从数据结构的角度分析 for each in 比 for in 快的多
之前听说火狐的JS引擎支持for each in的语法,例如下述的代码:
var arr = [10,20,30,40,50];
for each(var k in arr)
console.log(k);
即可直接遍历出arr数组的内容。
由于只有FireFox才支持,所以几乎所有的JS代码都不用这一特征。
不过在ActionScript里天生就支持for each的语法,不论Array还是Vector,还是Dictionary,只要是可枚举的对象都可以for in和for each in。
之前并没有感觉有太大的差异,为了懒得敲一个each单词,一直用熟悉的for in来遍历。
不过今天仔细琢磨了会,从数据结构的角度分析了下,觉得for in和for each in效率上有着本质的区别,无论是JS还是AS。
原因很简单:Array不是真正意义上的数组!
何为真正意义的数组?当然就是传统语言里type[]定义的数据类型,所有元素都是连续保存的。
“Array”虽然也是数组的意思,但熟悉JS的都知道,它其实是个非线性的伪数组,下标可以是任意数字。写入arr[1000000]并非真正申请容纳一百万个元素的空间,而是把1000000转换成相应的哈希值,对应到很小一块储存空间里,从而节省了大量内存。
例如有如下数组:
var arr = [];
arr[10] = 1000;
arr[20] = 2000;
arr[30] = 5000;
arr[40] = 8000;
arr[200] = 9000;
用for...in遍历Array,是个很累赘的过程:
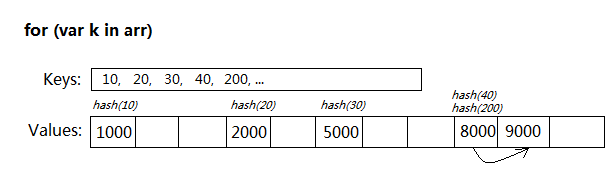
遍历时每次访问arr[k],都要进行一次Hash(k)计算,根据散列表的容量取模,如果存在冲突还得寻找最终的值结果。
如果支持for each...in的语法,其内部的数据结构就决定了会快很多:
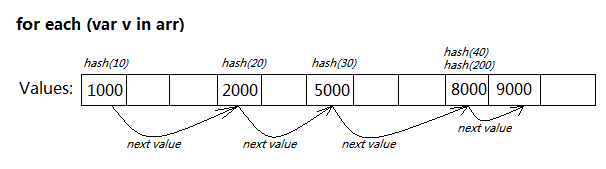
Array里直接把每个values作为节点,通过链表关联起来维护。每当有值添加或删除,就更新其链接关系。
当for each...in遍历时,只需从第一个节点往后迭代即可,无需任何Hash计算。
当然,对于AS3里Vector这样的线性数组来说,两者相差不大;同理,HTML5里支持二进制的数组ArrayBuffer也是如此。不过从理论上来看,即使arr是个连续的线性数组,for each in还是要快一点:
for...in遍历时,每次访问arr[k]都要进行下标越界检查;而for each in则根据内部链表,直接从底层反馈出迭代变量,节省了越界检查的过程。
相关推荐
-

从数据结构分析看:用for each...in 比 for...in 要快些
之前听说火狐的JS引擎支持for each in的语法,例如下述的代码: 复制代码 代码如下: var arr = [10,20,30,40,50];for each(var k in arr) console.log(k); 即可直接遍历出arr数组的内容. 由于只有FireFox才支持,所以几乎所有的JS代码都不用这一特征. 不过在ActionScript里天生就支持for each的语法,不论Array还是Vector,还是Dictionary,只要是可枚举的对象都可以for in和
-
JS数组的遍历方式for循环与for...in
JS数组的遍历方法有两种: 第一种:一般的for循环,例如: var a = new Array("first", "second", "third") for(var i = 0;i < a.length; i++) { document.write(a[i]+","); } 输出的结果:fitst,second,third 第一种:用for...in 这种遍历的方式,例如: var arr = new Array(&
-
js的for in循环和java里foreach循环的区别分析
本文实例分析了js的for in循环和java里foreach循环的区别.分享给大家供大家参考.具体分析如下: js里的for in循环定义如下: 复制代码 代码如下: for(var variable in obj) { ... } obj可以是一个普通的js对象或者一个数组.如果obj是js对象,那么variable在遍历中得到的是对象的属性的名字,而不是属性对应的值.如果obj是数组,那么variable在遍历中得到的是数组的下标. 遍历对象实验: 复制代码 代码如下: var v = {
-
浅谈javascript中for in 和 for each in的区别
区别一: for in是javascript 1.0 中发布的. for each in是作为E4X标准的一部分在javascript 1.6中发布的,而它不是ECMAScript标准的一部分. 这将意味着存在各种浏览器的兼容性问题.for each in,对很多浏览器都不支持的.例如是不支持IE6,IE7,IE8等浏览器的. 区别二: 例: var 长方形= { 高:"15", 宽:"25" }; for (var i in
-
关于js中for in的缺陷浅析
for in 语句用来列举对象的属性(成员),如下 复制代码 代码如下: var obj = { name:"jack", getName:function(){return this.name}};//输出name,getName for(var atr in obj) { alert(atr);} 注意了吗,没有输出obj的toString,valueOf等内置属性(或称内置成员,隐藏属性和预定义属性).即for in用来列举对象的显示成员(自定义成员). 如
-
从数据结构的角度分析 for each in 比 for in 快的多
