Java解析word,获取文档中图片位置的方法
前言(背景介绍):
Apache POI是Apache基金会下一个开源的项目,用来处理office系列的文档,能够创建和解析word、excel、ppt格式的文档。
其中对word文档的处理有两个技术,分别是HWPF(.doc)和XWPF(.docx)。如果你对这两个技术熟悉的话,就应该能明白使用java解析word文档的痛楚所在。
其中两个最大的问题在于:
第一是这两个类并没有统一的父类和接口(隔壁的XSSF和HSSF投过来鄙视的眼光),所以没法进行同一格式的接口式编程;
第二是官方API中并没有文档中图片相对位置的接口,这就导致了虽然你能获得文档中的所有图片,但是你并不能知道这些图片是在哪里,将来要展示图片就没法插入到正确的位置。
对于第一点,我是没什么办法,可以研究下其他相关技术,比如jacob,doc4j等看看有没有其他的解决方案,不过doc4j这货貌似只能处理2007文档(.docx)。
对于第二点,本文将给出笔者的解决方案,实际上,这也是我写本文的目的所在。
注意:简单求快的同学看第二章和第三章就行了;
一、预备知识
1.word文档的两种格式对应两种不同的存储方式
众所周知,word文档有两种存储格式:doc和docx
doc:习惯上称为Word2003,使用二进制储存数据;这个不是我们今天讨论的重点.
docx:word2007,使用xml来存储数据和格式.
可能你会问了,明明是docx结尾的文档,怎么成了xml格式了?
很简单:你随便选择一个docx文件,右键使用压缩工具打开,就能得到一个这样的目录结构:

所以你以为docx是一个完整的文档,其实它只是一个压缩文件。(docx:?_?)
2.Word文档中xml的定义格式:
从前面我们知道了docx文档使用压缩文件也就是xml来描述数据,那么word文档中的数据具体是怎么定义的呢?
出于篇幅的关系,这里不会详细地描述整个压缩的文档,这里只简单介绍下两个文件/文件夹:
一是word目录下的documen.xml文件,这个就是整个文档内容的定义;
二是word目录下的media文件夹,看名字也能猜出来这个文件夹里面是文档中的多媒体内容:


图3:word/document.xml(定义文档内容)
图4:word/media文件夹下的内容
以下是document.xml文档的部分关键内容:
A:document整体结构定义:
<w:document mc:ignorable="w14 w15 wp14" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpscustomdata="http://www.wps.cn/officeDocument/2013/wpsCustomData"> <w:body> <w:p> <w:ppr> <w:pstyle w:val="2"> </w:pstyle> <w:keepnext w:val="0"> </w:keepnext> <w:keeplines w:val="0"> </w:keeplines> <w:widowcontrol> </w:widowcontrol> <w:suppresslinenumbers w:val="0"> </w:suppresslinenumbers> <w:pbdr> <w:top w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:top> <w:left w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:left> <w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:bottom> <w:right w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:right> </w:pbdr>
B:文档段落内容:
<w:p> <w:ppr> <w:pstyle w:val="2"> </w:pstyle> <w:keepnext w:val="0"> </w:keepnext> <w:keeplines w:val="0"> </w:keeplines> <w:widowcontrol> </w:widowcontrol> <w:suppresslinenumbers w:val="0"> </w:suppresslinenumbers> <w:pbdr> <w:top w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:top> <w:left w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:left> <w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:bottom> <w:right w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:right> </w:pbdr> <w:shd w:fill="FAFAFA" w:val="clear"> </w:shd> <w:spacing w:after="150" w:afterautospacing="0" w:before="150" w:beforeautospacing="0" w:line="378" w:linerule="atLeast"> </w:spacing> <w:ind w:firstline="0" w:left="0" w:right="0"> </w:ind> <w:rpr> <w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default"> </w:rfonts> <w:i w:val="0"> </w:i> <w:caps w:val="0"> </w:caps> <w:color w:val="404040"> </w:color> <w:spacing w:val="0"> </w:spacing> <w:sz w:val="21"> </w:sz> <w:szcs