SQL Server 聚焦存储过程性能优化、数据压缩和页压缩提高IO性能方法(一)
前言
关于SQL Server基础系列尚未结束,还剩下最后一点内容未写,后面会继续。有园友询问我什么时候开始写SQL Server性能系列,估计还得等一段时间,最近工作也比较忙,但是会陆陆续续的更新SQL Server性能系列,本篇作为性能系列的基本引导,让大家尝尝鲜。在涉及到SQL Server性能优化时,我看到的有些文章就是一上来列出SQL Server的性能优化条例,根本没有弄清楚为什么这么做,当然也有可能是自己弄懂了,只是作为备忘录,但是到了我这里,我会遵循不仅仅是备忘录,还要让各位园友都能易于理解,不至于面试时只知道其果,不知其因。
存储过程性能优化
禁用受影响函数通过设置SET NOCOUNT ON
如上当我们进行查询时总是会返回受影响的行数,这种消息只是对于我们调试SQL时有帮助,其他再无其他帮助,我们可以通过设置 SET NOCOUNT ON 来禁用这个特性,这将有显著的性能提升,有利于减少网络流量的传输。在存储过程中我们像如下设置。
CREATE PROC dbo.ProcName AS SET NOCOUNT ON; --Your Procedure code SELECT [address], city, companyname FROM Sales.Customers -- Reset SET NOCOUNT to OFF SET NOCOUNT OFF; GO
使用架构名称+对象名称
这个建议在开篇我们就已经明确讲过,通过设置架构名称的对象名称是最合格的,此时将直接执行编译计划而不是在使用缓存计划时还要去其他可能的架构中去查找对象。所以我们建议总是像如下使用。
SELECT * FROM Sales.Customers -- 推荐 -- 而不是 SELECT * FROM Customers -- 避免 --调用存储过程如下 EXEC dbo.MyProc -- 推荐 --而不是 EXEC MyProc -- 避免
存储过程名称禁止以sp开头
如果一个存储过程名称以sp开头,此时数据库查询引擎首先将在master数据库中去查找存储过程然后再是在当前会话的数据库中去查找存储过程。
使用IF EXISTS (SELECT 1) 而不是 (SELECT *)
网上随便一搜索就看到如下查询一行是否存在的SQL语句。
declare @message varchar(200),
@name varchar(200)
if exists(select * from students where 学号='1005')
begin
set @message='下列人员符合条件:'
print @message
set @name=(select 姓名 from students where 学号='1005')
print @name
end
else
begin
set @message='没有人符合条件'
print @message
end
go
当判断一条记录是否在表中存在时我们使用IF EXISIS,如果在IF EXISTS中内部语句中有任何值返回则返回TRUE。如上述
if exists(select * from students where 学号='1005')
此时将返回学号 = '1005'的这一行,而如果用1代替则不用返回满足条件的这一行记录,在查询时为了网络传输我们应该最小化处理数据,所以我们应该像如下做返回单值1.
IF EXISTS (SELECT 1 FROM Sales.Customers WHERE [address] = 'Obere Str. 0123')
使用sp_executesql而不是使用EXECUTE
sp_executesql支持使用参数而不是使用EXECUTE来提高代码重用,动态语句的查询执行计划只有对每个字符包括大小写、空格、参数、注释相同的语句才重用。如果利用EXECUTE执行如下动态SQL语句。
DECLARE @Query VARCHAR(100) DECLARE @contactname VARCHAR(50) SET @contactname = 'Allen, Michael' SET @Query = 'SELECT * FROM Sales.Customers WHERE contactname = ' + CONVERT(VARCHAR(3),@contactname) EXEC (@Query)
执行查询计划如下,如果再一次使用不同的@contactname值,此时查询执行计划将再次创建@contactname不会达到重用的目的

如果我们使用利用sp_executesql像如下查询,如果对于不同的@contactname值,此时查询执行计划将被会重用,将会达到提高性能的目的。
