Python实现简单遗传算法(SGA)
本文用Python3完整实现了简单遗传算法(SGA)
Simple Genetic Alogrithm是模拟生物进化过程而提出的一种优化算法。SGA采用随机导向搜索全局最优解或者说近似全局最优解。传统的爬山算法(例如梯度下降,牛顿法)一次只优化一个解,并且对于多峰的目标函数很容易陷入局部最优解,而SGA算法一次优化一个种群(即一次优化多个解),SGA比传统的爬山算法更容易收敛到全局最优解或者近似全局最优解。
SGA基本流程如下:
1、对问题的解进行二进制编码。编码涉及精度的问题,在本例中精度delta=0.0001,根据决策变量的上下界确定对应此决策变量的染色体基因的长度(m)。假设一个决策变量x0上界为upper,下界为lower,则精度delta = (upper-lower)/2^m-1。如果已知决策变量边界和编码精度,那么可以用下面的公式确定编码决策变量x0所对应的染色体长度:
2^(length-1)<(upper-lower)/delta<=2^length-1
2、对染色体解码得到表现形:
解码后得到10进制的值;decoded = lower + binary2demical(chromosome)*delta。其中binary2demical为二进制转10进制的函数,在代码中有实现,chromosome是编码后的染色体。
3、确定初始种群,初始种群随机生成
4、根据解码函数得到初始种群的10进制表现型的值
5、确定适应度函数,对于求最大值最小值问题,一般适应度函数就是目标函数。根据适应度函数确定每个个体的适应度值Fi=FitnessFunction(individual);然后确定每个个体被选择的概率Pi=Fi/sum(Fi),sum(Fi)代表所有个体适应度之和。
6、根据轮盘赌选择算子,选取适应度较大的个体。一次选取一个个体,选取n次,得到新的种群population
7、确定交叉概率Pc,对上一步得到的种群进行单点交叉。每次交叉点的位置随机。
8、确定变异概率Pm,假设种群大小为10,每个个体染色体编码长度为33,则一共有330个基因位,则变异的基因位数是330*Pm。接下来,要确定是那个染色体中哪个位置的基因发生了变异。将330按照10进制序号进行编码即从0,1,2,.......229。随机从330个数中选择330*Pm个数,假设其中一个数时154,chromosomeIndex = 154/33 =4,
geneIndex = 154%33 = 22。由此确定了第154号位置的基因位于第4个染色体的第22个位置上,将此位置的基因值置反完成基本位变异操作。
9、以上步骤完成了一次迭代的所有操作。接下就是评估的过程。对变异后得到的最终的种群进行解码,利用解码值求得每个个体的适应度值,将最大的适应度值保存下来,对应的解码后的决策变量的值也保存下来。
10、根据迭代次数,假设是500次,重复执行1-9的步骤,最终得到是一个500个数值的最优适应度取值的数组以及一个500*n的决策变量取值数组(假设有n个决策变量)。从500个值中找到最优的一个(最大或者最小,根据定义的适应度函数来选择)以及对应的决策变量的取值。
对于以上流程不是很清楚的地方,在代码中有详细的注释。也可以自行查找资料补充理论。本文重点是实现
本代码实现的问题是: maxf(x1,x2) = 21.5+x1*sin(4*pi*x1)+x2*sin(20*pi*x2)
s.t. -3.0<=x1<=12.1
4.1<=x2<=5.8
初始种群的编码结果如下图所示:

初始种群的解码结果如下图所示:
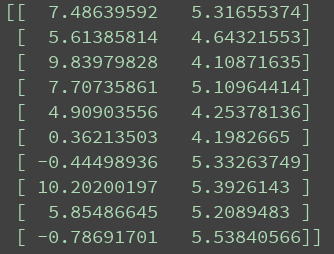
适应度值如图所示:

轮盘赌选择后的种群如图所示;

单点交叉后的种群如图所示:

基本位变异后的种群如图所示;

最终结果如下图所示;
源代码如下;
# !/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: wsw
# 简单实现SGA算法
import numpy as np
from scipy.optimize import fsolve, basinhopping
import random
import timeit
# 根据解的精度确定染色体(chromosome)的长度
# 需要根据决策变量的上下边界来确定
def getEncodedLength(delta=0.0001, boundarylist=[]):
# 每个变量的编码长度
lengths = []
for i in boundarylist:
lower = i[0]
upper = i[1]
# lamnda 代表匿名函数f(x)=0,50代表搜索的初始解
res = fsolve(lambda x: ((upper - lower) * 1 / delta) - 2 ** x - 1, 50)
length = int(np.floor(res[0]))
lengths.append(length)
return lengths
pass
# 随机生成初始编码种群
def getIntialPopulation(encodelength, populationSize):
# 随机化初始种群为0
chromosomes = np.zeros((populationSize, sum(encodelength)), dtype=np.uint8)
for i in range(populationSize):
chromosomes[i, :] = np.random.randint(0, 2, sum(encodelength))
# print('chromosomes shape:', chromosomes.shape)
return chromosomes
# 染色体解码得到表现型的解
def decodedChromosome(encodelength, chromosomes, boundarylist, delta=0.0001):
