arr_wake_threads_if_sema_free 可以唤醒,为什么没有唤醒呢?
顺着这个思路,查看了pstack 中 srv_error_monitor_thread 的堆栈,可以发现此线程在获取 log_sys->mutex 的时候hang 住了,因此无法执行sync_arr_wake_threads_if_sema_free() & 常归的异常检查,正好回答了上面的问题,详细堆栈如下:
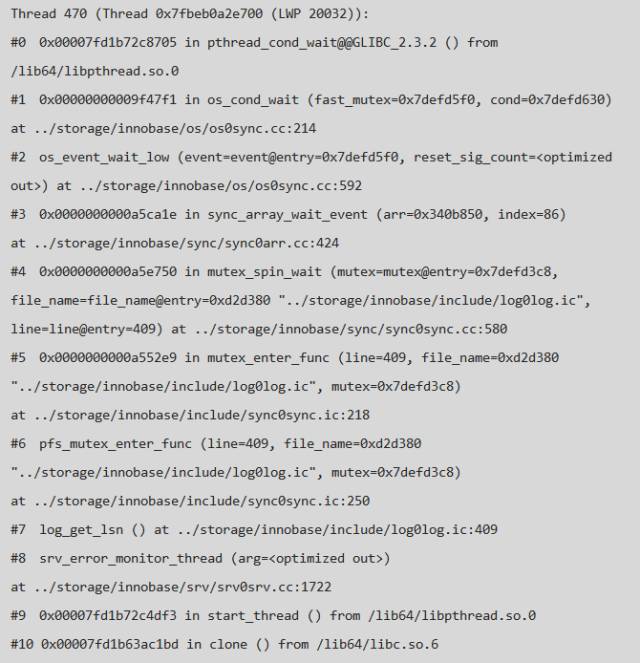
经过上面的分析问题越来越明朗了,过程可以简单的归结为:
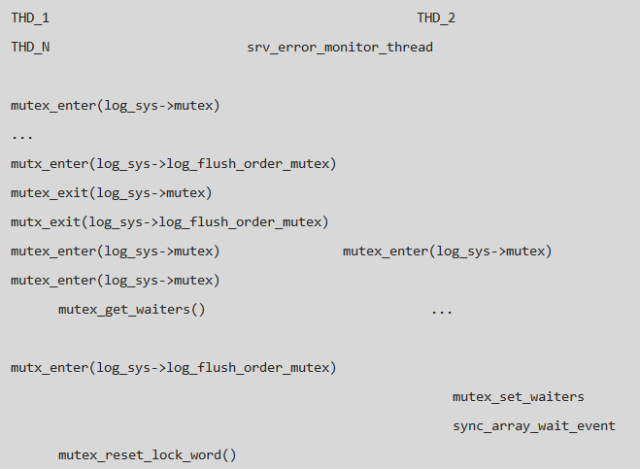
Thread 446 获得 log_sys->mutex, 但是在等待 log_sys->log_flush_order_mutex 的过程中没有被唤醒; Thread XXX 在释放 log_sys->log_flush_order_mutex 的过程中出现了 memory barrier 问题,没有唤醒 Thread 446; Thread 470 获得 log_sys->mutex 时被 hang 住,导致无法执行 sync_arr_wake_threads_if_sema_free(), 导致了整个实例的 hang 住; Thread 470 需要获得 Thread 446 的 log_sys->mutex, 而 Thread 446 需要被 Thread 470 唤醒才会释放 log_sys->mutex;
结合 log_sys->log_flush_order_mutex 的状态信息,实例 hang 住的整个过程如下:
关于 Memory barrier 的介绍可以参考 :
Memory barrierhttp://name5566.com/4535.html
问题解决
既然知道了问题产生的原因,那么问题也就可以顺利解决了,有两种方法:
直接移除 log_get_lsn 在此处的判断,本身就是开发人员加的一些判断信息,为了定位 LSN 的异常而写的,用到的时候也Crash了,用处不大; 保留判断,将 log_get_lsn 修改为 log_peek_lsn, 后者会首先进行 try_lock,当发现上锁失败的时候会直接返回,而不进行判断,这种方法较优雅些; 经过修改之后的版本在测试过程中没有没有再复现此问题。
问题扩展
虽然问题解决了,但官方版本中肯定存在着这个问题,为什么 buglist 没有找到相关信息呢,于是在查看了最新代码,发现这个问题已经修复,修复方法为上面列的第二种方法,详细的 commit message 信息如下:
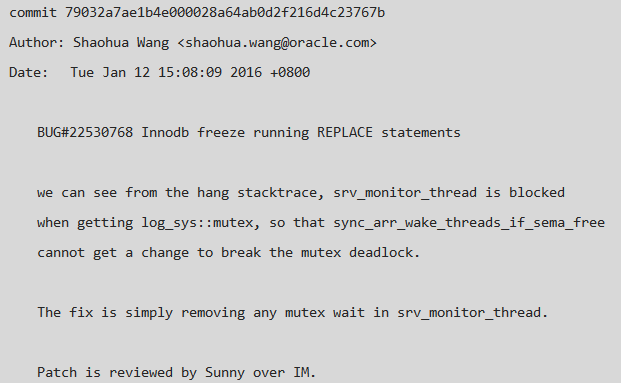
bug影响范围:MySQL 5.6.28 及之前的版本都有此问题。
相关推荐
-
一次Mysql死锁排查过程的全纪录
前言 之前接触到的数据库死锁,都是批量更新时加锁顺序不一致而导致的死锁,但是上周却遇到了一个很难理解的死锁.借着这个机会又重新学习了一下mysql的死锁知识以及常见的死锁场景.在多方调研以及和同事们的讨论下终于发现了这个死锁问题的成因,收获颇多.虽然是后端程序员,我们不需要像DBA一样深入地去分析与锁相关的源码,但是如果我们能够掌握基本的死锁排查方法,对我们的日常开发还是大有裨益的. PS:本文不会介绍死锁的基本知识,mysql的加锁原理可以参考本文的参考资料提供的链接. 死锁起因 先介绍一下数
-

MySQL Innodb表导致死锁日志情况分析与归纳
案例描述在定时脚本运行过程中,发现当备份表格的sql语句与删除该表部分数据的sql语句同时运行时,mysql会检测出死锁,并打印出日志.两个sql语句如下:(1)insert into backup_table select * from source_table(2)DELETE FROM source_table WHERE Id>5 AND titleWeight<32768 AND joinTime<'$daysago_1week'teamUser表的表结构如下:PRIMARY
-
MySQL死锁问题分析及解决方法实例详解
MySQL死锁问题是很多程序员在项目开发中常遇到的问题,现就MySQL死锁及解决方法详解如下: 1.MySQL常用存储引擎的锁机制 MyISAM和MEMORY采用表级锁(table-level locking) BDB采用页面锁(page-level locking)或表级锁,默认为页面锁 InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁 2.各种锁特点 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低 行级锁:开销大,加锁慢;
