python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
一.分散性聚类(kmeans)
算法流程:
1.选择聚类的个数k.
2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心。
3.对每个点确定其聚类中心点。
4.再计算其聚类新中心。
5.重复以上步骤直到满足收敛要求。(通常就是确定的中心点不再改变。
优点:
1.是解决聚类问题的一种经典算法,简单、快速
2.对处理大数据集,该算法保持可伸缩性和高效率
3.当结果簇是密集的,它的效果较好
缺点
1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
2.必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。
3.不适合于发现非凸形状的簇或者大小差别很大的簇
4.对躁声和孤立点数据敏感
这里为了看鸢尾花的三种聚类算法的直观区别,所以不用具体算法实现,只需要调用相应函数即可。
程序如下:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data[:, :4] # #表示我们取特征空间中的4个维度
print(X.shape)
# 绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
estimator = KMeans(n_clusters=3) # 构造聚类器
estimator.fit(X) # 聚类
label_pred = estimator.labels_ # 获取聚类标签
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
运行结果:
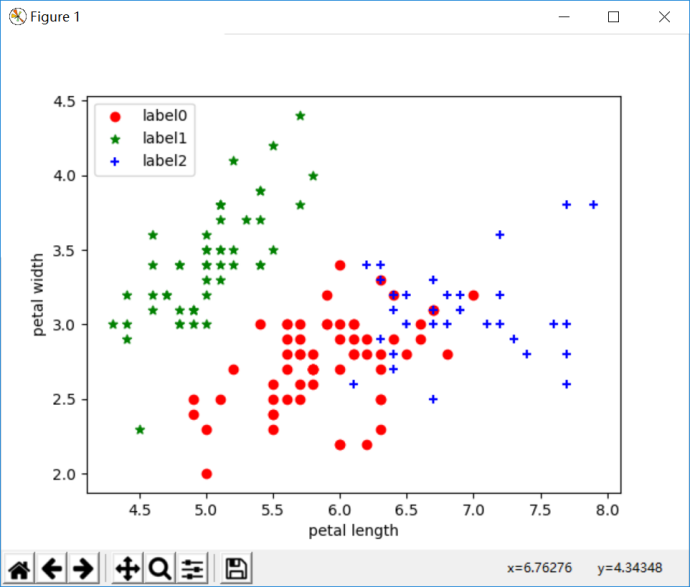
二.结构性聚类(层次聚类)
1.凝聚层次聚类:AGNES算法(自底向上)
首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足
2.分裂层次聚类:DIANA算法(自顶向下)
首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。
这里我选择的AGNES算法。
程序如下:
from sklearn import datasets
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
import pandas as pd
iris = datasets.load_iris()
irisdata = iris.data
clustering = AgglomerativeClustering(linkage='ward', n_clusters=3)
res = clustering.fit(irisdata)
print ("各个簇的样本数目:")
print (pd.Series(clustering.labels_).value_counts())
print ("聚类结果:")
print (confusion_matrix(iris.target, clustering.labels_))
plt.figure()
d0 = irisdata[clustering.labels_ == 0]
plt.plot(d0[:, 0], d0[:, 1], 'r.')