populations = chromosomes.shape[0]
variables = len(encodelength)
decodedvalues = np.zeros((populations, variables))
for k, chromosome in enumerate(chromosomes):
chromosome = chromosome.tolist()
start = 0
for index, length in enumerate(encodelength):
# 将一个染色体进行拆分,得到染色体片段
power = length - 1
# 解码得到的10进制数字
demical = 0
for i in range(start, length + start):
demical += chromosome[i] * (2 ** power)
power -= 1
lower = boundarylist[index][0]
upper = boundarylist[index][1]
decodedvalue = lower + demical * (upper - lower) / (2 ** length - 1)
decodedvalues[k, index] = decodedvalue
# 开始去下一段染色体的编码
start = length
return decodedvalues
# 得到个体的适应度值及每个个体被选择的累积概率
def getFitnessValue(func, chromosomesdecoded):
# 得到种群规模和决策变量的个数
population, nums = chromosomesdecoded.shape
# 初始化种群的适应度值为0
fitnessvalues = np.zeros((population, 1))
# 计算适应度值
for i in range(population):
fitnessvalues[i, 0] = func(chromosomesdecoded[i, :])
# 计算每个染色体被选择的概率
probability = fitnessvalues / np.sum(fitnessvalues)
# 得到每个染色体被选中的累积概率
cum_probability = np.cumsum(probability)
return fitnessvalues, cum_probability
# 新种群选择
def selectNewPopulation(chromosomes, cum_probability):
m, n = chromosomes.shape
newpopulation = np.zeros((m, n), dtype=np.uint8)
# 随机产生M个概率值
randoms = np.random.rand(m)
for i, randoma in enumerate(randoms):
logical = cum_probability >= randoma
index = np.where(logical == 1)
# index是tuple,tuple中元素是ndarray
newpopulation[i, :] = chromosomes[index[0][0], :]
return newpopulation
pass
# 新种群交叉
def crossover(population, Pc=0.8):
"""
:param population: 新种群
:param Pc: 交叉概率默认是0.8
:return: 交叉后得到的新种群
"""
# 根据交叉概率计算需要进行交叉的个体个数
m, n = population.shape
numbers = np.uint8(m * Pc)
# 确保进行交叉的染色体个数是偶数个
if numbers % 2 != 0:
numbers += 1
# 交叉后得到的新种群
updatepopulation = np.zeros((m, n), dtype=np.uint8)
# 产生随机索引
index = random.sample(range(m), numbers)
# 不进行交叉的染色体进行复制
for i in range(m):
if not index.__contains__(i):
updatepopulation[i, :] = population[i, :]
# crossover
while len(index) > 0:
a = index.pop()
b = index.pop()
# 随机产生一个交叉点
crossoverPoint = random.sample(range(1, n), 1)
crossoverPoint = crossoverPoint[0]
# one-single-point crossover
updatepopulation[a, 0:crossoverPoint] = population[a, 0:crossoverPoint]
updatepopulation[a, crossoverPoint:] = population[b, crossoverPoint:]
updatepopulation[b, 0:crossoverPoint] = population[b, 0:crossoverPoint]
updatepopulation[b, crossoverPoint:] = population[a, crossoverPoint:]
return updatepopulation
pass
# 染色体变异
def mutation(population, Pm=0.01):
"""
:param population: 经交叉后得到的种群
:param Pm: 变异概率默认是0.01
:return: 经变异操作后的新种群
"""
updatepopulation = np.copy(population)
m, n = population.shape
