python去掉空白行的多种实现代码
测试代码 jb51.txt
1:www.jb51.net 2:www.jb51.net 3:www.jb51.net 4:www.jb51.net 5:www.jb51.net 6:www.jb51.net 7:www.jb51.net 8:www.jb51.net 9:www.jb51.net 10:www.jb51.net 11:www.jb51.net 12:www.jb51.net 13:www.jb51.net 14:www.jb51.net 15:www.jb51.net 16:www.jb51.net
python代码
代码一
# -*- coding: utf-8 -*-
'''
python读取文件,将文件中的空白行去掉
'''
def delblankline(infile, outfile):
infopen = open(infile, 'r',encoding="utf-8")
outfopen = open(outfile, 'w',encoding="utf-8")
lines = infopen.readlines()
for line in lines:
if line.split():
outfopen.writelines(line)
else:
outfopen.writelines("")
infopen.close()
outfopen.close()
delblankline("jb51.txt", "o.txt")
代码二
# -*- coding: utf-8 -*-
'''
python读取文件,将文件中的空白行去掉
'''
def delblankline(infile, outfile):
infopen = open(infile, 'r',encoding="utf-8")
outfopen = open(outfile, 'w',encoding="utf-8")
lines = infopen.readlines()
for line in lines:
line = line.strip()
if len(line)!=0:
outfopen.writelines(line)
outfopen.write('\n')
infopen.close()
outfopen.close()
delblankline("jb51.txt", "o2.txt")
代码三:python2
#coding:utf-8
import sys
def delete(filepath):
f=open(filepath,'a+')
fnew=open(filepath+'_new.txt','wb') #将结果存入新的文本中
for line in f.readlines(): #对每一行先删除空格,\n等无用的字符,再检查此行是否长度为0
data=line.strip()
if len(data)!=0:
fnew.write(data)
fnew.write('\n')
f.close()
fnew.close()
if __name__=='__main__':
if len(sys.argv)==1:
print u"必须输入文件路径,最好不要使用中文路径"
else:
delete(sys.argv[1])
效果图
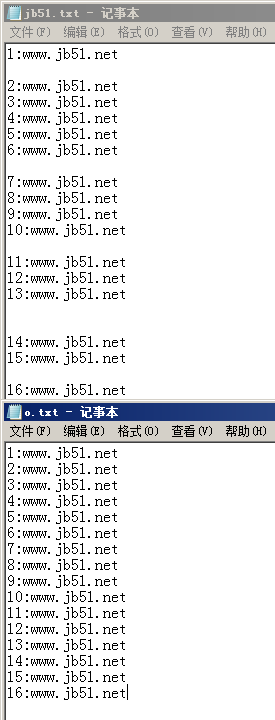
代码解析:
1. Python split()通过指定分隔符对字符串进行切片,返回分割后的字符串列表。str.split()分隔符默认为空格。
2. 函数 writelines(list)
函数writelines可以将list写入到文件中,但是不会在list每个元素后加换行符,所以如果想每行都有换行符的话需要自己再加上。
例如:for line in lines:
outfopen.writelines(line+"\n")
3. .readlines() 自动将文件内容分析成一个行的列表,该列表可以由 Python 的 for ... in ... 结构进行处理。
相关推荐
-
python将文本中的空格替换为换行的方法
测试文本 jb51.txt welcome to jb51.net I love you very much python代码 # -*- coding: utf-8 -*- ''' 遇到文中的空格就换行 ''' def delblankline(infile, outfile): infopen = open(infile, 'r',encoding="utf-8") outfopen = open(outfile, 'w',encoding="utf-8") d
-
Python实现将多个空格换为一个空格.md的方法
最近在文本预处理时遇到这个问题,解决方法如下: import re str1 = ' rwe fdsa fasf ' str1_after = re.sub(' +', '', str1) print(str1_after) 进一步的,可以将多个数字转换为特定符号,如'num',这一步在自然语言预处理中也常用,因为有时候我们并不关心是什么数,只关心是不是数字. import re str1 = '我的电话18888888888,邮箱1111111@qq.com' str1_after = re.
