Spark 集群执行任务失败的故障处理方法
引言
昨天(2023-02-22)开始发现公司 Spark 集群上出现一些任务执行时间过长最后失败,具体表现包括:
大量执行失败的 Task,最终任务也是失败的
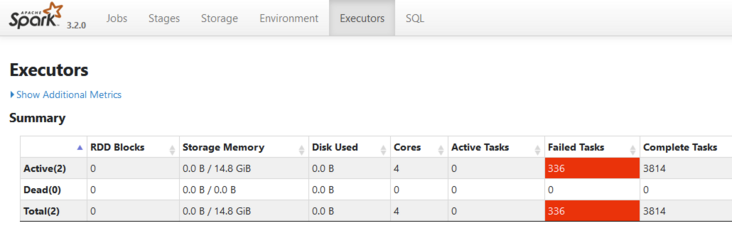
- 在 Spark Master 管理界面上看到任务的 Driver 地址不是真实 IP 地址,而是一个叫做“host.containers.internal”的主机名;
- Spark 的 worker 节点上能观察到在不停的创建 Java 进程,然后进程瞬间就结束了;
- 进入 worker 节点的日志目录查看日志内容,发现异常信息为连接 “host.containers.internal” 这个地址失败。
所以显然当前出现的问题跟“host.containers.internal”有关系。
背景说明:我们的 Spark 集群是运行在 podman 容器里的,而且是在非 root 用户下运行。
经过在互联网上搜索,发现这个主机名是容器分配给内部进程用来连接容器所在主机自身的。再进一步查看 podman 参考文档,按照里面的说法,仅当容器运行网络模式为 slirp4netns,即带上参数 "--network=slirp4netns" 时,才会有 host.containers.internal 这个主机名。
但我运行容器时带的参数是 "--network=host" 啊。
再仔细看文档才知道,slirp4netns 模式是非 root 运行容器的默认模式。按照我遇到的实际情况,难道我给的 "--network=host" 参数并没有起作用?但是用 podman inspect xxx | grep NetworkMode 命令查看容器得到的结果是:
"NetworkMode": "host"
不懂,先把这个放到一边,那么如何访问 host.containers.internal 这个主机呢,有两种方式:
- 参数改为
"--network=slirp4netns:allow_host_loopback=true" - 修改
/usr/share/containers/containers.conf,修改或添加配置network_cmd_options的值为["allow_host_loopback=true"]
在不修改 --network 参数的前提下,我用第二种方法试试。
修改配置文件然后重启各个 worker 容器,故障消失,Spark 任务能够顺利执行完成。但还需要观察一段时间。
以上就是Spark 集群执行任务失败的故障处理方法的详细内容,更多关于Spark 集群任务失败故障处理的资料请关注我们其它相关文章!
相关推荐
-

关于IDEA创建spark maven项目并连接远程spark集群问题
环境: scala:2.12.10 spark:3.0.3 1.创建scala maven项目,如下图所示: 2. 不同版本scala编译参数可能略有不同,笔者使用的scala版本是2.12.10,scala-archetype-simple插件生成的pom文件 <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <v
-
Spark集群框架的搭建与入门
目录 一.Spark概述 运行结构 二.环境部署 1.Scala环境 2.Spark基础环境 3.Spark集群配置 4.Spark启动 5.访问Spark集群 三.开发案例 1.核心依赖 2.案例代码开发 四.源代码地址 一.Spark概述 运行结构 Driver 运行Spark的Applicaion中main()函数,会创建SparkContext,SparkContext负责和Cluster-Manager进行通信,并负责申请资源.任务分配和监控等. ClusterManager 负责申请
-
基于Jupyter notebook搭建Spark集群开发环境的详细过程
一.概念介绍: 1.Sparkmagic:它是一个在Jupyter Notebook中的通过Livy服务器 Spark REST与远程Spark群集交互工作工具.Sparkmagic项目包括一组以多种语言交互运行Spark代码的框架和一些内核,可以使用这些内核将Jupyter Notebook中的代码转换在Spark环境运行. 2.Livy:它是一个基于Spark的开源REST服务,它能够通过REST的方式将代码片段或是序列化的二进制代码提交到Spark集群中去执行.它提供了以下这些基本功能:提
