python解析库Beautiful Soup安装的详细步骤
目录
- 一、Beautiful Soup的安装
- 1.1 安装lxml库
- 1.2 安装beautifulsoup4
- 1.3 验证beautifulsoup4能否运行
- 补充:Python 安装beautifulsoup4库失败或引用错误的解决办法
- 总结
一、Beautiful Soup的安装
Beautiful Soup是Python的一个HTML或XML的解析库,使用它可以很方便地从网页中提取数据。它的解析器是依赖于lxml库的,所以在此之前,请确保已经成功安装好了lxml库。
本文环境是windows 10 64位+ python3.11, 此处以windows安装为例。
1.1 安装lxml库
lxml库的安装,首先尝试使用pip进行安装:
pip install lxml
如果pip安装报错,比如提示缺少libxml2库等信息,那么可以采用wheel方式安装
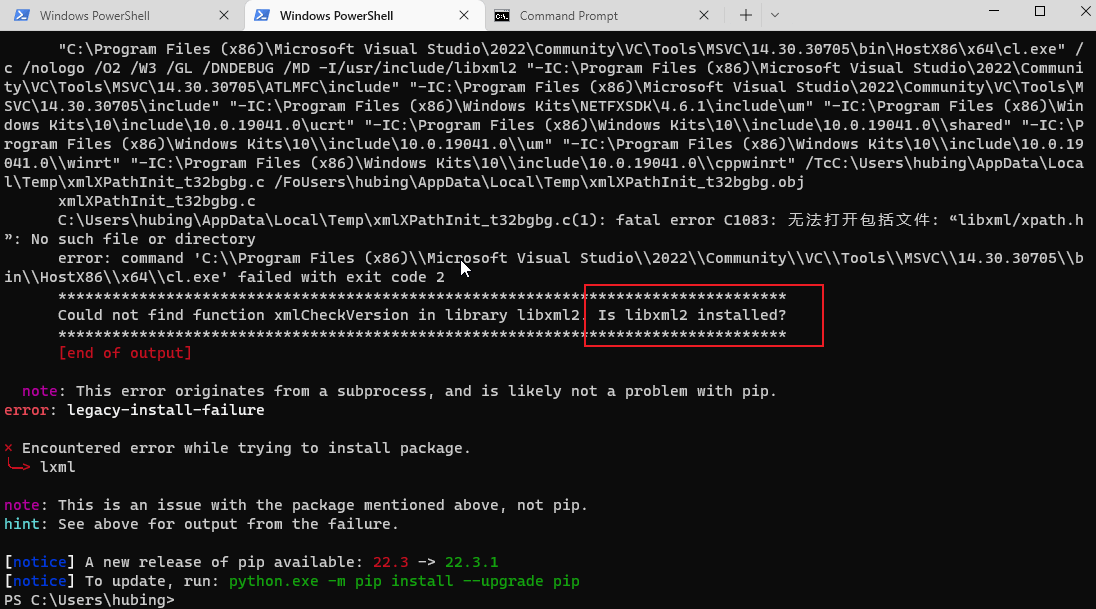