w:val="21"> </w:szcs> </w:rpr> </w:ppr> <w:r> <w:rpr> <w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default"> </w:rfonts> <w:i w:val="0"> </w:i> <w:caps w:val="0"> </w:caps> <w:color w:val="404040"> </w:color> <w:spacing w:val="0"> </w:spacing> <w:sz w:val="21"> </w:sz> <w:szcs w:val="21"> </w:szcs> <w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:bdr> <w:shd w:fill="FAFAFA" w:val="clear"> </w:shd> </w:rpr> <w:t> 作者: Brian Dear </w:t> </w:r> </w:p>
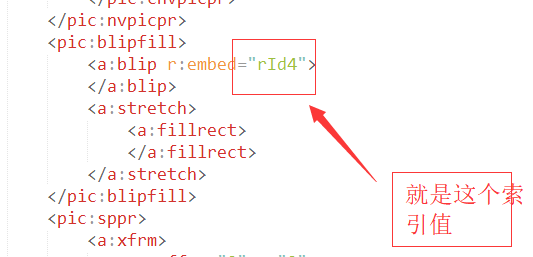
C:图片内容定义:
<w:r> <w:rpr> <w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default"> </w:rfonts> <w:i w:val="0"> </w:i> <w:caps w:val="0"> </w:caps> <w:color w:val="404040"> </w:color> <w:spacing w:val="0"> </w:spacing> <w:sz w:val="21"> </w:sz> <w:szcs w:val="21"> </w:szcs> <w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none"> </w:bdr> <w:shd w:fill="FAFAFA" w:val="clear"> </w:shd> </w:rpr> <w:drawing> <wp:inline distb="0" distl="114300" distr="114300" distt="0"> <wp:extent cx="5543550" cy="5543550"> </wp:extent> <wp:effectextent b="0" l="0" r="0" t="0"> </wp:effectextent> <wp:docpr descr="IMG_256" id="1" name="Picture 1"> </wp:docpr> <wp:cnvgraphicframepr> <a:graphicframelocks nochangeaspect="1" xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main"> </a:graphicframelocks> </wp:cnvgraphicframepr> <a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main"> <a:graphicdata uri="http://schemas.openxmlformats.org/drawingml/2006/picture"> <pic:pic xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture"> <pic:nvpicpr> <pic:cnvpr descr="IMG_256" id="1" name="Picture 1"> </pic:cnvpr> <pic:cnvpicpr> <a:piclocks nochangeaspect="1"> </a:piclocks> </pic:cnvpicpr> </pic:nvpicpr> <pic:blipfill> <a:blip r:embed="rId4"> </a:blip> <a:stretch> <a:fillrect> </a:fillrect> </a:stretch> </pic:blipfill> <pic:sppr> <a:xfrm> <a:off x="0" y="0"> </a:off> <a:ext cx="5543550" cy="5543550"> </a:ext> </a:xfrm> <a:prstgeom prst="rect"> <a:avlst> </a:avlst> </a:prstgeom> <a:nofill> </a:nofill> <a:ln w="9525"> <a:nofill> </a:nofill> </a:ln> </pic:sppr> </pic:pic> </a:graphicdata> </a:graphic> </wp:inline> </w:drawing> </w:r>
有兴趣的童鞋可以看一下上面三段xml代码,我这里直接给结论了:
word文档shema文件:xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main"
文档根节点:<w:document> 定义了整个文档的开始
<w:body>是document的子节点,文档的主体内容
<w:p>body子节点,一个段落,就是word文档中的段落
<w:r>P元素的子节点,一个Run定义了段落中具有相同格式的一段内容
<w:t>Run元素节点的子节点,就是文档的内容.
<w:drawing> run元素的子节点,定义了一张图片:
<w:inline> drawing子节点,具体应用也没有深入研究
<a:graphic> 定义图片内容
<pic:blipfill>这个是graphic文档的子节点,定义了图片内容的索引,具体来说,poi能根据这个名称拿到图片所对应的资源,而获取文档图片位置的关键也就在这里
总体看来:XWPF解析docx文档就是做了xml文档的解析,将所有的节点保存下来,然后转换成更加好用的属性,提供API出来供用户使用.
所以我们就能用POI提供给我们的接口拿到文档内容,自己去解析文档中的数据,就能获取到图片是在哪一个段落里了,当然你也可以得知图片是位于哪一个Run元素的后面.
