MySQL 配置主从复制实践分享
目录
- 一、检测通信
- 二、master配置
- 1. 开启二进制日志
- 2. 创建一个用于主从库通信用的账号
- 3. 获取binlog的日志文件名和position
- 三、slave配置
- 1. 配置全局唯一的server-id
- 2. 使用master创建的账户读取binlog同步数据
- 3. 开启slave服务
- 四、配置中可能出现的问题
- 1. 网络连接问题
- 2. binlog的position问题
- 3. SQL线程出错
一、检测通信
查看主库(master)和从库(slave)的ip地址,并检测是否可以通信

保证master和slave之间网络是互通的,用ping命令检测

到这里我们知道,master的ip为192.168.131.129,slave的ip为192.168.0.6,并且可以相互通信。保证3306端口开放


查看防火墙状态systemctl status firewalld.service
临时手动启动防火墙systemctl start firewalld.service
临时手动停止防火墙systemctl stop firewalld.service
持久打开防火墙(重启服务生效)systemctl enable firewalld.service
持久关闭防火墙(重启服务生效)systemctl disable firewalld.service
查看当前开放的端口列表firewall-cmd --list-ports
二、master配置
1. 开启二进制日志
配置log_bin和全局唯一的server-id,和slave区分开,不能配置成一样的(如果是my.cnf新添加配置,一定要重启MySQL服务)
vim /etc/my.cnf打开my.cnf文件

2. 创建一个用于主从库通信用的账号
即在master中创建一个账号,用于slave登录master读取binlog
虽然我们在Linux上查看的ip地址是192.168.131.129,但我们创建账户登录时不写这个ip,写的是192.168.131.1。因为我这里虚拟机用的是NAT模式(如果是桥接模式就可以直接用了),虚拟机(master)和物理机(slave)通信的时候,虚拟机先把数据发送到网关192.168.131.1(默认与VMnet8通信),192.168.131.1再转发到物理机,所以物理机接收到的是192.168.131.1的数据,故我们在master上为slave创建账户的时候,应该写192.168.131.1

如果给slave配置的不是网关192.168.131.1地址,vim + /var/log/mysqld.log打开错误日志会有如下信息:

这说的就是从192.168.131.1的mslave权限不够,那是因为我们在master配置的是允许从其他地方登录,并不允许从192.168.131.1地址登录,导致权限不够。
由于master这边收到的是来自192.168.131.1的请求,所以错误日志显示的是192.168.131.1
创建用户的命令:
//如果嫌麻烦可以用%代替192.168.131.1,,它就可以匹配任何ip mysql> CREATE USER 'mslave'@'192.168.131.1' IDENTIFIED BY '1qaz@WSX'; //启动主从,在主库上给当前的mslave用户开启REPLICATION SLAVE主从复制的权限,从库就可以通过1qaz@WSX账户密码 //从192.168.131.1 IP地址来请求访问这台主库上的任意库里面的任意表*.*,同步这个主库的任意库里的任意表 mysql> GRANT REPLICATION SLAVE ON *.* to 'mslave'@'192.168.131.1' IDENTIFIED BY '1qaz@WSX'; mysql> FLUSH PRIVILEGES;
3. 获取binlog的日志文件名和position
show master status