-
MySQL中由load data语句引起死锁的解决案例
一个线上项目报的死锁,简要说明一下产生原因.处理方案和相关的一些点. 1.背景 这是一个类似数据分析的项目,数据完全通过LOAD DATA语句导入一个InnoDB表中.为方便描述,表结构简化为如下: Create table tb(id int primary key auto_increment, c int not null) engine=innodb; 导入数据的语句对应为 Load data infile 'data1.csv' into table tb; Load data inf
-
详解MySQL中的死锁情况以及对死锁的处理方法
当多个事务同时持有和请求同一资源上的锁而产生循环依赖的时候就产生了死锁.死锁发生在事务试图以不同的顺序锁定资源.以StockPrice表上的两个事务为例: 事务1 START TRANSACTION; UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = '2002-05-01'; UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = '20
-
Mysql 行级锁的使用及死锁的预防方案
一.前言 mysql的InnoDB,支持事务和行级锁,可以使用行锁来处理用户提现等业务.使用mysql锁的时候有时候会出现死锁,要做好死锁的预防. 二.MySQL行级锁 行级锁又分共享锁和排他锁. 共享锁: 名词解释:共享锁又叫做读锁,所有的事务只能对其进行读操作不能写操作,加上共享锁后其他事务不能再加排他锁了只能加行级锁. 用法: SELECT `id` FROM table WHERE id in(1,2) LOCK IN SHARE MODE 结果集的数据都会加共享锁 排他锁: 名词解释:
-
MySQL数据库的一次死锁实例分析
1.故事起因于2016年11月15日的一个生产bug.业务场景是:归档一个表里边的数据到历史表里边,同是删除主表记录. 2.背景场景简化如下(数据库引擎InnoDb,数据隔离级别RR[REPEATABLE]) -- 创建表test1 CREATE TABLE test1 ( id int(11) NOT NULL AUTO_INCREMENT, name varchar(10) NOT NULL, PRIMARY KEY (id) ); insert into test1 values('hel
-
Mysql 数据库死锁过程分析(select for update)
近期有一个业务需求,多台机器需要同时从Mysql一个表里查询数据并做后续业务逻辑,为了防止多台机器同时拿到一样的数据,每台机器需要在获取时锁住获取数据的数据段,保证多台机器不拿到相同的数据. 我们Mysql的存储引擎是innodb,支持行锁.解决同时拿数据的方法有很多,为了更加简单,不增加其他表和服务的情况下,我们考虑采用select... for update的方式,这样X锁锁住查询的数据段,表里其他数据没有锁,其他业务逻辑还是可以操作. 这样一台服务器比如select .. for upda
-
mysql 数据库死锁原因及解决办法
死锁(Deadlock) 所谓死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程.由于资源占用是互斥的,当某个进程提出申请资源后,使得有关进程在无外力协助下,永远分配不到必需的资源而无法继续运行,这就产生了一种特殊现象死锁. 一种情形,此时执行程序中两个或多个线程发生永久堵塞(等待),每个线程都在等待被其他线程占用并堵塞了的资源.例如,如果线程A锁住了记
-
查找MySQL线程中死锁的ID的方法
如果遇到死锁了,怎么解决呢?找到原始的锁ID,然后KILL掉一直持有的那个线程就可以了, 但是众多线程,可怎么找到引起死锁的线程ID呢? MySQL 发展到现在,已经非常强大了,这个问题很好解决. 直接从数据字典连查找. 我们来演示下. 线程A,我们用来锁定某些记录,假设这个线程一直没提交,或者忘掉提交了. 那么就一直存在,但是数据里面显示的只是SLEEP状态. mysql> set @@autocommit=0; Query OK, 0 rows affected (0.00 sec) mys