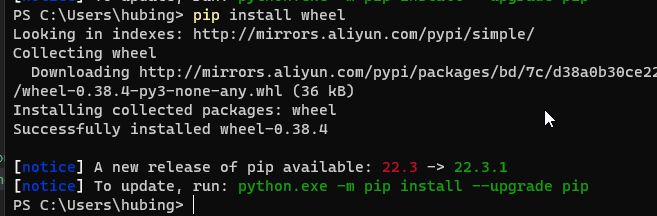
采用wheel方式安装,首先需要安装wheel
pip install wheel
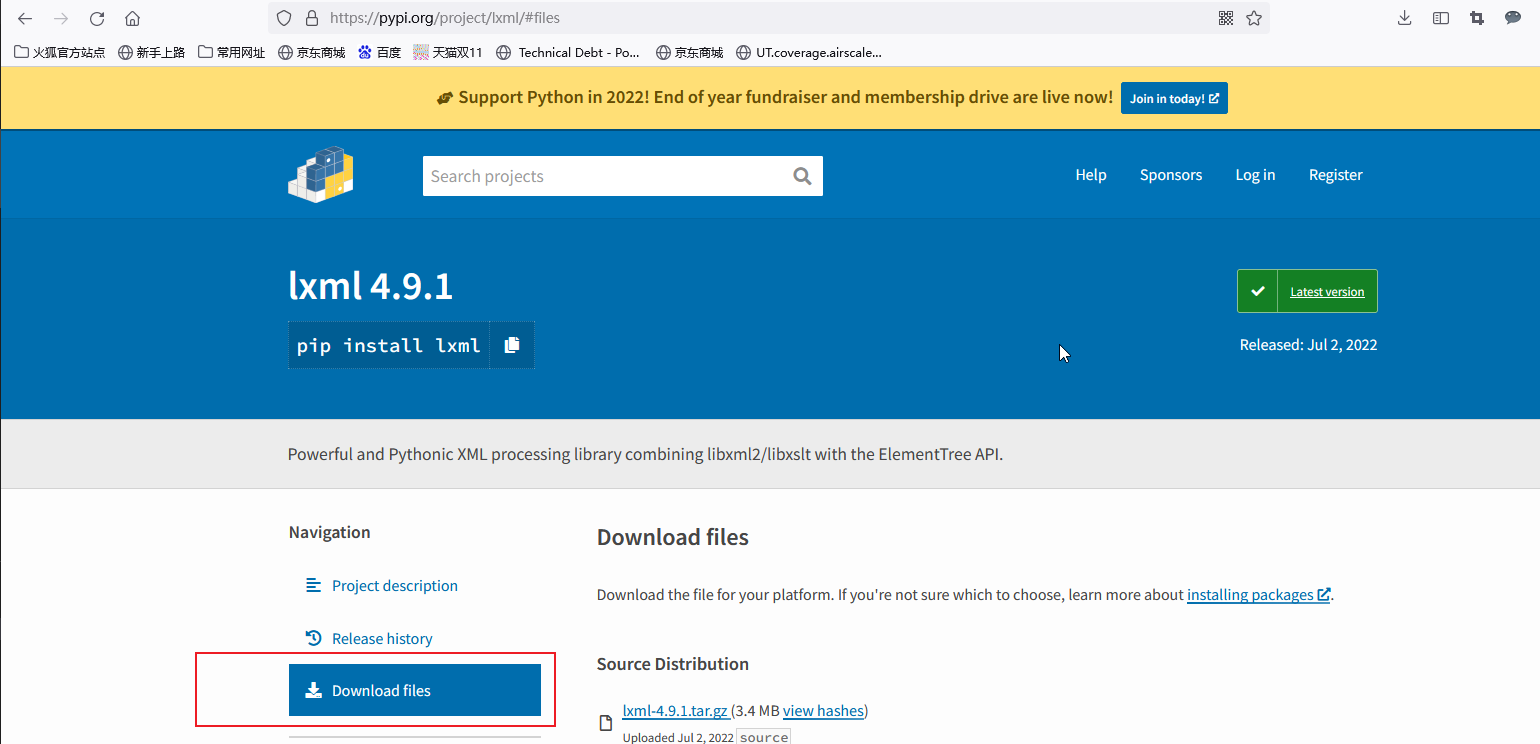
然后去官网https://pypi.org/project/lxml/下载lxml对应的的wheel版本, 当前最新版本是lxml 4.9.1, 点击Download files
在列出的files里面,选出和自己的版本相匹配的,例如你的python版本是3.10的,你的机器是windows系统,64位版本,那么就选lxml-4.9.1-cp310-cp310-win_amd64.whl
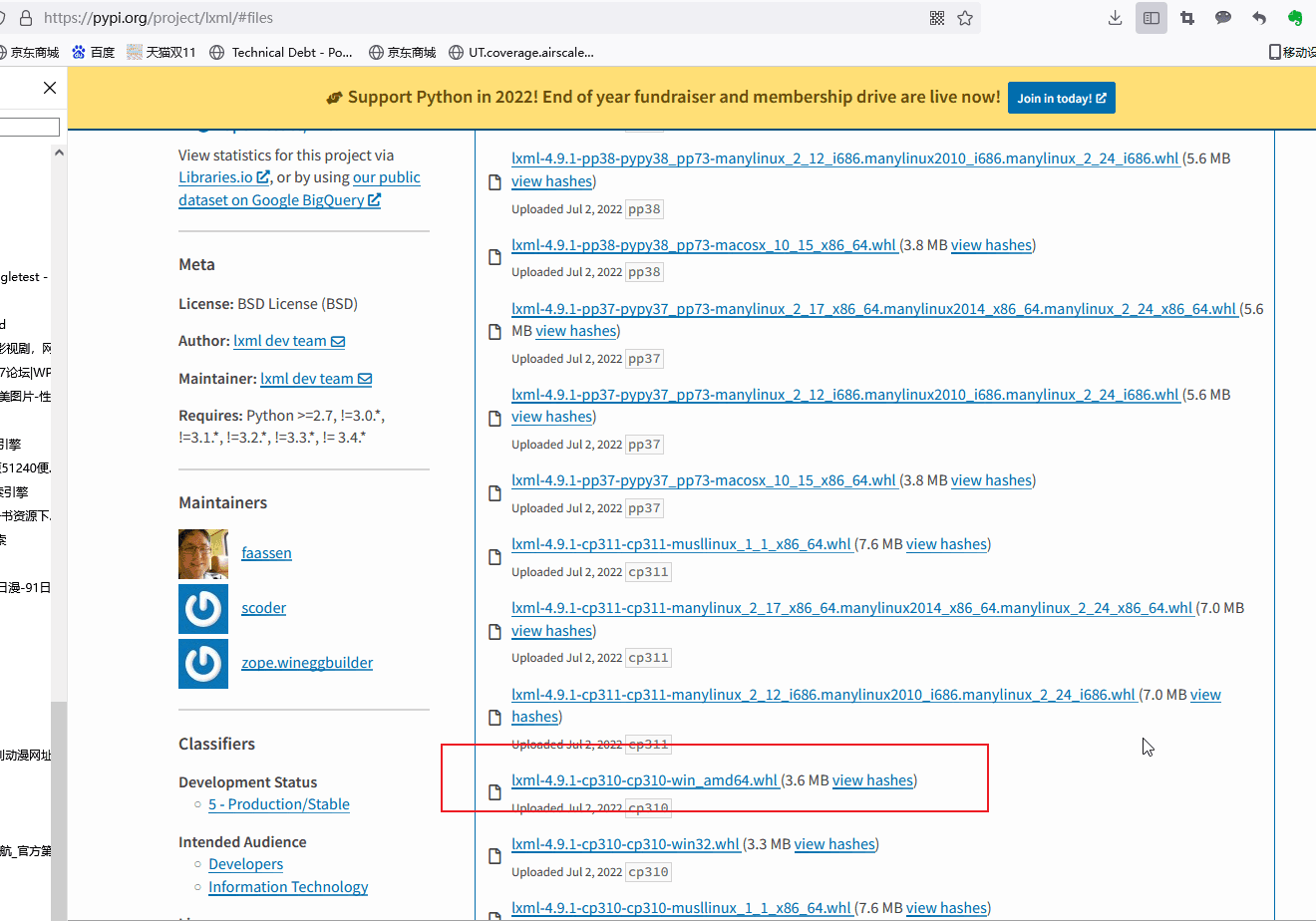
这里比较坑的一点是,python版本最新的已经是3.11版本了,但是lxml没有对应的官方windows 311版本,只有linux下的311版本。可以选择对python版本降级,比如降到python3.10版。