d1 = irisdata[clustering.labels_ == 1]
plt.plot(d1[:, 0], d1[:, 1], 'go')
d2 = irisdata[clustering.labels_ == 2]
plt.plot(d2[:, 0], d2[:, 1], 'b*')
plt.xlabel("Sepal.Length")
plt.ylabel("Sepal.Width")
plt.title("AGNES Clustering")
plt.show()
运行结果:
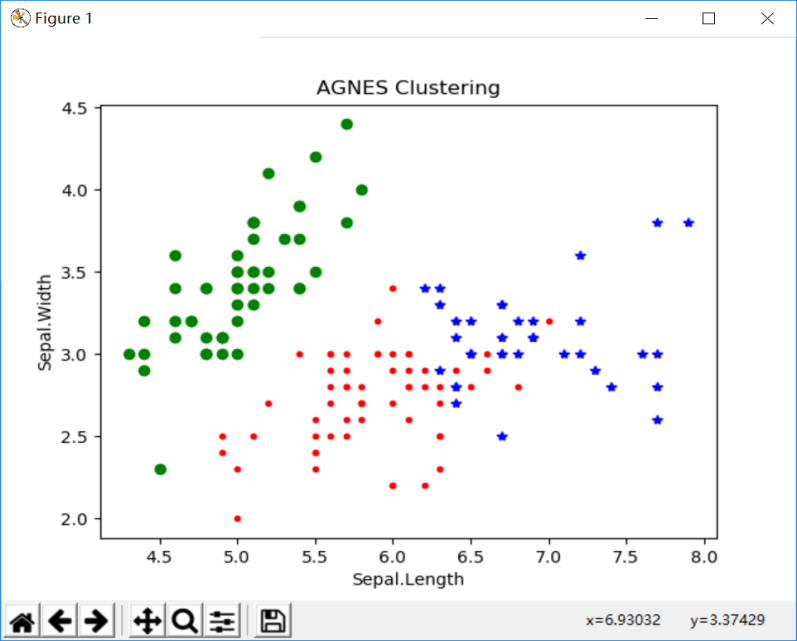
三.密度聚类之DBSCAN算法:
算法:
需要两个参数:ε (eps) 和形成高密度区域所需要的最少点数 (minPts)
它由一个任意未被访问的点开始,然后探索这个点的 ε-邻域,如果 ε-邻域里有足够的点,则建立一个新的聚类,否则这个点被标签为杂音。注意这个点之后可能被发现在其它点的 ε-邻域里,而该 ε-邻域可能有足够的点,届时这个点会被加入该聚类中。
程序如下:
import matplotlib.pyplot as plt
import numpy as np
from sklearn.cluster import KMeans
from sklearn import datasets
from sklearn.cluster import DBSCAN
iris = datasets.load_iris()
X = iris.data[:, :4] # #表示我们只取特征空间中的4个维度
print(X.shape)
# 绘制数据分布图
plt.scatter(X[:, 0], X[:, 1], c="red", marker='o', label='see')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
dbscan = DBSCAN(eps=0.4, min_samples=9)
dbscan.fit(X)
label_pred = dbscan.labels_
# 绘制k-means结果
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
plt.scatter(x0[:, 0], x0[:, 1], c="red", marker='o', label='label0')
plt.scatter(x1[:, 0], x1[:, 1], c="green", marker='*', label='label1')
plt.scatter(x2[:, 0], x2[:, 1], c="blue", marker='+', label='label2')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()
运行结果:
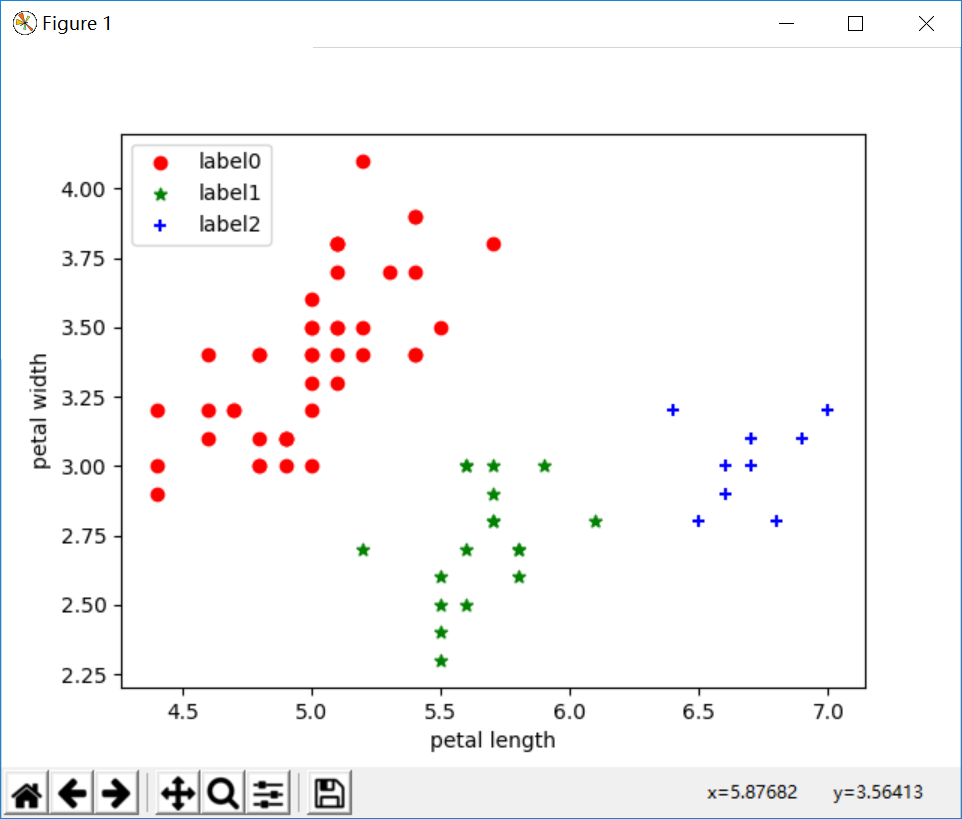
改变参数后:
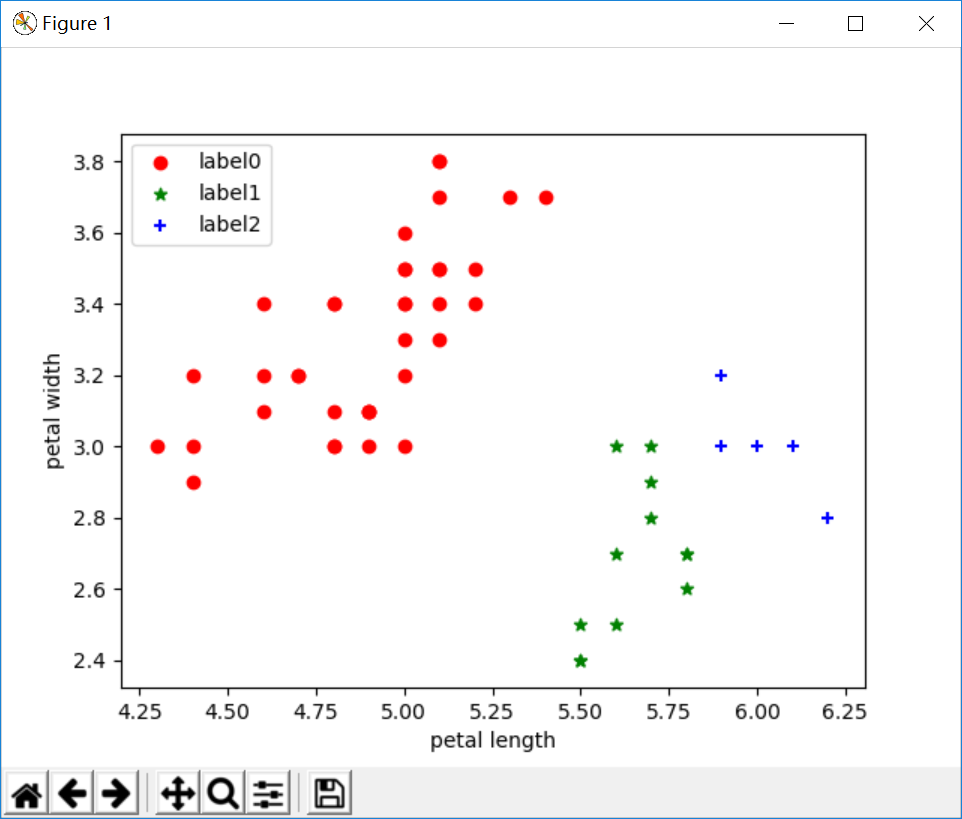
四、结果分析
从上面三种实验截图可以看出,k-means聚类和AGNES层次聚类分析结果差不多的三类,与DBSCAN的结果不一样。为啥不一样,这就取决于算法本身的优缺点了。
k-means对于大型数据集也是简单高效、时间复杂度、空间复杂度低。 最重要是数据集大时结果容易局部最优;需要预先设定K值,对最先的K个点选取很敏感;对噪声和离群值非常敏感;只用于numerical类型数据;不能解决非凸数据。
DBSCAN对噪声不敏感;能发现任意形状的聚类。 但是聚类的结果与参数有很大的关系;DBSCAN用固定参数识别聚类,但当聚类的稀疏程度不同时,相同的判定标准可能会破坏聚类的自然结构,即较稀的聚类会被划分为多个类或密度较大且离得较近的类会被合并成一个聚类。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python聚类算法之DBSACN实例分析
本文实例讲述了Python聚类算法之DBSACN.分享给大家供大家参考,具体如下: DBSCAN:是一种简单的,基于密度的聚类算法.本次实现中,DBSCAN使用了基于中心的方法.在基于中心的方法中,每个数据点的密度通过对以该点为中心以边长为2*EPs的网格(邻域)内的其他数据点的个数来度量.根据数据点的密度分为三类点: 核心点:该点在邻域内的密度超过给定的阀值MinPs. 边界点:该点不是核心点,但是其邻域内包含至少一个核心点. 噪音点:不是核心点,也不是边界点. 有了以上对数据点的划分,聚合可
-
python实现聚类算法原理
本文主要内容: 聚类算法的特点 聚类算法样本间的属性(包括,有序属性.无序属性)度量标准 聚类的常见算法,原型聚类(主要论述K均值聚类),层次聚类.密度聚类 K均值聚类算法的python实现,以及聚类算法与EM最大算法的关系 参考引用 先上一张gif的k均值聚类算法动态图片,让大家对算法有个感性认识: 其中:N=200代表有200个样本,不同的颜色代表不同的簇(其中 3种颜色为3个簇),星星代表每个簇的簇心.算法通过25次迭代找到收敛的簇心,以及对应的簇. 每次迭代的过程中,簇心和对应的簇都在变
-
Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
Python基于聚类算法实现密度聚类(DBSCAN)计算【测试可用】
本文实例讲述了Python基于聚类算法实现密度聚类(DBSCAN)计算.分享给大家供大家参考,具体如下: 算法思想 基于密度的聚类算法从样本密度的角度考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇得到最终结果. 几个必要概念: ε-邻域:对于样本集中的xj, 它的ε-邻域为样本集中与它距离小于ε的样本所构成的集合. 核心对象:若xj的ε-邻域中至少包含MinPts个样本,则xj为一个核心对象. 密度直达:若xj位于xi的ε-邻域中,且xi为核心对象,则xj由xi密度直达. 密度可达:若样