二、实现
package com.szdfhx.reportStatistic.util;
import com.microsoft.schemas.vml.CTShape;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFPictureData;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.apache.xmlbeans.XmlCursor;
import org.apache.xmlbeans.XmlObject;
import org.openxmlformats.schemas.drawingml.x2006.main.CTGraphicalObject;
import org.openxmlformats.schemas.drawingml.x2006.picture.CTPicture;
import org.openxmlformats.schemas.drawingml.x2006.wordprocessingDrawing.CTInline;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTDrawing;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTObject;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTR;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class XWPFUtils {
//获取某一个段落中的所有图片索引
public static List<String> readImageInParagraph(XWPFParagraph paragraph) {
//图片索引List
List<String> imageBundleList = new ArrayList<String>();
//段落中所有XWPFRun
List<XWPFRun> runList = paragraph.getRuns();
for (XWPFRun run : runList) {
//XWPFRun是POI对xml元素解析后生成的自己的属性,无法通过xml解析,需要先转化成CTR
CTR ctr = run.getCTR();
//对子元素进行遍历
XmlCursor c = ctr.newCursor();
//这个就是拿到所有的子元素:
c.selectPath("./*");
while (c.toNextSelection()) {
XmlObject o = c.getObject();
//如果子元素是<w:drawing>这样的形式,使用CTDrawing保存图片
if (o instanceof CTDrawing) {
CTDrawing drawing = (CTDrawing) o;
CTInline[] ctInlines = drawing.getInlineArray();
for (CTInline ctInline : ctInlines) {
CTGraphicalObject graphic = ctInline.getGraphic();
//
XmlCursor cursor = graphic.getGraphicData().newCursor();
cursor.selectPath("./*");
while (cursor.toNextSelection()) {
XmlObject xmlObject = cursor.getObject();
// 如果子元素是<pic:pic>这样的形式
if (xmlObject instanceof CTPicture) {
org.openxmlformats.schemas.drawingml.x2006.picture.CTPicture picture = (org.openxmlformats.schemas.drawingml.x2006.picture.CTPicture) xmlObject;
//拿到元素的属性
imageBundleList.add(picture.getBlipFill().getBlip().getEmbed());
}
}
}
}
//使用CTObject保存图片
//<w:object>形式
if (o instanceof CTObject) {
CTObject object = (CTObject) o;
System.out.println(object);
XmlCursor w = object.newCursor();
w.selectPath("./*");
while (w.toNextSelection()) {
XmlObject xmlObject = w.getObject();
if (xmlObject instanceof CTShape) {
CTShape shape = (CTShape) xmlObject;
imageBundleList.add(shape.getImagedataArray()[0].getId2());
}
}
}
}
}
return imageBundleList;
}
}
首先要提出来是XWPF对xml元素的封装:
<w:document> 对应XWPFDocument类
<w:run>对应XWPFRun类
基本上只对应到Run这一层,因为run的子元素有很多,所以没有再往下面的层次封装和定义了,
所以我们使用API只能拿到所有的XWPFRun对象转成它的xml的定义:CTR对象。最后利用CTR去读取和解析的Run元素中的内容,获取图片的索引。
其次要谈的则是整个XML元素的定义:
我们可以看到POI使用的是Apache下的xmlbeans这个技术解析的XML,相关的技术不做深谈,关键要明白两点:
1:xml文档中的所有元素经过xmlbean是封装后都继承了一个XMLObject的接口,所以可以用这个类来接收获取到的子元素;
2:元素遍历是通过XmlCursor来做的,具体获取子元素是根据XmlCursor对象的selectPath属性来控制,当selectPath为"./*"时就定义为遍历子元素;
所以写成了如下的代码:能遍历当前元素的子元素,并且检验子元素的类型:
CTR ctr = run.getCTR();
//对子元素进行遍历
XmlCursor c = ctr.newCursor();
//这个就是拿到所有的子元素:
c.selectPath("./*");
while (c.toNextSelection()) {
XmlObject o = c.getObject();
//如果子元素是<w:drawing>这样的形式,使用CTDrawing保存图片
if (o instanceof CTDrawing) {
CTDrawing drawing = (CTDrawing) o;
最后你可能会有疑问,不是说<w:drawing>这个元素定义了一张图片吗?
那么
if (o instanceof CTObject) {
CTObject object = (CTObject) o;
...
}
这个第二个判断条件是用来干嘛的?
聪明的你应该已经猜到了
没错!docx文档中的xml定义图片的方式除了<w:drawing>这一种之外,还可以运用<w:object>元素去定义,
为什么只有这两种?
因为我只使用第一种方式解析,发现有些图片丢失了,于是发现了第二种方式.......也许不止两种?我也不知道,反正对于目前的我来说已经没有问题了.
或许聪明的你在实践中还遇到了更多种情况?
那么运用上面提到的xml解析方式,相信你也能正确读取,得到自己想要的索引值.
再拓宽一点,如果POI还有其他没有提供的API,我们是不是也能通过XML解析的技术自己实现呢?这个就需要我们在实践中去探索了,相信时间会给我们答案
好了,现在我们拿到了索引值,那么如何去拿到图片资源呢?