或者在https://www.lfd.uci.edu/~gohlke/pythonlibs/里,倒是可以找到311版本的windows wheel安装包,可以自行尝试。
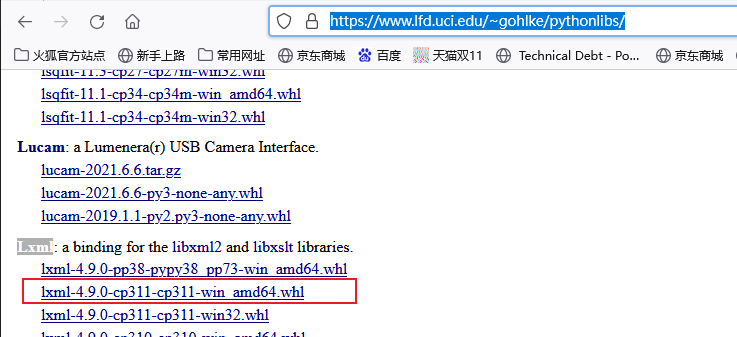
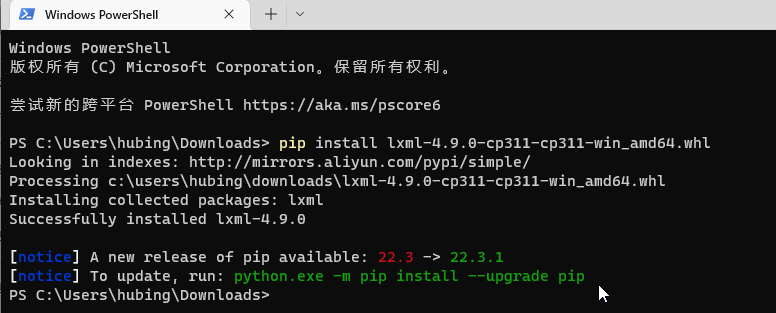
安装wheel包的话,到wheel安装包所在目录执行pip 命令即可,或者带上全路径也可以
pip install lxml-4.9.0-cp311-cp311-win_amd64.whl
1.2 安装beautifulsoup4
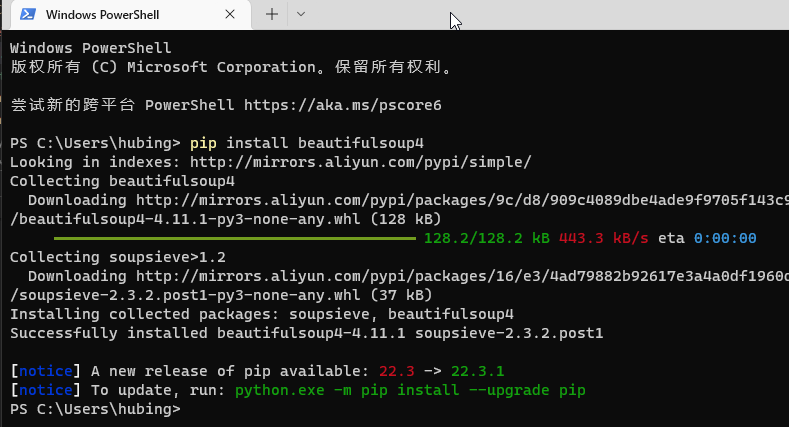
推荐使用pip来安装,执行下述安装命令
pip install beautifulsoup4
1.3 验证beautifulsoup4能否运行
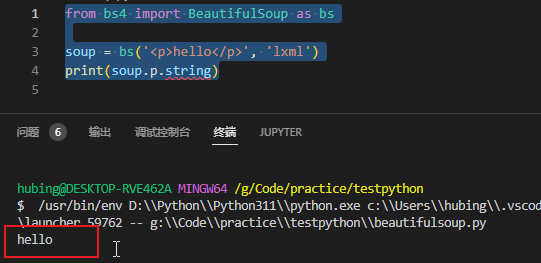
执行以下代码,能成功输出hello,就说明可以成功使用beautifulsoup4进行解析了。
如果只有beautifulsoup4安装成功,lxml库没有正确安装的话,下面代码不能成功执行。
from bs4 import BeautifulSoup as bs
soup = bs('<p>hello</p>', 'lxml')
print(soup.p.string)
补充:Python 安装beautifulsoup4库失败或引用错误的解决办法
1、首先下载官网BeautifulSoup4软件包里面的beautifulsoup4库
2、然后解压缩到G:\python\Lib\site-packages\bs4目录下,打开cmd窗口,进入到解压目录下,进入 G:\python\Lib\site-packages\bs4\beautifulsoup4-4.3.2\beautifulsoup4-4.3.2
3、在该目录下运行cmd
python setup.py build python setup.py install
可能会遇到的报错 :error in pymmseg setup command: use_2to3 is invalid.
