Tensorflow中使用cpu和gpu有什么区别
目录
- 使用cpu和gpu的区别
- 一些术语的比较(tensorflow和pytorch/cpu和gpu/)
- tensorflow和pytorch
- cpu和gpu
- cuda
使用cpu和gpu的区别
在Tensorflow中使用gpu和cpu是有很大的差别的。在小数据集的情况下,cpu和gpu的性能差别不大。
不过在大数据集的情况下,cpu的时间显著增加,而gpu变化并不明显。
不过,我的笔记本电脑的风扇终于全功率运行了。
import tensorflow as tf
import timeit
import numpy as np
import matplotlib.pyplot as plt
def cpu_run(num):
with tf.device('/cpu:0'):
cpu_a=tf.random.normal([1,num])
cpu_b=tf.random.normal([num,1])
c=tf.matmul(cpu_a,cpu_b)
return c
def gpu_run(num):
with tf.device('/gpu:0'):
gpu_a=tf.random.normal([1,num])
gpu_b=tf.random.normal([num,1])
c=tf.matmul(gpu_a,gpu_b)
return c
k=10
m=7
cpu_result=np.arange(m,dtype=np.float32)
gpu_result=np.arange(m,dtype=np.float32)
x_time=np.arange(m)
for i in range(m):
k=k*10
x_time[i]=k
cpu_str='cpu_run('+str(k)+')'
gpu_str='gpu_run('+str(k)+')'
#print(cpu_str)
cpu_time=timeit.timeit(cpu_str,'from __main__ import cpu_run',number=10)
gpu_time=timeit.timeit(gpu_str,'from __main__ import gpu_run',number=10)
# 正式计算10次,取平均时间
cpu_time=timeit.timeit(cpu_str,'from __main__ import cpu_run',number=10)
gpu_time=timeit.timeit(gpu_str,'from __main__ import gpu_run',number=10)
cpu_result[i]=cpu_time
gpu_result[i]=gpu_time
print(cpu_result)
print(gpu_result)
fig, ax = plt.subplots()
ax.set_xscale("log")
ax.set_adjustable("datalim")
ax.plot(x_time,cpu_result)
ax.plot(x_time,gpu_result)
ax.grid()
plt.draw()
plt.show()
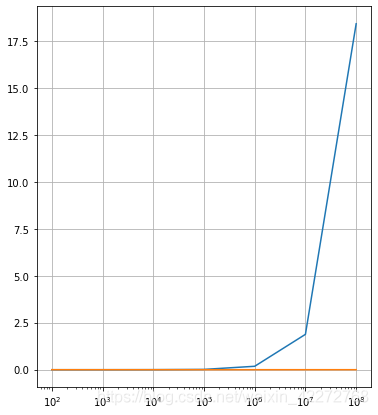
蓝线是cpu的耗时,而红线是gpu的耗时。
一些术语的比较(tensorflow和pytorch/cpu和gpu/)
tensorflow和pytorch
- pytorch是一个动态框架,tensorflow是一个静态框架。
- tensorflow是一个静态框架体现在:需要先构建一个tensorflow的计算图,构建好之后这样的一个计算图是不能变的,然后再传入不同的数据进去进行计算。
- 这种静态框架带来的问题是:固定了计算的流程,势必带来不灵活性,如果要改变计算的逻辑或者是随着时间变化的计算逻辑,这样的动态计算tensorflow是是无法实现的。
- pytorch是一个动态框架,和python的逻辑一样,对变量做任何操作都是灵活的。
- 一个好的框架需要具备三点:(1)对大的计算图能方便的实现(2)能自动求变量的导数(3)能简单的运行在GPU上。这三点pytorch都可以达到
- tensorflow在gpu上的分布式计算更为出色,在数据量巨大的时候效率比pytorch要高。企业很多都是用的tensorflow,pytorch在学术科研上使用多些。
- pytorch包括三个层次:tensor/variable/module。tensor即张量的意思,由于是矩阵的运算,所以适合在矩阵上跑。variable就是tensor的封装,封装的目的就是为了能够保存住该variable在整个计算图中的位置,能够知道计算图中各个变量之间的相互依赖关系,这样就能够反向求梯度。module是一个更高的层次,是一个神经网络的层次,可以直接调用全连接层、卷积层等神经网络。