-
Docker-Compose搭建Spark集群的实现方法
目录 一.前言 二.docker-compose.yml 三.启动集群 四.结合hdfs使用 一.前言 在前文中,我们使用Docker-Compose完成了hdfs集群的构建.本文将继续使用Docker-Compose,实现Spark集群的搭建. 二.docker-compose.yml 对于Spark集群,我们采用一个mater节点和两个worker节点进行构建.其中,所有的work节点均分配1一个core和 1GB的内存. Docker镜像选择了bitnami/spark的开源镜像,选择的s
-
pycharm利用pyspark远程连接spark集群的实现
0 背景 由于工作需要,利用spark完成机器学习.因此需要对spark集群进行操作.所以利用pycharm和pyspark远程连接spark集群.这里记录下遇到的问题及方法. 主要是参照下面的文献完成相应的内容,但是具体问题要具体分析. 1 方法 1.1 软件配置 spark2.3.3, hadoop2.6, python3 1.2 spark配置 Spark集群的每个节点的Python版本必须保持一致.在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你
-
Spark 集群执行任务失败的故障处理方法
引言 昨天(2023-02-22)开始发现公司 Spark 集群上出现一些任务执行时间过长最后失败,具体表现包括: 大量执行失败的 Task,最终任务也是失败的 在 Spark Master 管理界面上看到任务的 Driver 地址不是真实 IP 地址,而是一个叫做“host.containers.internal”的主机名: Spark 的 worker 节点上能观察到在不停的创建 Java 进程,然后进程瞬间就结束了: 进入 worker 节点的日志目录查看日志内容,发现异常信息为连接 “h
-
使用docker快速搭建Spark集群的方法教程
前言 Spark 是 Berkeley 开发的分布式计算的框架,相对于 Hadoop 来说,Spark 可以缓存中间结果到内存而提高某些需要迭代的计算场景的效率,目前收到广泛关注.下面来一起看看使用docker快速搭建Spark集群的方法教程. 适用人群 正在使用spark的开发者 正在学习docker或者spark的开发者 准备工作 安装docker (可选)下载java和spark with hadoop Spark集群 Spark运行时架构图 如上图: Spark集群由以下两个部分组成 集
-
python中执行smtplib失败的处理方法
经测试可用的发送邮件代码: import smtplib from email.mime.text import MIMEText # 第三方 SMTP 服务 mail_host = "smtp.163.com" # SMTP服务器 mail_user = "username" # 用户名 mail_pass = "passwd" # 密码(这里的密码不是登录邮箱密码,而是授权码) sender = 'sender_mail@163.com' #
-
Quartz集群原理以及配置应用的方法详解
1.Quartz任务调度的基本实现原理 Quartz是OpenSymphony开源组织在任务调度领域的一个开源项目,完全基于Java实现.作为一个优秀的开源调度框架,Quartz具有以下特点: (1)强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求: (2)灵活的应用方式,例如支持任务和调度的多种组合方式,支持调度数据的多种存储方式: (3)分布式和集群能力,Terracotta收购后在原来功能基础上作了进一步提升.本文将对该部分相加阐述. 1.1 Quartz 核心元素
-
Docker 部署单机版 Pulsar 和集群架构 Redis(开发神器)的方法
一.前言: 现在互联网的技术架构中,不断出现各种各样的中间件,例如 MQ.Redis.Zookeeper,这些中间件在部署的时候一般都是以主从架构或者集群的架构来部署,公司一般都会在开发环境.测试环境和生产环境各部署一套. 当我们开发的时候,一般就会连着开发环境.但是呢,一般公司的开发环境都只能在内网使用,当我们回家了,除非公司提供有 VPN,不然就没办法使用了.有时候我们是有VPN了,但是开发起来还是很不方便.例如我们现在的 MQ 中间件使用的是 Pulsar,但是 Pulsar 的 tena