MySQL索引优化之分页探索详细介绍
目录
- MySQL索引优化之分页探索
- 案例一
- 案例二
MySQL索引优化之分页探索
表结构
CREATE TABLE `demo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄', `position` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '职位', `card_num` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '工卡号', PRIMARY KEY (`id`), KEY `index_union` (`name`,`age`,`position`) ) ENGINE=InnoDB AUTO_INCREMENT=450003 DEFAULT CHARSET=utf8; 450003条数据
limit分页执行情况

像select * from demo limit 90000,10;考虑到回表,所以mysql干脆选择全表扫描。
mysql不是直接从第90000行开始计算10条,而是从第一个叶子节点开始计数,计算90010行。
案例一
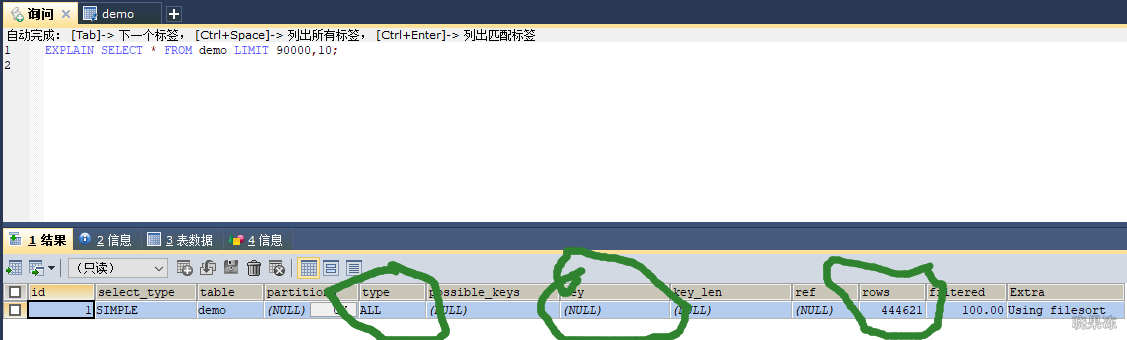
针对上图,当id是连续自增的时候,可以用主键筛选出id=90000之后的数据。因为主键的索引是B+树结构,本身就是有序的。

案例二

先按照name排序,然后再从第90000行起找10行,虽然name是索引,但select的列在index_union索引树上并没有保存。
所以还会涉及到回表,于是mysql直接选择扫主键索引树的叶子结点,先将40多万数据根据name排好序,然后计算90000行+10行。
优化方法:利用子查询解决最消耗时间的排序和回表问题,联合索引树种保存有主键id,order by name的话可以将name、age、position整个索引充分使用因为确定了最左列的排序,其余的俩列age、和position其实也是
排好序的了,通过Extra字段也可以是使用了索引树做排序。
最外层的查询是根据主键来关联的,所以几乎可以忽略。10+10 因为id是主键,可以直接拿临时表10条数据去扫。

到此这篇关于MySQL索引优化之分页探索详细介绍的文章就介绍到这了,更多相关MySQL分页探索内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Oracle与Mysql主键、索引及分页的区别小结
区别: 1.主键,Oracle不可以实现自增,mysql可以实现自增. oracle新建序列,SEQ_USER_Id.nextval 2.索引: mysql索引从0开始,Oracle从1开始. 3.分页, mysql: select * from user order by desc limit n ,m. 表示,从第n条数据开始查找,一共查找m条数据. Oracle:select * from user select rownum a * from ((select * from user)a
-