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
Python实现的KMeans聚类算法实例分析
本文实例讲述了Python实现的KMeans聚类算法.分享给大家供大家参考,具体如下: 菜鸟一枚,编程初学者,最近想使用Python3实现几个简单的机器学习分析方法,记录一下自己的学习过程. 关于KMeans算法本身就不做介绍了,下面记录一下自己遇到的问题. 一 .关于初始聚类中心的选取 初始聚类中心的选择一般有: (1)随机选取 (2)随机选取样本中一个点作为中心点,在通过这个点选取距离其较大的点作为第二个中心点,以此类推. (3)使用层次聚类等算法更新出初始聚类中心 我一开始是使用numpy
-
Python实现简单层次聚类算法以及可视化
本文实例为大家分享了Python实现简单层次聚类算法,以及可视化,供大家参考,具体内容如下 基本的算法思路就是:把当前组间距离最小的两组合并成一组. 算法的差异在算法如何确定组件的距离,一般有最大距离,最小距离,平均距离,马氏距离等等. 代码如下: import numpy as np import data_helper np.random.seed(1) def get_raw_data(n): _data=np.random.rand(n,2) #生成数据的格式是n个(x,y) _grou
-
python实现k-means聚类算法
k-means聚类算法 k-means是发现给定数据集的k个簇的算法,也就是将数据集聚合为k类的算法. 算法过程如下: 1)从N个文档随机选取K个文档作为质心 2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类,我们一般取欧几里得距离 3)重新计算已经得到的各个类的质心 4)迭代步骤(2).(3)直至新的质心与原质心相等或迭代次数大于指定阈值,算法结束 算法实现 随机初始化k个质心,用dict保存质心的值以及被聚类到该簇中的所有data. def initCent(dataSe
-
K-means聚类算法介绍与利用python实现的代码示例
聚类 今天说K-means聚类算法,但是必须要先理解聚类和分类的区别,很多业务人员在日常分析时候不是很严谨,混为一谈,其实二者有本质的区别. 分类其实是从特定的数据中挖掘模式,作出判断的过程.比如Gmail邮箱里有垃圾邮件分类器,一开始的时候可能什么都不过滤,在日常使用过程中,我人工对于每一封邮件点选"垃圾"或"不是垃圾",过一段时间,Gmail就体现出一定的智能,能够自动过滤掉一些垃圾邮件了.这是因为在点选的过程中,其实是给每一条邮件打了一个"标签&qu