三、slave配置
1. 配置全局唯一的server-id

配置全局唯一的server-id

涉及修改配置文件,需要重启MySQL服务

2. 使用master创建的账户读取binlog同步数据
这一步配置主要是给IO线程读取binlog使用:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.131.129', MASTER_PORT=3306, MASTER_USER='mslave', MASTER_PASSWORD='1qaz@WSX', MASTER_LOG_FILE='mysql-bin.000006', MASTER_LOG_POS=1262;
- MASTER_HOST:指定master的ip
- MASTER_LOG_FILE:binlog文件名
- MASTER_LOG_POS:binlog的position
3. 开启slave服务
通过show slave status命令查看主从复制状态,show processlist查看master和salve相关线程的运行状态
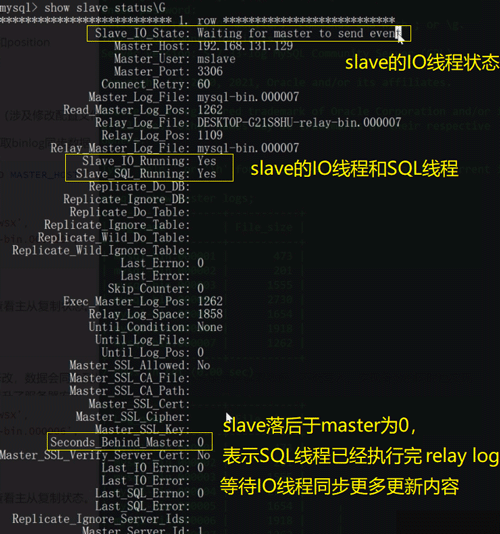
四、配置中可能出现的问题
1. 网络连接问题
通过show slave status命令查看主从复制状态

连接connection错粗,先考虑网络是否互通,ping一下:
然后再检查从库里面的配置信息是否正确

如果都正确,检查主库所在机器的3306端口是否正常
telnet xxx.xxx.xxx.xxx 3306
如果发现3306端口不能连通,就需要怀疑主库对端口有限制吗,也就是防火墙限制,就需要在防火墙把3306端口开放出来。
如果这个错误还没解决,就查看一个主库的错误日志/var/log/mysql/mysqld.log,查看错误日志中提示的ip是否和自己允许slave登录的ip一致

这说的就是从192.168.131.1的mslave权限不够,自己玩的时候,如果虚拟机是NAT模式,则需要写成VMnet8网关ip。如果都是物理机通信,那直接写正确的ip即可
可以在MySQL数据库下的mysql库的user表中更改允许登录的ip

然后重新赋予权限:
mysql> GRANT REPLICATION SLAVE ON *.* to 'mslave'@'xxx.xxx.xxx.xxx' IDENTIFIED BY '1qaz@WSX';
2. binlog的position问题

在master中查看show master status一下binlog日志文件名以及position,然后用命令重新配置slave,比如:
mysql> CHANGE MASTER TO MASTER_HOST='192.168.131.129',MASTER_PORT=3306,MASTER_USER='mslave',MASTER_PASSWORD='1qaz@WSX', MASTER_LOG_FILE='mysql-bin.000006',MASTER_LOG_POS=1262;
配置slave前需要stop slave,配置完成再start slave
3. SQL线程出错

错误原因:首先配置主从复制的时候,slave的mytest库中没有user表,而master的mytest库已经有user表了。配置好主从复制后直接drop table mytest.user,这就会写到binlog里面,然后在通过dump线程和IO线程将这个操作发送到从库的relay log,然后从库的SQL线程从relay log里把drop table mytest.user捞出来在从库执行这个SQL,可从库的mytest根本就没有user表,这就是删除一个不存在的表,于是出现错误了。
一般我们是不会做这样的操作的,我们一般都是主库配置以后,slave从数据开始增量进行同步,不会同步以后一开始就删主库里的东西,如果真的出现这样的问题了,随时可以通过show slave status来查看主从库的状态来解决错误,如果是上图这个错误,
(1)可以在从库stop slave,然后把位置重新设置一下,然后再start slave,相当于重新开始主从同步的位置。
(2)可以在从库stop slave,然后set global sql_slave_skip_counter=1;(跳过一个错误),然后再start slave重启从库的线程,相当于把错误跳过了,异常操作。
可以通过show slave status查看以下标识,IO线程出错一般是网络问题,SQL线程出错一般是SQL在slave库执行出现了问题