DECLARE @Query VARCHAR(100) SET @Query = 'SELECT * FROM Sales.Customers WHERE contactname = @contactname' EXECUTE sp_executesql @Query,N'@contactname VARCHAR(50)',@contactname = 'Allen, Michael'
对于异常处理利用TRY-CATCH处理
在SQL Server 2005之后开始支持异常处理,如果我们进行异常语句检查处理,如果出现异常将不会导致利用更多的代码来消耗更多的资源和时间。
尽可能使事务简短
事务的长度会影响阻塞和死锁。直到事务结束排他锁不会释放,在高隔离级别中共享锁的生命周期更长, 因此,冗长的事务意味着锁定的时间更长,锁定的时间越长最终导致阻塞,在有些情况下,阻塞会转变成死锁,所以为了更快的执行、更少的阻塞,我们应该使事务的长度尽量简短。
数据压缩和页压缩提高IO
SQL Server主要的性能取决于磁盘IO效率,改善IO意味着提高性能,在SQL Server 2008中提供了数据和备份压缩功能。下面我们一起来看看。
数据压缩
数据压缩意味着磁盘保留的空间减少,数据压缩可以配置在表上的聚集索引、非聚集索引、索引视图或者分区表或者分区索引。数据压缩可以在两个级别中实现:一个是行压缩,另外一个是页压缩,甚至页压缩会自动实现行压缩,当通过CREATE TABLE、CREATE INDEX语句时会压缩表和索引,为了改变一个表、索引和分区的压缩状态通过 ALTER TABLE.. REBUILD WITH or ALTER INDEX.. REBUILD WITH语句实现。当一个堆栈的压缩状态改变后,此时非聚集索引将重建,在行压缩中,使用以下四种方法来消除未使用的空间。
1.减少记录中的元数据开销。
2.所有数字类型(INT、NUMERIC等)和基于数字类型(如DATETIME、MONEY)将会转换成可变长度值,例如INT类型在压缩后所有未被消耗的空间将会被回收。比如我们知道0-255可以存储一个字节中,若我们的值是100,在磁盘中INT是4个字节,但是在压缩之后其余3个字节将会被回收。
3.CHAR和NCHAR会转换成可变长度存储,在压缩之后对于实际存储的数据将不会再有空格,比如我们定义CHAR(10),此时我们存储的数据为Jeffcky,默认情况下将会预留10个字节,此时将会有3个字节为空格补充,但是在压缩之后这3个字节将会被回收,仅仅只预留7个字节。
4.所有NULL和0都已经过优化不需要字节。
页压缩
页压缩将会通过以下三种方法实现。
1.上述已经提到的所有。
2.前缀压缩:在每页上的每一列,被标识的所有行的公共值以及存储在标题下的每一行,在压缩之后公共值将替换为标题行的引用。
3.字典压缩:在字典压缩中,每一页中的每一列标识公共值,是将存储在标题行的第二行中,然后这些公共值将替换为新行中的值的引用。
说了这么多,具体到底是怎样使用的呢?请继续往下看,我们通过使用临时数据库插入748条数据,如下:
USE tempdb GO CREATE TABLE TestCompression (col1 INT, col2 CHAR(50)) GO INSERT INTO TestCompression VALUES (10, '压缩测试') GO 748
接下来进行行压缩和页压缩来和原始未压缩进行比较看看。
-- 原始值 EXEC sp_spaceused TestCompression GO -- DATA_COMPRESSION = 设置行压缩 ALTER TABLE TestCompression REBUILD WITH (DATA_COMPRESSION = ROW); GO EXEC sp_spaceused TestCompression GO -- DATA_COMPRESSION = 设置页压缩 ALTER TABLE TestCompression REBUILD WITH (DATA_COMPRESSION = PAGE); GO EXEC sp_spaceused TestCompression GO -- DATA_COMPRESSION = 没有压缩 ALTER TABLE TestCompression REBUILD WITH (DATA_COMPRESSION = NONE); GO EXEC sp_spaceused TestCompression GO
结果如下:
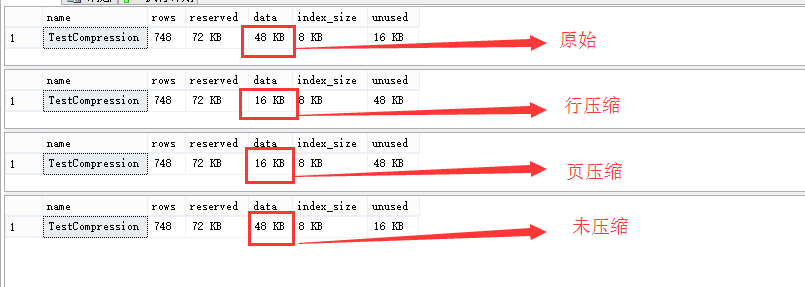