# 计算需要变异的基因个数
gene_num = np.uint8(m * n * Pm)
# 将所有的基因按照序号进行10进制编码,则共有m*n个基因
# 随机抽取gene_num个基因进行基本位变异
mutationGeneIndex = random.sample(range(0, m * n), gene_num)
# 确定每个将要变异的基因在整个染色体中的基因座(即基因的具体位置)
for gene in mutationGeneIndex:
# 确定变异基因位于第几个染色体
chromosomeIndex = gene // n
# 确定变异基因位于当前染色体的第几个基因位
geneIndex = gene % n
# mutation
if updatepopulation[chromosomeIndex, geneIndex] == 0:
updatepopulation[chromosomeIndex, geneIndex] = 1
else:
updatepopulation[chromosomeIndex, geneIndex] = 0
return updatepopulation
pass
# 定义适应度函数
def fitnessFunction():
return lambda x: 21.5 + x[0] * np.sin(4 * np.pi * x[0]) + x[1] * np.sin(20 * np.pi * x[1])
pass
def main(max_iter=500):
# 每次迭代得到的最优解
optimalSolutions = []
optimalValues = []
# 决策变量的取值范围
decisionVariables = [[-3.0, 12.1], [4.1, 5.8]]
# 得到染色体编码长度
lengthEncode = getEncodedLength(boundarylist=decisionVariables)
for iteration in range(max_iter):
# 得到初始种群编码
chromosomesEncoded = getIntialPopulation(lengthEncode, 10)
# 种群解码
decoded = decodedChromosome(lengthEncode, chromosomesEncoded, decisionVariables)
# 得到个体适应度值和个体的累积概率
evalvalues, cum_proba = getFitnessValue(fitnessFunction(), decoded)
# 选择新的种群
newpopulations = selectNewPopulation(chromosomesEncoded, cum_proba)
# 进行交叉操作
crossoverpopulation = crossover(newpopulations)
# mutation
mutationpopulation = mutation(crossoverpopulation)
# 将变异后的种群解码,得到每轮迭代最终的种群
final_decoded = decodedChromosome(lengthEncode, mutationpopulation, decisionVariables)
# 适应度评价
fitnessvalues, cum_individual_proba = getFitnessValue(fitnessFunction(), final_decoded)
# 搜索每次迭代的最优解,以及最优解对应的目标函数的取值
optimalValues.append(np.max(list(fitnessvalues)))
index = np.where(fitnessvalues == max(list(fitnessvalues)))
optimalSolutions.append(final_decoded[index[0][0], :])
# 搜索最优解
optimalValue = np.max(optimalValues)
optimalIndex = np.where(optimalValues == optimalValue)
optimalSolution = optimalSolutions[optimalIndex[0][0]]
return optimalSolution, optimalValue
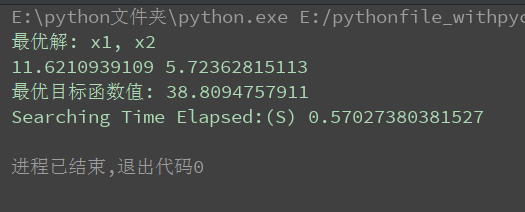
solution, value = main()
print('最优解: x1, x2')
print(solution[0], solution[1])
print('最优目标函数值:', value)
# 测量运行时间
elapsedtime = timeit.timeit(stmt=main, number=1)
print('Searching Time Elapsed:(S)', elapsedtime)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- Python决策树和随机森林算法实例详解
- python实现随机森林random forest的原理及方法
- 用Python实现随机森林算法的示例
- python实现K最近邻算法
- Python实现KNN邻近算法
- python机器学习案例教程——K最近邻算法的实现
- python实现决策树C4.5算法详解(在ID3基础上改进)
- 基于ID3决策树算法的实现(Python版)
- python实现ID3决策树算法
- python实现决策树分类算法
- Python机器学习之决策树算法
- Python实现的随机森林算法与简单总结
相关推荐
-
python实现随机森林random forest的原理及方法