POI提供了现成的方法:
XWPFDocument类中有getPictureDataByID(String picture);
方法可以拿到XWPFPictrueDate对象,这个就是图片的资源了.
具体的操作可以参阅相关的博文和API,这里就不详细介绍了.
三、测试:
使用Junit4测试的代码:
package com.szdfhx.reportStatistic.util;
import org.apache.commons.collections.CollectionUtils;
import org.apache.commons.lang.StringUtils;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFPictureData;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.Collections;
import java.util.List;
import static org.junit.Assert.*;
public class XWPFUtilsTest {
@Test
public void readImageInParagraph() throws IOException {
InputStream in = new FileInputStream("D:\\Document\\我的博客\\Java解析word,获取文档中图片位置\\示例.docx");
XWPFDocument xwpfDocument = new XWPFDocument(in);
List<XWPFParagraph> paragraphList = xwpfDocument.getParagraphs();
System.out.println("图片的索引\t|图片名称\t|图片上一段文字的内容\t");
System.out.pringln("------------------------------------------");
for(int i = 0;i < paragraphList.size();i++){
List<String> imageBundleList = XWPFUtils.readImageInParagraph(paragraphList.get(i));
if(CollectionUtils.isNotEmpty(imageBundleList)){
for(String pictureId:imageBundleList){
XWPFPictureData pictureData = xwpfDocument.getPictureDataByID(pictureId);
String imageName = pictureData.getFileName();
String lastParagraphText = paragraphList.get(i-1).getParagraphText();
System.out.println(pictureId +"\t|" + imageName + "\t|" + lastParagraphText);
}
}
}
}
}
展示结果:

这里使用图片名称指代表明我拿到了对应的资源,实际上 如果你对前文的内容还熟悉的话,会发现图片的名称实际上就是word/media文件夹下的所有图片的全名称。
在对应的XWPFPictureData对象中,图像的二进制数据可以通过getData()属性来拿到,这样你就可以保存到数据库或者是你本地的文件夹中了!
四、其他:
谈到这里,开头提到的第二个问题这里就已经解决了。
那么,第一个问题怎么办呢?
如果你的系统对速度要求不高的话,那么我给你的建议是,把doc文档转化成docx文档来解析--POI就有成熟的API来做
如果要考虑性能的话,那就只好写两套方法去解析文档。
那么......doc类型的word文档怎么获取图片的相对位置呢?
我也不知道········或者,你来告诉我?
以上这篇Java解析word,获取文档中图片位置的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
您可能感兴趣的文章:
- 实例讲解Java读取一般文本文件和word文档的方法
- JAVA读取PDF、WORD文档实例代码
相关推荐
-
实例讲解Java读取一般文本文件和word文档的方法
一般文本文件 我们以日志文件.log文件为例: import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.FileNotFoundException; import java.io.FileReader; import java.io.IOException; public class File_Test { /** * @param args */ pub
-
JAVA读取PDF、WORD文档实例代码
读取PDF文件jar引用 <dependency> <groupid>org.apache.pdfbox</groupid> pdfbox</artifactid> <version>1.8.13</version> </dependency> 读取WORD文件jar引用 <dependency> <groupid>org.apache.poi</groupid> poi-scratch
-

Java解析word,获取文档中图片位置的方法
前言(背景介绍): Apache POI是Apache基金会下一个开源的项目,用来处理office系列的文档,能够创建和解析word.excel.ppt格式的文档. 其中对word文档的处理有两个技术,分别是HWPF(.doc)和XWPF(.docx).如果你对这两个技术熟悉的话,就应该能明白使用java解析word文档的痛楚所在. 其中两个最大的问题在于: 第一是这两个类并没有统一的父类和接口(隔壁的XSSF和HSSF投过来鄙视的眼光),所以没法进行同一格式的接口式编程: 第二是官方API中并
