Python常用内置模块之xml模块(详解)
xml即可扩展标记语言,它可以用来标记数据、定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。从结构上,很像HTML超文本标记语言。但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观。它被设计用来传输和存储数据,其焦点是数据的内容。那么Python是如何处理XML语言文件的呢?下面一起来看看Python常用内置模块之xml模块吧。
本文主要学习的ElementTree是python的XML处理模块,它提供了一个轻量级的对象模型。在使用ElementTree模块时,需要import xml.etree.ElementTree的操作。ElementTree表示整个XML节点树,而Element表示节点数中的一个单独的节点。
构建XML文件
ElementTree(tag),其中tag表示根节点,初始化一个ElementTree对象。
Element(tag, attrib={}, **extra)函数用来构造XML的一个根节点,其中tag表示根节点的名称,attrib是一个可选项,表示节点的属性。
SubElement(parent, tag, attrib={}, **extra)用来构造一个已经存在的节点的子节点 Element.text和SubElement.text表示element对象的额外的内容属性,Element.tag和Element.attrib分别表示element对象的标签和属性。
ElementTree.write(file, encoding='us-ascii', xml_declaration=None, default_namespace=None, method='xml'),函数新建一个XML文件,并且将节点数数据写入XML文件中。
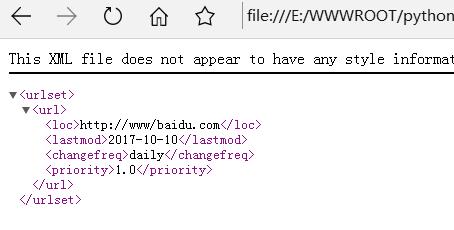
下面以新建一个网站的sitemap.xml文件为例进行代码示例
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from xml.etree import ElementTree as ET
def build_sitemap():
urlset = ET.Element("urlset") #设置一个根节点,标签为urlset
url = ET.SubElement(urlset,"url") #在根节点urlset下建立子节点
loc = ET.SubElement(url,"loc")
loc.text = "http://www/baidu.com"
lastmod = ET.SubElement(url,"lastmod")
lastmod.text = "2017-10-10"
changefreq = ET.SubElement(url,"changefreq")
changefreq.text = "daily"
priority = ET.SubElement(url,"priority")
priority.text = "1.0"
tree = ET.ElementTree(urlset)
tree.write("sitemap.xml")
if __name__ == '__main__':
build_sitemap()
结果如下图所示:
解析和修改XML文件
ElementTree.parse(source, parser=None),将xml文件加载并返回ElementTree对象。parser是一个可选的参数,如果为空,则默认使用标准的XMLParser解析器。
ElementTree.getroot(),得到根节点。返回根节点的element对象。
Element.remove(tag),删除root下名称为tag的子节点 以下函数,ElementTree和Element的对象都包含。
find(match),得到第一个匹配match的子节点,match可以是一个标签名称或者是路径。返回个element findtext(match,default=None),得到第一个配置的match的element的内容 findall(match),得到匹配match下的所有的子节点,match可以是一个标签或者是路径,它会返回一个list,包含匹配的elements的信息 iter(tag),创建一个以当前节点为根节点的iterator。
还是以上面创建的sitemap.xml为例,对其进行一定的修改,代码示例如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from xml.etree import ElementTree as ET
tree = ET.parse("sitemap.xml")
url = tree.find("url")
for rank in tree.iter('loc'):
rank.text = "http://www.adminba.com"
tree.write("sitemap.xml")
以上的代码将url修改为http://www.adminba.com了。另外,节点还有set(设置节点属性)、attrib(删除节点属性)方法。
这篇Python常用内置模块之xml模块(详解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中的两个内置模块介绍
使用了Python一段时间后,可以说Python的基本单位就是模块了,在使用模块的时候我们一般会使用通过import语句来将其导入,但是我们在没有导入任何模块的时候,我们却能使用这样的一些函数:int(),str(),len(),range(),以及使用try except语句来捕获异常,那么这些又是从哪儿来的呢. 基本 Python在启动时会自动导入内建的__builtin__和exceptions这两个模块, 使任何程序都能够使用它们,所以说这两个模块应该是整个Python语言中最重要的模块
-
python解析xml模块封装代码
有如下的xml文件: 复制代码 代码如下: <?xml version="1.0" encoding="utf-8" ?> <root> <childs> <child name='first' >1</child> <child value="2">2</child> </childs> </root> 下面介绍python解
-
Python常用模块用法分析