报错的解决方案:需要把版本降低,小于58的最后一个版本是57.5.0,pip降一下就可以了:
pip install setuptools==57.5.0
就可以重新安装库了
没遇到报错,直接到这步骤即可
导入模块(测试模块导入是否成功)
进入cmd-python输入:
from bs4 import BeautifulSoup
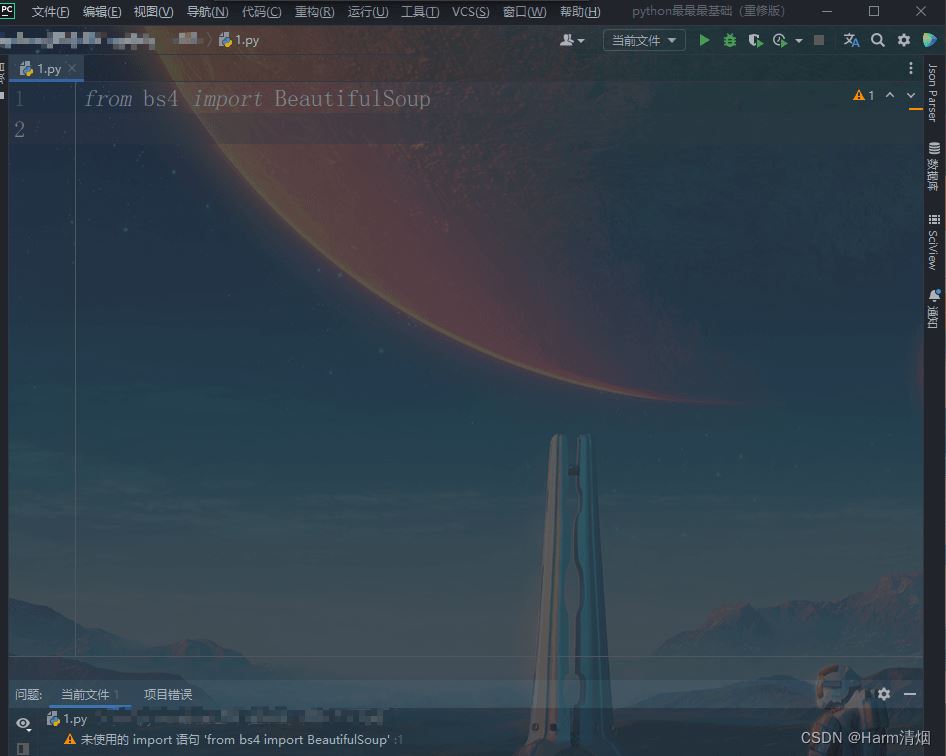
注意:导入这个库是要大写的,小写不行。
问题解决成功!
ps:这是我碰到的问题,解决了很久也问了很多人,还是没能够解决是靠自己经过百度查询了很多的资料才解决的,希望能帮助到你们。
总结
到此这篇关于python解析库Beautiful Soup安装的详细步骤的文章就介绍到这了,更多相关解析库Beautiful Soup安装内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于如何使用python的gradio库
Gradio是一个功能丰富的Python库,可以让您轻松创建和共享自己的交互式机器学习和深度学习模型. 以下是Gradio库的一些主要功能: 创建交互式接口 Gradio库使得创建交互式接口变得非常简单.您只需要定义一个函数来表示您的模型或应用程序,Gradio库将使用这个函数来创建一个用户友好的交互式界面,让用户输入参数并查看输出结果. 支持多种输入和输出类型 Gradio库支持多种输入和输出类型,包括文本.图像.音频和视频.您可以轻松地定义自己的输入和输出类型,并将其与您的模型或应用程序相关
-
Python中loguru日志库的使用
目录 1.概述 2.常见用法 2.1.显示格式 2.2.写入文件 2.3.json日志 2.4.日志绕接 2.5.并发安全 3.高级用法 3.1.接管标准日志logging 3.2.输出日志到网络服务器 3.3.与pytest结合 附录 1.概述 python中的日志库logging使用起来有点像log4j,但配置通常比较复杂,构建日志服务器时也不是方便.标准库logging的替代品是loguru,loguru使用起来就简单的多. loguru默认的输出格式是:时间.级别.模块.行号以及日志内容
-
关于Python网络爬虫requests库的介绍
1. 什么是网络爬虫 简单来说,就是构建一个程序,以自动化的方式从网络上下载.解析和组织数据. 就像我们浏览网页的时候,对于我们感兴趣的内容我们会复制粘贴到自己的笔记本中,方便下次阅读浏览——网络爬虫帮我们自动完成这些内容 当然如果遇到一些无法复制粘贴的网站——网络爬虫就更能显示它的力量了 为什么需要网络爬虫 当我们需要做一些数据分析的时候——而很多时候这些数据存储在网页中,手动下载需要花费的时间太长,这时候我们就需要网络爬虫帮助我们自动爬取这些数据来(当然我们会过滤掉网页上那些没用的东西) 网
-

Python中使用Beautiful Soup库的超详细教程
1. Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据.官方解释如下: Beautiful Soup提供一些简单的.python式的函数用来处理导航.搜索.修改分析树等功能.它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序. Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码.你不需要考虑编码方式,除非文档没有指
-
Python 数据分析之Beautiful Soup 提取页面信息
概述 数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识. Beautiful Soup Beautiful 是一个可以从 HTML 或 XML 文件中提取数据的 Pyhton 库. 简单来说, 它能将 HTML 的标签文件解析成树形结构, 然后方便的获取到指定标签的对应属性. 安装: pip install beautifulsoup4 例子: from bs4 import BeautifulSoup #
-
Python 解析库json及jsonpath pickle的实现
1. 数据抽取的概念 2. 数据的分类 3. JSON数据概述及解析 3.1 JSON数据格式 3.2 解析库json json模块是Python内置标准库,主要可以完成两个功能:序列化和反序列化.JSON对象和Python对象映射图如下: 3.2.1 json序列化 对象(字典/列表) 通过 json.dump()/json.dumps() ==> json字符串.示例代码如下: import json class Phone(object): def __init__(self, name,
-
Python标准库datetime date模块的详细介绍
目录 前言 1.定义 1.2.常见错误 2.date类常用的函数 2.1.获取当期日期 2.2.格式化日期 2.2.1.ctime() 2.2.2.datetime.date对象 2.2.3.replace(self, year=None, month=None, day=None) 2.2.4.格式化日期 2.3.ISO标准格式日期 2.3.1.获取符合ISO标准格式的日期字符串的星期几(1~7) 2.3.2.返回日期或者时间对象的星期几(0~6) 2.3.3.根据时间戳计算日期 2.3.4.