之前听说火狐的JS引擎支持for each in的语法,例如下述的代码: 复制代码 代码如下: var arr = [10,20,30,40,50];for each(var k in arr)console.log(k); 即可直接遍历出arr数组的内容. 由于只有FireFox才支持,所以几乎所有的JS代码都不用这一特征. 不过在ActionScript里天生就支持for each的语法,不论Array还是Vector,还是Dictionary,只要是可枚举的对象都可以for in和for
-
Java源码角度分析HashMap用法
-HashMap- 优点:超级快速的查询速度,时间复杂度可以达到O(1)的数据结构非HashMap莫属.动态的可变长存储数据(相对于数组而言). 缺点:需要额外计算一次hash值,如果处理不当会占用额外的空间. -HashMap如何使用- 平时我们使用hashmap如下 Map<Integer,String> maps=new HashMap<Integer,String>(); maps.put(1, "a"); maps.put(2, "b&quo
-
从源码角度分析Android的消息机制
前言 说到Android的消息机制,那么主要的就是指的Handler的运行机制.其中包括MessageQueue以及Looper的工作过程. 在开始正文之前,先抛出两个问题: 为什么更新UI的操作要在主线程中进行? Android中为什么主线程不会因为Looper.loop()里的死循环卡死? UI线程的判断是在ViewRootImpl中的checkThread方法中完成的. 对于第一个问题,这里给一个简单的回答: 如果可以在子线程中修改UI,多线程的并发访问可能会导致UI控件的不可预期性,采用
-
Android Map数据结构全面总结分析
目录 前言 Map ArrayMap TreeMap HashMap 总结 前言 上一篇讲了Collection.Queue和Deque.List或Set,没看的朋友可以去简单看看,这一篇主要讲和Map相关的数据结构. Map 上篇有介绍过,Map是另一种数据结构,它独立于Collection,它的是一个接口,它的抽象实现是AbstractMap,它内部是会通过Set来实现迭代器 Set<Map.Entry<K, V>> entrySet(); 是和Set有关联的,思想上主要以ke
-
浅谈JVM系列之从汇编角度分析NullCheck
一个普通的virtual call 我们来分析一下在方法中调用list.add方法的例子: public class TestNull { public static void main(String[] args) throws InterruptedException { List<String> list= new ArrayList(); list.add("www.flydean.com"); for (int i = 0; i < 10000; i++)
-
从架构思维角度分析高并发下幂等性解决方案
目录 1 背景 2 幂等性概念 3 幂等性问题的常见解决方案 3.1 查询操作和删除操作 3.2 使用唯一索引 或者唯一组合索引 3.3 token机制 3.4 悲观锁 3.5 乐观锁 3.6 分布式锁 3.7 select + insert 3.8 状态机幂等 3.9 保证Api接口的幂等性 4 会议室的解决方案 5 总结 1 背景 我们的云办公系统有一个会议预定模块,每个月最后一个工作日的下午三点,会启动对下个月会议室的可用预定. 公司的 会议室大约200个,但是需求量远不止于此,所以会形
-
从架构思维角度分析分布式锁方案
目录 1 介绍 2 关于分布式锁 3 分布式锁的实现方案 3.1 基于数据库实现 3.1.1 乐观锁的实现方式 3.1.2 悲观锁的实现方式 3.1.3 数据库锁的优缺点 3.2基于Redis实现 3.2.1 基于缓存实现分布式锁 3.2.2缓存实现分布式锁的优缺点 3.3 基于Zookeeper实现 3.3.1 实现过程 3.3.2 zk实现分布式锁的优缺点 3.4 三种方案的对比总结 1 介绍 前面的文章我们介绍了分布式系统和它的CAP原理:一致性(Consistency).可用性(Ava
-
Java数据结构超详细分析二叉搜索树
目录 1.搜索树的概念 2.二叉搜索树的简单实现 2.1查找 2.2插入 2.3删除 2.4修改 3.二叉搜索树的性能 1.搜索树的概念 二叉搜索树是一种特殊的二叉树,又称二叉查找树,二叉排序树,它有几个特点: 如果左子树存在,则左子树每个结点的值均小于根结点的值. 如果右子树存在,则右子树每个结点的值均大于根结点的值. 中序遍历二叉搜索树,得到的序列是依次递增的. 二叉搜索树的左右子树均为二叉搜索树. 二叉搜索树的结点的值不能发生重复. 2.二叉搜索树的简单实现 我们来简单实现以下搜索树,就不
-
Android 数据结构全面总结分析
前言 这次算一个总结,我们平时都会用到各种各样的数据结构,但是可能从未看过它们内部是如何去实现的.只有了解了它们内部大概的一个实现原理,才能在不同的场景中能选出最适合这个场景的数据结构. 虽然标题说是Android,但其实有一半是属于java的,由于涉及得比较多,所以打算分篇来写会比较好,我不会把全部的源码都进行分析,主要做的是分析一些能表现这些数据结构的特征. Collection 一切数据结构的最顶层,是一个接口,继承迭代器Iterable,主要是定义所有数据结构的公共行为,比如说boole
-
从JVM的内存管理角度分析Java的GC垃圾回收机制
一个优秀的Java程序员必须了解GC的工作原理.如何优化GC的性能.如何与GC进行有限的交互,因为有一些应用程序对性能要求较高,例如嵌入式系统.实时系统等,只有全面提升内存的管理效率 ,才能提高整个应用程序的性能.本篇文章首先简单介绍GC的工作原理之后,然后再对GC的几个关键问题进行深入探讨,最后提出一些Java程序设计建议,从GC角度提高Java程序的性能. GC的基本原理 Java的内存管理实际上就是对象的管理,其中包括对象的分配和释放. 对于程序员来说,分配对象使用