MySQL索引优化之分页探索详细介绍
目录 MySQL索引优化之分页探索 案例一 案例二 MySQL索引优化之分页探索 表结构 CREATE TABLE `demo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL DEFAULT '' COMMENT '姓名', `age` int(11) NOT NULL DEFAULT '0'
-
MySQL 索引优化案例
目录 数据准备 联合索引的首字段用范围查询 强制走索引 覆盖索引优化 in和or什么时候会走索引 like xx% 一般都会走索引,和数据量无关 索引下推 为什么范围查找没有用索引下推优化? 如何选择索引 Trace 工具 深入优化 order by 和 group by 优化总结 Using filesort文件排序原理详解 单路排序模式: 双路排序(又叫回表排序模式) 分页优化 常规的limit分页 优化 根据主键排序 非主键排序的优化 表关联优化 常见的表关联算法 内嵌循环连接算法 基于块
-
MySQL索引优化Explain详解
在日常工作中,我们会有时会开慢查询去记录一些执行时间比较久的SQL语句,找出这些SQL语句并不意味着完事了,些时我们常常用到explain这个命令来查看一个这些SQL语句的执行计划,查看该SQL语句有没有使用上了索引,有没有做全表扫描,这都可以通过explain命令来查看.所以我们深入了解MySQL的基于开销的优化器,还可以获得很多可能被优化器考虑到的访问策略的细节,以及当运行SQL语句时哪种策略预计会被优化器采用. -- 实际SQL,查找用户名为Jefabc的员工 select * from
-
MySQL索引优化实例分析
目录 1.数据准备 2.实例一 3.MySQL如何选择合适的索引? 4.常见 SQL 深入优化 4.1.Order by与Group by优化 4.2.分页查询优化 4.3.join关联查询优化 4.3.1.数据准备 4.3.2.MySQL 表关联常见的两种算法 4.4.in和exsits优化 4.5.count(*)查询优化 5.索引设计原则 1.数据准备 #1.建立员工表,并创建name,age,position索引,id为自增主键 CREATE TABLE `employees` ( `
-
oracle数据库关于索引建立及使用的详细介绍
索引的说明 索引是与表相关的一个可选结构,在逻辑上和物理上都独立于表的数据,索引能优化查询,不能优化DML操作,Oracle自动维护索引,频繁的DML操作反而会引起大量的索引维护. 如果SQL语句仅访问被索引的列,那么数据库只需从索引中读取数据,而不用读取表. 如果该语句同时还要访问除索引列之外的列,那么,数据库会使用rowid来查找表中的行. 通常,为检索表数据,数据库以交替方式先读取索引块,然后读取相应的表块. 索引的目的 主要是减少IO,这是本质,这样才能体现索引的效率. 1大表,返回的行
-
MySQL索引优化之不适合构建索引及索引失效的几种情况详解
目录 结论 不建议建立索引的场景 索引失效的场景 小结 结论 具体案例下文有详尽描述 不适合建立索引的场景: 数据量比较小的表不建议建立索引 有大量重复数据的字段上不建议建立索引(类似:性别字段) 需要进行频繁更新的表不建议建立索引 where.group by.order by后面的没有使用到的字段不建立索引 不要定义冗余索引 索引失效的场景: 过滤条件使用不等于(!=.<>) 过滤条件使用is not null 在索引字段上使用函数或进行计算 在使用联合索引的时候,需要满足“最佳左前缀法则
-
MySQL索引优化之适合构建索引的几种情况详解
目录 结论 建立索引的场景 小结 结论 在where后面的过滤字段上建立索引(select/update/delete后面的where都是适用的),使用索引加快过滤效率,不用进行全表扫描 在具有唯一要求的字段上添加唯一索引,加快查询效率,查到即可直接返回 group by或者order by后面的字段添加索引,由于索引是排好序的,所以建立索引就等同于在查询之前已经是排好序了(这里需要注意建立的联合索引建立中字段的顺序,可以结合具体案例场景7进行学习) 在DISTINCT(去重字段)后面的字段添加
-
浅谈MySQL索引优化分析
为什么你写的sql查询慢?为什么你建的索引常失效?通过本章内容,你将学会MySQL性能下降的原因,索引的简介,索引创建的原则,explain命令的使用,以及explain输出字段的意义.助你了解索引,分析索引,使用索引,从而写出更高性能的sql语句.还在等啥子?撸起袖子就是干! 案例分析 我们先简单了解一下非关系型数据库和关系型数据库的区别. MongoDB是NoSQL中的一种.NoSQL的全称是Not only SQL,非关系型数据库.它的特点是性能高,扩张性强,模式灵活,在高并发场景表现得尤
-
MySQL索引优化的实际案例分析
Order by desc/asc limit M是我在mysql sql优化中经常遇到的一种场景,其优化原理也非常的简单,就是利用索引的有序性,优化器沿着索引的顺序扫描,在扫描到符合条件的M行数据后,停止扫描:看起来非常的简单,但是我经常看到很多性能较差的sql没有利用这个优化规律,下面将结合一些实际的案例来分析说明: 案例一: 一条sql执行非常的慢,执行时间为: root@test 02:00:44 SELECT * FROM test_order_desc WHERE END_TIME>
-
开源MySQL高效数据仓库解决方案:Infobright详细介绍
Infobright是一款基于独特的专利知识网格技术的列式数据库.Infobright是开源的MySQL数据仓库解决方案,引入了列存储方案,高强度的数据压缩,优化的统计计算(类似sum/avg/group by之类),infobright 是基于mysql的,但不装mysql亦可,因为它本身就自带了一个.mysql可以粗分为逻辑层和物理存储引擎,infobright主要实现的就是一个存储引擎,但因为它自身存储逻辑跟关系型数据库根本不同,所以,它不能像InnoDB那样直接作为插件挂接到mysql,