本文较为详细的讲述了Python中常用的模块,分享给大家便于大家查阅参考之用.具体如下: 1.内置模块(不用import就可以直接使用) 常用内置函数: help(obj) 在线帮助, obj可是任何类型 callable(obj) 查看一个obj是不是可以像函数一样调用 repr(obj) 得到obj的表示字符串,可以利用这个字符串eval重建该对象的一个拷贝 eval_r(str) 表示合法的python表达式,返回这个表达式 dir(obj) 查看obj的name space中可见的nam
-

Python常用内置模块之xml模块(详解)
xml即可扩展标记语言,它可以用来标记数据.定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言.从结构上,很像HTML超文本标记语言.但他们被设计的目的是不同的,超文本标记语言被设计用来显示数据,其焦点是数据的外观.它被设计用来传输和存储数据,其焦点是数据的内容.那么Python是如何处理XML语言文件的呢?下面一起来看看Python常用内置模块之xml模块吧. 本文主要学习的ElementTree是python的XML处理模块,它提供了一个轻量级的对象模型.在使用ElementTre
-
Python常用的正则表达式处理函数详解
正则表达式是一个特殊的字符序列,用于简洁表达一组字符串特征,检查一个字符串是否与某种模式匹配,使用起来十分方便. 在Python中,我们通过调用re库来使用re模块: import re 正则表达式语法模式和操作符详见:https://www.runoob.com/python/python-reg-expressions.html#flags 下面介绍Python常用的正则表达式处理函数. re.match函数 re.match 函数从字符串的起始位置匹配正则表达式,返回match对象,如果不
-
Python自动重新加载模块详解(autoreload module)
守护进程模式 使用python开发后台服务程序的时候,每次修改代码之后都需要重启服务才能生效比较麻烦. 看了一下Python开源的Web框架(Django.Flask等)都有自己的自动加载模块功能(autoreload.py),都是通过subprocess模式创建子进程,主进程作为守护进程,子进程中一个线程负责检测文件是否发生变化,如果发生变化则退出,主进程检查子进程的退出码(exist code)如果与约定的退出码一致,则重新启动一个子进程继续工作. 自动重新加载模块代码如下: autorel
-
Python常用库Numpy进行矩阵运算详解
Numpy支持大量的维度数组和矩阵运算,对数组运算提供了大量的数学函数库! Numpy比Python列表更具优势,其中一个优势便是速度.在对大型数组执行操作时,Numpy的速度比Python列表的速度快了好几百.因为Numpy数组本身能节省内存,并且Numpy在执行算术.统计和线性代数运算时采用了优化算法. Numpy的另一个强大功能是具有可以表示向量和矩阵的多维数组数据结构.Numpy对矩阵运算进行了优化,使我们能够高效地执行线性代数运算,使其非常适合解决机器学习问题. 与Python列表相比
-
Python多线程编程之threading模块详解
一.介绍 线程是什么?线程有啥用?线程和进程的区别是什么? 线程是操作系统能够进行运算调度的最小单位.被包含在进程中,是进程中的实际运作单位.一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务. 二.Python如何创建线程 2.1 方法一: 创建Thread对象 步骤: 1.目标函数 2.实例化Thread对象 3.调用start()方法 import threading # 目标函数1 def fun1(num): for i in range(
-
Python学习之包与模块详解
目录 什么是 Python 的包与模块 包的身份证 如何创建包 创建包的小练习 包的导入 - import 模块的导入 - from…import 导入子包及子包函数的调用 导入主包及主包的函数调用 导入的包与子包模块之间过长如何优化 强大的第三方包 什么是第三方包 如何安装第三方包 总结 大家好,学完面向对象与异常处理机制之后,接下里我们要学习 包与模块 .首先我们要了解什么是包?什么是模块?接下来我们还要学习 如何自定义创建包.自定义创建模块以及如何导入包与模块.最后我们在学习如何使用第三方
-
Python常用数据类型之列表使用详解
目录 1.常用数据结构之列表 2.定义和使用列表 2.1列表的运算符 2.2列表元素的遍历 3.列表的方法 3.1添加和删除元素 3.2元素位置和次数 3.3元素排序和反转 4.列表的生成式 5.嵌套的列表 总结 1.常用数据结构之列表 我们先给大家一个编程任务,将一颗色子掷6000次,统计每个点数出现的次数.这个任务对大家来说应该是非常简单的,我们可以用1到6均匀分布的随机数来模拟掷色子,然后用6个变量分别记录每个点数出现的次数,相信大家都能写出下面的代码. import random f1
-
python自带的http模块详解
挺久没写博客了,因为博主开始了今年另一段美好的实习经历,学习加做项目,时间已排满:很感谢今年这两段经历,让我接触了golang和python,学习不同语言,可以跳出之前学习c/c++思维的限制,学习golang和python的优秀特性以及了解在不同的场景,适用不同的语言:而之前学习linux和c/c++,也使我很快就上手golang和python; 我学习的习惯,除了学习如何使用,还喜欢研究源码,学习运行机制,这样用起来才会得心应手或者说,使用这些语言或框架,就和平时吃饭睡觉一样,非常自然:因为
-
python的random和time模块详解
目录 一.模块概述 二.模块内容 三.模块导入的原理 四.模块导入的方法 五.random模块 六.time模块 (1)python表示时间的三种格式 (2)常用方法: (3)时间元组.时间戳.格式化字符串转换 总结 一.模块概述 模块指的是包含python代码的文件,也就是一个.py文件就是一个模块.文件夹(directory)---->包(package),是一种特殊的模块.模块名要符合标识符的命名规范,以字母开头,且不能和自带的模块重名.模块第一次被导入时会先执行模块本身,多次导入只有第一
-
python的正则表达式和re模块详解,一起来看看
目录 一.正则表达式基础 二.pythonre模块 三.进阶 总结 一.正则表达式基础 二.python re模块 注意:正则表达式 != re eg: 注意:如果返回的是对象,则需要使用group分组. 三.进阶 1.分组,使用()即可 028-888888 tel_num = "028-888888" pattern_obj = re.compile("(\d{3})-(\d{6})") res = re.match(pattern=pattern_obj, s