-
Python开发工具Pycharm的安装以及使用步骤总结
前言 PyCharm是一种Python 的IDE工具(集成开发环境),带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,内部集成的功能如下: Project管理 智能提示 语法高亮 代码跳转 调试代码 解释代码(解释器) 框架和库 ...... 总而言之,PyCharm 是一款功能强大的 Python 编辑器,推荐以后编写Python代码,主要用的就是这款IDE. 一.Pycharm下载 先登陆Pycharm官网或者直接输入Pycharm下载地址:https://www.jet
-
Python3 pywin32模块安装的详细步骤
python新手一枚,操作系统Win10 64 bit,Python版本,3.7 因为某个脚本需要用到win32con 和win32api模块,run -- cmd ,使用easy_install pywin32 命令安装,提示错误,搜不到, 网上搜了下教程,分别用pip3 install pypiwin32 和python -m pip install pypiwin32 命令试了下,安装报错 (使用pip3 install pypiwin32 命令是下载pypiwin32-219.zi
-
Linxu服务器上安装JDK 详细步骤
一.环境 VMware12 Pro CentOS-6.7-i386-bin-DVD1 jdk-8u151-linux-i586 二.详细安装步骤 前提:需要卸载自己Linux上的jdk rpm-qa| grepjdk 会显示你所有包含jdk这个字符串的安装包 rpm-e--nodeps对应的每个包名 会卸载对应的包 之后如果java -version显示 就是卸完了. 我之前是装过jdk1.7的,所以我需要卸载 ,没装过的直接从下面开始 1.去官网下载JDK http://www.oracle.
-
Linux下Python脚本自启动和定时启动的详细步骤
一.Python开机自动运行 假如Python自启动脚本为 auto.py .那么用root权限编辑以下文件: sudo vim /etc/rc.local 如果没有 rc.local 请看 这篇文章 在exit 0上面编辑启动脚本的命令 /usr/bin/python3 /home/selfcs/auto.py > /home/selfcs/auto.log 最后重启Linux,脚本就能自动运行并打印日志了. 二.让Python脚本定时启动 用root权限编辑以下文件 sudo vim /et
-
Python中使用Selenium环境安装的方法步骤
环境准备 已正确安装python环境,已安装chrome浏览器或者firefox浏览器 使用 python --version 命令如果输出python版本则python 安装成功 安装selenium 使用pip命令安装selenium pip install selenium 下载chrome驱动 或者firefox驱动 selenium的chrome驱动(国内阿里像) selenium的firefox驱动(github地址) 注意:下载对应版本的驱, 点击浏览器三个点 - 帮助 - 关于G
-
vmware esxi6.5安装使用详细步骤
简介 ESXi专为运行虚拟机.最大限度降低配置要求和简化部署而设计.只需几分钟时间,客户便可完成从安装到运行虚拟机的全过程,特别是在下载并安装预配置虚拟设备的时候. 在VMware Virtual Appliance Marketplace 上有800多款为VMware hypervisor 创建的虚拟设备,如今,ESXi已经实现了与Virtual Appliance Marketplace的直接整合,使用户能够即刻下载并运行虚拟设备.这为即插即用型软件的交付与安装提供了一种全新和极其简化的方式