压缩后数据显然变少了,如果数据量足够大页压缩比行压缩的数据会更少,从而减少IO提高性能,不知道看到本文的你是否在生产服务上是否已经应用过呢,下次可以试试。
以上所述是小编给大家介绍的SQL Server 聚焦存储过程性能优化、数据压缩和页压缩提高IO性能方法(一),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
SQL Server存储过程中使用表值作为输入参数示例
在2008之前如果我们想要将表作为输入参数传递给SQL Server存储过程使比较困难的,可能需要很多的逻辑处理将这些表数据作为字符串或者XML传入. 在2008中提供了表值参数.使用表值参数,可以不必创建临时表或许多参数,即可向 Transact-SQL 语句或例程(如存储过程或函数)发送多行数据,这样可以省去很多自定义的代码.这样的操作对于存储过程内基于表函数的操作变得非常容易操作. 表值参数是使用用户定义的表类型来声明的.所以使用之前要先定义表类型. /* 创建表类型.*/ CREATE
-

SQL Server中的Forwarded Record计数器影响IO性能的解决方法
一.简介 最近在一个客户那里注意到一个计数器很高(Forwarded Records/Sec),伴随着间歇性的磁盘等待队列的波动.本篇文章分享什么是forwarded record,并从原理上谈一谈为什么Forwarded record会造成额外的IO. 二.存放原理 在SQL Server中,当数据是以堆的形式存放时,数据是无序的,所有非聚集索引的指针存放指向物理地址的RID.当数据行中的变长列增长使得原有页无法容纳下数据行时,数据将会移动到新的页中,并在原位置留下一个指向新页的指针,这么做的
-
SQLServer存储过程中事务的使用方法
本文为大家分享了SQLServer存储过程中事务的使用方法,具体代码如下 create proc usp_Stock @GoodsId int, @Number int, @StockPrice money, @SupplierId int, @EmpId int, @StockUnit varchar(50), @StockDate datetime, @TotalMoney money , @ActMoney money , @baseId int, @Description nvarcha
-
SQL SERVER调用存储过程小结
在SQL Server数据库的维护或者Web开发中,有时需要在存储过程或者作业等其他数据库操作中调用其它的存储过程,下面介绍其调用的方法 一.SQL SERVER中调用不带输出参数的存储过程 SQL 代码 --存储过程的定义 create procedure [sys].[sp_add_product] ( @m_viewcount int = 0 ,@m_hotcount int = 0 ) as go --存储过程的调用 declare @m_viewcount int declare @m
-
SQL Server 聚焦存储过程性能优化、数据压缩和页压缩提高IO性能方法(一)
前言 关于SQL Server基础系列尚未结束,还剩下最后一点内容未写,后面会继续.有园友询问我什么时候开始写SQL Server性能系列,估计还得等一段时间,最近工作也比较忙,但是会陆陆续续的更新SQL Server性能系列,本篇作为性能系列的基本引导,让大家尝尝鲜.在涉及到SQL Server性能优化时,我看到的有些文章就是一上来列出SQL Server的性能优化条例,根本没有弄清楚为什么这么做,当然也有可能是自己弄懂了,只是作为备忘录,但是到了我这里,我会遵循不仅仅是备忘录,还要让各位园友
-
浅谈基于SQL Server分页存储过程五种方法及性能比较
在SQL Server数据库操作中,我们常常会用到存储过程对实现对查询的数据的分页处理,以方便浏览者的浏览. 创建数据库data_Test : create database data_Test GO use data_Test GO create table tb_TestTable --创建表 ( id int identity(1,1) primary key, userName nvarchar(20) not null, userPWD nvarchar(20) not null, u
-
五种SQL Server分页存储过程的方法及性能比较
在SQL Server数据库操作中,我们常常会用到存储过程对实现对查询的数据的分页处理,以方便浏览者的浏览.本文我们总结了五种SQL Server分页存储过程的方法,并对其性能进行了比较,接下来就让我们来一起了解一下这一过程. 创建数据库data_Test : create database data_Test GO use data_Test GO create table tb_TestTable --创建表 ( id int identity(1,1) primary key, userN