cpu和gpu
- cpu更少的核,但是单个核的计算能力很强
- gpu:更多的核,每个核的计算能力不如cpu,所以更适合做并行计算,如矩阵计算,深度学习就是很多的矩阵计算。
cuda
- 直接写cuda代码就类似写汇编语言
- 比cuda高级的是cudnn
- 比cudnn高级的是用框架tensorflow/caffe/pytorch
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Window10上Tensorflow的安装(CPU和GPU版本)
之前摸索tensorflow的时候安装踩坑的时间非常久,主要是没搞懂几个东西的关系,就在瞎调试,以及当时很多东西不懂,很多报错也一知半解的.这次重装系统后正好需要再配置一次,把再一次的经历记录一下.我的电脑是华为的matebook13,intel i5-8625U,MX250显卡,win10系统.(不得不吐槽很垃圾,只能满足测试测试调调代码的需求) 深度学习利用Tensorflow平台,其中的Keras Sequential API对新用户非常的友好,可以将各基础组件组合在一起来构建模型. (官
-
使用Tensorflow-GPU禁用GPU设置(CPU与GPU速度对比)
禁用GPU设置 # 在import tensorflow之前 import os os.environ['CUDA_VISIBLE_DEVICES'] = '-1' CPU与GPU对比 显卡:GTX 1066 CPU GPU 简单测试:GPU比CPU快5秒 补充知识:tensorflow使用CPU可以跑(运行),但是使用GPU却不能用的情况 在跑的时候可以让加些选项: with tf.Session(config=tf.ConfigProto(allow_soft_placement=True,
-
tensorflow指定CPU与GPU运算的方法实现
1.指定GPU运算 如果安装的是GPU版本,在运行的过程中TensorFlow能够自动检测.如果检测到GPU,TensorFlow会尽可能的利用找到的第一个GPU来执行操作. 如果机器上有超过一个可用的GPU,除了第一个之外的其他的GPU默认是不参与计算的.为了让TensorFlow使用这些GPU,必须将OP明确指派给他们执行.with......device语句能够用来指派特定的CPU或者GPU执行操作: import tensorflow as tf import numpy as np w
-
用gpu训练好的神经网络,用tensorflow-cpu跑出错的原因及解决方案
训练的时候当然用gpu,速度快呀. 我想用cpu版的tensorflow跑一下,结果报错,这个错误不太容易看懂. 大概意思是没找到一些节点. 后来发现原因,用gpu和cpu保存的pb模型不太一样,但是checkpoints文件是通用的. 使用tensorflow-cpu再把checkpoints文件重新转换一下pb文件就可以了. 完美解决! 补充:tensflow-gpu版的无数坑坑坑!(tf坑大总结) 自己的小本本,之前预装有的pycharm+win10+anaconda3+python3的环
-
详解tf.device()指定tensorflow运行的GPU或CPU设备实现
在tensorflow中,我们可以使用 tf.device() 指定模型运行的具体设备,可以指定运行在GPU还是CUP上,以及哪块GPU上. 设置使用GPU 使用 tf.device('/gpu:1') 指定Session在第二块GPU上运行: import tensorflow as tf with tf.device('/gpu:1'): v1 = tf.constant([1.0, 2.0, 3.0], shape=[3], name='v1') v2 = tf.constant([1.0
-
卸载tensorflow-cpu重装tensorflow-gpu操作
问题描述:为了把之前的CPU版本的tensorflow卸载,换成GPU版本的tensorflow,经历了一番折腾. BUG1 Could not install packages due to an EnvironmentError: [WinError 5] 拒绝访问 看指向的路径,感觉是在安装路径的site-packages中已经存在tensorflow文件夹了,但是执行 pip uninstall tensorflow 却提示没有安装,于是手动删除该文件夹,重新安装,此bug修复. BUG
-
Tensorflow中使用cpu和gpu有什么区别