引言 想通过随机森林来获取数据的主要特征 1.理论 随机森林是一个高度灵活的机器学习方法,拥有广泛的应用前景,从市场营销到医疗保健保险. 既可以用来做市场营销模拟的建模,统计客户来源,保留和流失.也可用来预测疾病的风险和病患者的易感性. 根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系,可同时生成的并行化方法: 前者的代表是Boosting,后者的代表是Bagging和"随机森林"(
-
python机器学习案例教程——K最近邻算法的实现
K最近邻属于一种分类算法,他的解释最容易,近朱者赤,近墨者黑,我们想看一个人是什么样的,看他的朋友是什么样的就可以了.当然其他还牵着到,看哪方面和朋友比较接近(对象特征),怎样才算是跟朋友亲近,一起吃饭还是一起逛街算是亲近(距离函数),根据朋友的优秀不优秀如何评判目标任务优秀不优秀(分类算法),是否不同优秀程度的朋友和不同的接近程度要考虑一下(距离权重),看几个朋友合适(k值),能否以分数的形式表示优秀度(概率分布). K最近邻概念: 它的工作原理是:存在一个样本数据集合,也称作为训练样本集,并
-

Python机器学习之决策树算法
一.决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构. 决策树的根结点是所有样本中信息量最大的属性.树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性.决策树的叶结点是样本的类别值.决策树是一种知识表示形式,它是对所有样本数据的高度概括决策树能准确地识别所有样本的类别,也能有效地识别新样本的类别. 决策树算法ID3的基本思想: 首先找出最有判别力的属性,把样例分成多个子集,每个子集又选择最有判别力的属性进行划分,一直进行到所有子集仅包含同一类型的数据为止.最后
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python实现K最近邻算法
KNN核心算法函数,具体内容如下 #! /usr/bin/env python3 # -*- coding: utf-8 -*- # fileName : KNNdistance.py # author : zoujiameng@aliyun.com.cn import math def getMaxLocate(target): # 查找target中最大值的locate maxValue = float("-inFinIty") for i in range(len(target)
-
python实现决策树分类算法
本文实例为大家分享了python实现决策树分类算法的具体代码,供大家参考,具体内容如下 1.概述 决策树(decision tree)--是一种被广泛使用的分类算法. 相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置 在实际应用中,对于探测式的知识发现,决策树更加适用. 2.算法思想 通俗来说,决策树分类的思想类似于找对象.现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话: 女儿:多大年纪了? 母亲:26. 女儿:长的帅不帅? 母亲:挺帅的. 女儿:收入高不?
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,
-
基于ID3决策树算法的实现(Python版)
实例如下: # -*- coding:utf-8 -*- from numpy import * import numpy as np import pandas as pd from math import log import operator #计算数据集的香农熵 def calcShannonEnt(dataSet): numEntries=len(dataSet) labelCounts={} #给所有可能分类创建字典 for featVec in dataSet: currentLa
-
Python决策树和随机森林算法实例详解
本文实例讲述了Python决策树和随机森林算法.分享给大家供大家参考,具体如下: 决策树和随机森林都是常用的分类算法,它们的判断逻辑和人的思维方式非常类似,人们常常在遇到多个条件组合问题的时候,也通常可以画出一颗决策树来帮助决策判断.本文简要介绍了决策树和随机森林的算法以及实现,并使用随机森林算法和决策树算法来检测FTP暴力破解和POP3暴力破解,详细代码可以参考: https://github.com/traviszeng/MLWithWebSecurity 决策树算法 决策树表现了对象属性和
-
Python实现KNN邻近算法
简介 邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表. kNN算法的核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性.该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别. kNN方法在类别决策时,只与极少量的相邻样本有关.由于kNN
-
Python实现的随机森林算法与简单总结
本文实例讲述了Python实现的随机森林算法.分享给大家供大家参考,具体如下: 随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器.算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样: *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根.自然对数等: *每棵树完全生成,不进行剪枝: *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即各棵树的叶节点的平均) 著名的python机器学习包scikit learn的文档对此算法有