-
sql server查询语句阻塞优化性能
在生产环境下,有时公司客服反映网页半天打不到,除了在浏览器按F12的Network响应来排查,确定web服务器无故障后.就需要检查数据库是否有出现阻塞 当时数据库的生产环境中主表数据量超过2000w,子表数据量超过1亿,且更新和新增频繁.再加上做了同步镜像,很消耗资源. 这时就要新建一个会话,大概需要了解以下几点: 1.当前活动会话量有多少? 2.会话运行时间? 3.会话之间有没有阻塞? 4.阻塞时间 ? 查询阻塞的方法有很多.有sql 2000 的sp_lock, 有sql 2005及以上的d
-
深入学习SQL Server聚合函数算法优化技巧
Sql server聚合函数在实际工作中应对各种需求使用的还是很广泛的,对于聚合函数的优化自然也就成为了一个重点,一个程序优化的好不好直接决定了这个程序的声明周期.Sql server聚合函数对一组值执行计算并返回单一的值.聚合函数对一组值执行计算,并返回单个值.除了 COUNT 以外,聚合函数都会忽略空值. 聚合函数经常与 SELECT 语句的 GROUP BY 子句一起使用. 一.写在前面 如果有对Sql server聚合函数不熟或者忘记了的可以看我之前的一片博客. 本文中所有数据演示都是用
-
SQL SERVER编写存储过程小工具
在开发数据库系统的过程中,经常要写很多的存储过程.为了统一格式和简化开发过程,我编写一些存储过程,用来自动生成存储过程.下面就为您简单介绍一下它们.其中一个用于生成Insert过程,另一个用于生成Update过程. Sp_GenInsert 该过程运行后,它为给定的表生成一个完整的Insert过程.如果原来的表有标识列,您得将生成的过程中的SET IDNTITY_INSERT ON 语句手工删除. 语法如下 sp_GenInsert < Table Name >,< Stored Pro
-
SQL Server常用存储过程及示例
分页: 复制代码 代码如下: /*分页查找数据*/ CREATE PROCEDURE [dbo].[GetRecordSet] @strSql varchar(8000),--查询sql,如select * from [user] @PageIndex int,--查询当页号 @PageSize int--每页显示记录 AS set nocount on declare @p1 int declare @currentPage int set @currentPage = 0 declare @
-
SQL Server 使用join all优化 or 查询速度
比如:,master,test, 表示 该用户为 test 的下级代码,test登录后可以看到 test名下的业务和所有下级代理的业务.相关表的结构如下: user表 大约10万条记录 |-uid-|-user-|----site------| | 1 | test | ,master, | | 2 | user | ,master,test,| product表 大约30万条记录 |-pid-|-product-|-puser-| | 1 | order01 | test | | 2 | or
-
SQL Server 完整备份遇到的一个不常见的错误及解决方法
1. 错误详情 有一次在手动执行数据库完整备份时遇到如下错误: 执行多次都是这个错误信息. 提示无法生成检查点,原因可能是由于系统资源(如磁盘或内存空间)不足或者有时是由于数据库损坏而造成的. 我们检查数据库资源可以排除磁盘资源不足的情况. 2.检查点相关知识 事务日志.数据文件 和checkpoint的关系. 在SQL Server中,进行insert, update, delete时,数据并没有直接写入数据库对应的mdf文件中,而是写入了缓存里,这时,就要提到一个非常重要机制:CheckPo
-
Vite打包性能优化之开启Gzip压缩实践过程
目录 前言 Gzip 开启 Gzip 插件的其他配置 总结 前言 在使用 vite 进行项目打包时,默认已经帮我们做了一些优化工作,比如代码的压缩,分包等等.除此之外,我们还有一些可选的优化策略,比如使用 CDN ,开启 Gzip 压缩等.本文会介绍在 vite 中使用插件来开启 Gzip 压缩. Gzip Gzip 是一种压缩算法,在网络传输中使用非常普遍.随便打开一个网页,都使用了 gzip 压缩: 需要注意的是,Gzip 压缩仅对于文本类型的资源有明显提示,压缩后的体积大约是压缩前的 1/