-
Python去除、替换字符串空格的处理方法
个人想到的解决方法有两种,一种是 .replace(' old ',' new ') 第一个参数是需要换掉的内容比如空格,第二个是替换成的内容,可以把字符串中的空格全部替换掉. 第二种方法是像这样 str_1_data = ' a b c ' str_2_list = str_1_data.split() str_1 = '' for i in range(len(str_2_list)): #这里可以直接用 str_1.join(str2_list) str_1 += str_2_lis
-
python 实现将txt文件多行合并为一行并将中间的空格去掉方法
有一个txt文本如下: 151 151 1234561 156421 214156 1523132 031320 现希望将两行合并为一行,并将中间所有的空格都去掉: (python编程第十章) 代码如下: path = r'C:\Users\xxx\Desktop\test.txt'#文本存放的路径 with open(path) as file: lines = file.readlines()#读取每一行 a = ''#空字符(中间不加空格) for line in lines: a +=
-
python在每个字符后添加空格的实例
实例如下所示: #!/usr/bin/env Python # coding=utf-8 file = open("chinese1.txt",'r') file2 = open(r'chinese2.txt', 'w')# 返回一个文件对象 list1= file.readlines() list2 = [] j = -1 for i in list1: j+=1 if j % 3 == 2: list1[j] = ("=== \n") else: list1[j
-

Python脚本处理空格的方法
最近小编遇到一个奇葩问题,就是上传代码时拷贝vs里面的代码不能直接粘贴,否则空格会不符合要求,怎么解决此问题呢?下面小编给大家分享我的解决方案,希望能够帮助到大家! 去掉空格代码 # -*- coding: utf-8 -*- '''打开delSpace.txt文本并删除每行开头的八个空格''' f=open("delSpace.txt") lines=f.readlines() for line in lines: '''第8位至倒数第1位(但不包含它)''' print line[
-
关于Python中空格字符串处理的技巧总结
前言 大家应该都知道字符串处理,是任何语言最常用到的. 其中就经常会碰到,对字符串中的空格处理,比如:去除前后空格,去除全部空格,或者以空格为分隔符来处理. 好在Python中字符串有很多方法,比如lstrip() , rstrip() , strip()来去除字符串前后空格,借助split()对字符来分隔: 实在不行,还可以借助于re模块的sub函数来替换. 下面列举下,各种情况下的处理技巧,通过示例代码介绍的非常详细,对大家具有一定的参考学习价值,话不多说了,来一起看看详细的介绍吧. [
-
python去掉空白行的多种实现代码
测试代码 jb51.txt 1:www.jb51.net 2:www.jb51.net 3:www.jb51.net 4:www.jb51.net 5:www.jb51.net 6:www.jb51.net 7:www.jb51.net 8:www.jb51.net 9:www.jb51.net 10:www.jb51.net 11:www.jb51.net 12:www.jb51.net 13:www.jb51.net 14:www.jb51.net 15:www.jb51.net 16:ww
-
Python数据可视化实现多种图例代码详解
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. from math import pi import matplotlib.pyplot as plt cat = ['Speed', 'Reliability', 'Comfort', 'Safety', 'Effieciency'] values = [90, 60, 65, 70, 40] N = len(cat) x_as = [n / float(N) * 2
-
Python中join()函数多种操作代码实例
这篇文章主要介绍了Python中join()函数多种操作代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python中有.join()和os.path.join()两个函数,具体作用如下: . join(): 连接字符串数组.将字符串.元组.列表中的元素以指定的字符(分隔符)连接生成一个新的字符串 os.path.join(): 将多个路径组合后返回 对序列进行操作(分别使用' ' .' - '与':'作为分隔符) a=['1aa','
-
Python实现登录接口的示例代码
之前写了Python实现登录接口的示例代码,最近需要回顾,就顺便发到随笔上了 要求: 1.输入用户名和密码 2.认证成功,显示欢迎信息 3.用户名3次输入错误后,退出程序 4.密码3次输入错误后,锁定用户名 Readme: 1.UserList.txt 是存放用户名和密码的文件,格式为:username: password,每行存放一条用户信息 2.LockList.txt 是存放已被锁定用户名的文件,默认为空 3.用户输入用户名,程序首先查询锁定名单 LockList.txt,如果用户名在里面
-
Python 自动化表单提交实例代码
今天以一个表单的自动提交,来进一步学习selenium的用法 练习目标 0)运用selenium启动firefox并载入指定页面(这部分可查看本人文章 http://www.cnblogs.com/liu2008hz/p/6958126.html) 1)页面元素查找(多种查找方式:find_element_*) 2)内容填充(send_keys) 3)iframe与父页面切换(switch_to_frame是切换到iframe,switch_to_default_content是切换到主页面)
-
Python文件的读写和异常代码示例
一.从文件中读取数据 #!/usr/bin/env python with open('pi') as file_object: contents = file_object.read() print(contents) =================================== 3.1415926 5212533 2324255 1.逐行读取 #!/usr/bin/env python filename = 'pi' with open(filename) as file_obje
-
Python处理文本换行符实例代码
本文研究的主要是Python处理文本换行符的相关内容,具体如下. 源文件每行后面都有回车,所以用下面输出时,中间会多了一行 try: with open("F:\\hjt.txt" ) as f : for line in f: print(line) except FileNotFoundError: print("读取文件出错") 有两种方法处理: 1.print后面带 end='',表示不换行 try: with open("F:\\hjt.txt&
-
python中pylint使用方法(pylint代码检查)
一.Pylint 是什么 Pylint 是一个 Python 代码分析工具,它分析 Python 代码中的错误,查找不符合代码风格标准和有潜在问题的代码. Pylint 是一个 Python 工具,除了平常代码分析工具的作用之外,它提供了更多的功能:如检查一行代码的长度,变量名是否符合命名标准,一个声明过的接口是否被真正实现等等. Pylint 的一个很大的好处是它的高可配置性,高可定制性,并且可以很容易写小插件来添加功能. 如果运行两次 Pylint,它会同时显示出当前和上次的运行结果,从而可
-
Python 字符串换行的多种方式
第一种: x0 = '<?xml version="1.0"?>' \ '<ol>' \ ' <li><a href="/python" rel="external nofollow" rel="external nofollow" rel="external nofollow" rel="external nofollow" >Pytho
-
python过滤中英文标点符号的实例代码
如下所示: import re # 过滤不了\\ \ 中文()还有---- r1 = u'[a-zA-Z0-9'!"#$%&\'()*+,-./:;<=>?@,.?★.-[]<>?""''![\\]^_`{|}~]+'#用户也可以在此进行自定义过滤字符 # 者中规则也过滤不完全 r2 = "[\s+\.\!\/_,$%^*(+\"\']+|[+--!,.?.~@#¥%--&*()]+" # \\\可以过滤掉