目录 使用cpu和gpu的区别 一些术语的比较(tensorflow和pytorch/cpu和gpu/) tensorflow和pytorch cpu和gpu cuda 使用cpu和gpu的区别 在Tensorflow中使用gpu和cpu是有很大的差别的.在小数据集的情况下,cpu和gpu的性能差别不大. 不过在大数据集的情况下,cpu的时间显著增加,而gpu变化并不明显. 不过,我的笔记本电脑的风扇终于全功率运行了. import tensorflow as tf import timeit
-
在tensorflow中设置使用某一块GPU、多GPU、CPU的操作
tensorflow下设置使用某一块GPU(从0开始编号): import os os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID" os.environ["CUDA_VISIBLE_DEVICES"] = "1" 多GPU: num_gpus = 4 for i in range(num_gpus): with tf.device('/gpu:%d',%i): ... 只是用cpu的
-
运行tensorflow python程序,限制对GPU和CPU的占用操作
一般情况下,运行tensorflow时,默认会占用可以看见的所有GPU,那么就会导致其它用户或程序无GPU可用,那么就需要限制程序对GPU的占用.并且,一般我们的程序也用不了所有的GPU资源,只是强行霸占着,大部分资源都不会用到,也不会提升运行速度. 使用nvidia-smi可以查看本机的GPU使用情况,如下图,这里可以看出,本机的GPU型号是K80,共有两个K80,四块可用(一个K80包括两块K40). 1.如果是只需要用某一块或某几块GPU,可以在运行程序时,利用如下命令运行:CUDA_VI
-
对Tensorflow中Device实例的生成和管理详解
1. 关键术语描述 kernel 在神经网络模型中,每个node都定义了自己需要完成的操作,比如要做卷积.矩阵相乘等. 可以将kernel看做是一段能够跑在具体硬件设备上的算法程序,所以即使同样的2D卷积算法,我们有基于gpu的Convolution 2D kernel实例.基于cpu的Convolution 2D kernel实例. device 负责运行kernel的具体硬件设备抽象.每个device实例,对应系统中一个具体的处理器硬件,比如gpu:0 device, gpu:1 devic
-
Tensorflow中tf.ConfigProto()的用法详解
参考Tensorflow Machine Leanrning Cookbook tf.ConfigProto()主要的作用是配置tf.Session的运算方式,比如gpu运算或者cpu运算 具体代码如下: import tensorflow as tf session_config = tf.ConfigProto( log_device_placement=True, inter_op_parallelism_threads=0, intra_op_parallelism_threads=0,
-
深入理解Tensorflow中的masking和padding
TensorFlow是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor).它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等.TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的
-
解决pip安装tensorflow中出现的no module named tensorflow.python 问题方法
由于本博文的浏览量已经破万了,看了一下是自己很久以前写的了,刚开始写博客,感觉废话一大堆.为了不浪费大家的时间,这里就直接说怎么解决问题的吧. 其实就是我自己装了一个python-pip,至于是自己下的安装包安装的还是python2自带的我也忘了,然后后来应该是又装了一个python3,结果用pip install tensorflow 就出现了这个问题,总之就是因为执行这个命令的时候,pip没将tensorflow装在python3的目录里,然后用的时候调用的python3,所以导致找不到.所
-
在Tensorflow中实现梯度下降法更新参数值
我就废话不多说了,直接上代码吧! tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy) TensorFlow经过使用梯度下降法对损失函数中的变量进行修改值,默认修改tf.Variable(tf.zeros([784,10])) 为Variable的参数. train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy,var_list=