-
使用c#在word文档中创建表格的方法详解
复制代码 代码如下: public string CreateWordFile() { string message = ""; try { Object Nothing = System.Reflection.Missing.Value; string name = "xiehuan.doc";
-
如何使用C#从word文档中提取图片
图片和文字是word文档中两种最常见的对象,在微软word中,如果我们想要提取出一个文档内的图片,只需要右击图片选择另存为然后命名保存就可以了,今天这篇文章主要是实现如何使用C#从word文档中提取图片. 这里我准备了一个含有文字和图片的word文档: 详细步骤与代码: 步骤1 : 添加引用. 新建一个Visual C#控制台项目,添加引用并使用如下命名空间: using System; using Spire.Doc; using Spire.Doc.Documents; using Spir
-
Java 在 Word 文档中使用新文本替换指定文本的方法
创作一份文案,经常会高频率地使用某些词汇,如地名.人名.人物职位等,若表述有误,就需要整体撤换.文本将介绍如何使用Spire.Doc for Java,在Java程序中对Word文档中的指定文本进行替换. 工具/原料 Free Spire.Doc for Java(免费版) IntelliJ IDEA Jar文件获取及导入 方法1:先从官网下载jar包. 导入步骤: 下载后,解压文件,并将lib文件夹下的Spire.Doc.jar文件导入java程序.参考如下导入效果: 方法2:可通过maven
-
Java 如何将表格数据导入word文档中
Java 表格数据导入word文档中 个人觉得这个功能实在搞笑,没什么意义,没办法提了需求就要实现,(太好说话了把我) 我的实现是再word中生成一个与 excel行,列 一样的一个表格,然后把从excel拿到的数据(exList参数)依次放到word表格中 public static void createFile(HttpServletResponse response, String fileName, List<List<String>> exList) { try { s
-
asp.net下用Aspose.Words for .NET动态生成word文档中的图片或水印的方法
1.概述 在项目中生成word文档,这个功能很普遍的,一般生成都是纯文字或是列表的比较多,便于客户打印,而要把图片也生成到word文档中的需求有些客户也是需要的,例如产品图片.这次我们介绍的是如何利用Aspose.Words for .NET在Word中动态的生成图片或水印.Aspose.Words for .NET,这个我就不多介绍了,不清楚的朋友可以看看上一篇文章.需求总是变化得快,最近项目中又多了一个这样需求:系统中生成报价单后,要有一个签名,这个签名是根据不同用户来生成的图片.好了,下面
-
Java 在Word文档中添加艺术字的示例
与普通文字相比,艺术字更加美观有趣也更具有辨识度,常见于一些设计精美的杂志或宣传海报中.我们在日常工作中编辑Word文档时,也可以通过添加艺术字体来凸显文章的重点,美化页面排版.这篇文章将介绍如何使用Free Spire.Doc for Java在word文档中添加艺术字并设置样式和效果. Jar包导入 方法一:下载Free Spire.Doc for Java包并解压缩,然后将lib文件夹下的Spire.Doc.jar包作为依赖项导入到Java应用程序中. 方法二:通过Maven仓库安装JAR
-
asp.net下用Aspose.Words for .NET动态生成word文档中的数据表格的方法
1.概述 最近项目中有一个这样的需求:导出word 文档,要求这个文档的格式不是固定的,用户可以随便的调整,导出内容中的数据表格列是动态的,例如要求导出姓名和性别,你就要导出这两列的数据,而且这个文档不是导出来之后再调整而是导出来后已经是调整过了的.看到这里,您也许马上想到用模板导出!而且.NET中自带有这个组件:Microsoft.Office.Interop.Word,暂且可以满足需求吧.但这个组件也是有局限性的,例如客户端必须装 office组件,而且编码复杂度高.最麻烦的需求是后面那个-
-
C#设置Word文档背景的三种方法(纯色/渐变/图片背景)
Word是我们日常生活.学习和工作中必不可少的文档处理工具.精致美观的文档能给人带来阅读时视觉上的美感.在本篇文章中,将介绍如何使用组件Free Spire.Doc for .NET(社区版)给Word设置文档背景.下面的示例中,给Word添加背景分为三种情况来讲述,即添加纯色背景,渐变色背景和图片背景. 工具使用:下载安装控件Free Spire.Doc后,在项目程序中添加Spire.Doc.dll即可(该dll可在安装文件下Bin文件夹中获取) 一.添加纯色背景 using Spire.Do
-
C#向Word文档中添加内容控件的方法示例
前言 大家应该都知道在MS Word中,我们可以通过内容控件来向word文档中插入预先定义好的模块,指定模块的内容格式(如图片.日期.列表或格式化的文本等),从而创建一个结构化的word文档. 下面就来看看如何使用C#给word文档添加组合框.文本.图片.日期选取器及下拉列表等内容控件(这里我借助了一个word组件Spire.Doc). 添加组合框内容控件 组合框用于显示用户可以选择的项目列表.和下拉列表不同的是组合框允许用户编辑或添加项. 核心代码如下: //给段落添加一个内容控件并指定它的S