到此这篇关于MySQL 配置主从复制实践分享的文章就介绍到这了,更多相关MySQL 配置主从复制 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL 主从复制数据不一致的解决方法
目录 1. 准备工作 1.1 主机配置 1.2 从机配置 2. 数据不一致问题 3. 原因分析 4. 问题解决 5. 小结 今天来说说 MySQL 主从复制数据不一致的问题,通过几个具体的案例,来向小伙伴们展示 binlog 不同 format 之间的区别. 1. 准备工作 以下配置基于 Docker. 我这里有一张简单的图向大伙展示 MySQL 主从的工作方式: 这里,我们准备两台机器: 主机:10.3.50.27:33061 从机:10.3.50.27:33062 1.1 主机配置 主机的配
-
MySQL主从复制原理详情
目录 前言: 一.为什么需要主从复制? 二.什么是mysql的主从复制? 三.mysql复制原理 具体步骤 四.mysql主从同步延时分析 五.主从复制的配置 1.基础设置准备 2.安装mysql数据库 3.在两台数据库中分别创建数据库 4.在主(node1)服务器进行如下配置: 5.配置从(node2)服务器登录主服务器的账号授权 6.从(node2)服务器的配置 7.重启主服务器的mysqld服务 8.重启从服务器并进行相关配置 前言: 对于现在的系统来说,在业务复杂的系统中,数据库往往是应
-
MySQL数据库主从复制与读写分离
目录 一.主从复制 主从复制三线程 主从复制的过程: 主从复制的策略: 主从复制高延迟 二.读写分离 读写分离概念 读写分离原因与场景 总结 一.主从复制 主从复制:在实际的生产中,为了解决Mysql的单点故障以及提高MySQL的整体服务性能,一般都会采用主从复制.即:对数据库中的数据.语句做备份. 主从复制三线程 Mysql的主从复制中主要有三个线程:master(binlog dump thread).slave(I/O thread .SQL thread),M
-
MySQL的主从复制原理详细分析
目录 前言 一.主从复制概念 二.读写分离的概念 三.主库和从库 1. 主库 2. 从库 四.主从复制的流程 五.主从复制效果展示 前言 在实际生产环境中,如果对mysql数据库的读和写都在一台数据库服务器中操作,无论是在安全性.高可用性,还是高并发等各个方面都是不能满足实际需求的,一般要通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力. 一.主从复制概念 主从复制是MySQL提供的基本的技术,主从复制的流程:binlog二进制日志(除了查询其他的更改相关的操作都会记录在b
-
MySQL主从复制之半同步semi-sync replication
目录 一.半同步简介 二.两种模式介绍 三.两种方式比较 四.如何开启半同步 五.查看插件开启情况 六.开启半同步功能 七.查看半同步是否运行 八.半同步参数信息 九.半同步状态信息 十.测试一下半同步的同步情况 1.从节点暂时先关掉IO线程 2.主节点写入几条测试数据 3.等待10s后查看复制状态,半同步已经关掉了 4.从节点开启IO线程 5.再次查看复制状态,半同步复制自动开启了 一.半同步简介 MASTER节点在执行完客户端提交的事务后不是立刻返回结果给客户端,而是等待至少一个SLAVE节
-
MySQL主从复制之GTID模式详细介绍
目录 一.GTID概述 二.GTID相较与传统复制的优势 三.GTID自身存在哪些限制 四.GTID工作原理简单介绍 五.如何开启GTID复制 六.查看GTID相关参数 七.GTID与传统模式建立复制时候语句的不同点 八.GTID同步状态简单解析 一.GTID概述 MySQL5.6 在原有主从复制的基础上增加了一个新的复制方式,即基于GTID的复制方式,它由UUID和事务ID两个部分组成,具有如下特点. GTID事务是全局唯一性的,并且一个事务对应一个GTID值. 一个GTID值在同一个MySQ
-
Docker搭建MySQL5.7主从复制的实现
目录 1.新建mysql-master主服务器容器实例3307 2.新建mysql-master主服务器配置文件my.cnf 3 重启master实例 4 进入mysql-master容器 5 master容器实例内创建数据同步用户 6 新建mysql-slave从服务器实例3308 7 进入/usr/local/mysql-slave/conf目录下新建my.cnf 8 修改完配置后重启slave实例 9 在主数据库中查看主从同步状态 10 进入mysql-slave容器 11 在从数据库中配
-
MySQL主从复制问题总结及排查过程
目录 一.概述 二.mysql主从复制原理 1.MYSQL主从复制过程 三.问题及解决方法 1.show slave status \G 显示如下报错信息 2.根据提示信息定位报错位置 四.通用解决方法 1. 跳过指定数量的事务 2. 跳所有错误或指定类型的错误 一.概述 mysql主从是常用的高可用架构之一,也是使用最广泛的的系统架构.在生产环境中mysql主从复制有时会出现复制错误问题.MySQL主从复制中的问题(Coordinator stopped beacause there were
-
MySQL实现配置主从复制项目实践
目录 一.检测通信 二.master配置 1. 开启二进制日志 2. 创建一个用于主从库通信用的账号 3. 获取binlog文件名和position 三.slave配置 1. 配置全局唯一的server-id 2. 使用master创建的账户读取binlog同步数据 3. 开启slave服务 四.配置中可能出现的问题 1. 网络连接问题 2. binlog的position问题 3. SQL线程出错 一.检测通信 查看master(centos7)和slave(win10)的ip地址,并检测是否
-
MySQL 配置主从复制实践分享
目录 一.检测通信 二.master配置 1. 开启二进制日志 2. 创建一个用于主从库通信用的账号 3. 获取binlog的日志文件名和position 三.slave配置 1. 配置全局唯一的server-id 2. 使用master创建的账户读取binlog同步数据 3. 开启slave服务 四.配置中可能出现的问题 1. 网络连接问题 2. binlog的position问题 3. SQL线程出错 一.检测通信 查看主库(master)和从库(slave)的ip地址,并检测是否可以通信
-
mysql数据库 主从复制的配置方法
MySQL支持单向.异步复制,复制过程中一个服务器充当主服务器,而一个或多个其它服务器充当从服务器.主服务器将更新写入二进制日志文件,并维 护日志文件的一个索引以跟踪日志循环.当一个从服务器连接到主服务器时,它通知主服务器从服务器在日志中读取的最后一次成功更新的位置.从服务器接收从那 时起发生的任何更新,然后封锁并等待主服务器通知下一次更新. 为什么使用主从复制? 1.主服务器/从服务器设置增加了健壮性.主服务器出现问题时,你可以切换到从服务器作为备份. 2.通过在主服务器和从服务器之间切分处理
-
MySQL数据库主从复制延时超长的解决方法
前言 MySQL主从复制的延时一直是业界困扰已久的问题.延时的出现会降低主从读写分离的价值,不利于数据实时性较高的业务使用MySQL. UDB是UCloud推出的云数据库服务,上线已达六年,运营了数以万计的UDB MySQL实例.除了提供高可用.高性能.便捷易用的产品特性,团队还平均每天帮助用户解决2-3起MySQL实例主从复制延时的问题.从大量实践中我们总结了主从复制延时的各种成因和解决方法,现分享于此. 延时问题的重要性 主从复制机制广泛应用在UDB的内部实现中:UDB创建的从库和主库就采用
-
详解Redis主从复制实践
复制简介 Redis 作为一门非关系型数据库,其复制功能和关系型数据库(MySQL)来说,功能其实都是差不多,无外乎就是实现的原理不同.Redis 的复制功能也是相对于其他的内存性数据库(memcached)所具备特有的功能. Redis 复制功能主要的作用,是集群.分片功能实现的基础:同时也是 Redis 实现高可用的一种策略,例如解决单机并发问题.数据安全性等等问题. 服务介绍 在本文环境演示中,有一台主机,启动了两个 Redis 示例. 实现方式 Redis 复制实现方式分为下面三种方式:
-
详解使用Docker进行Redis主从复制实践
一.背景 最近在做零信任安全网关,需要使用Redis作为认证缓存服务器,因为网关服务器分布在多个集群,每次都跨机房认证不太实现:所以需要使用Redis主从同步,将过程记录下来,希望可以给需要的同学一点参考. 二.操作步骤 安装Docker 主服务配置 从服务配置 验证同步效果 三.安装Docker 本篇文章主要是问了记录主从配置的过程,因此我采用最简单的docker方式来搭建Redis服务,安装docker的命令如下所示 curl -sSL https://get.daocloud.io/doc
-
MySQL数据库主从复制原理及作用分析
目录 1.数据库主从分类: 2.mysql主从介绍由来 3.主从作用 4.主从复制原理 5.主从复制配置(数据一致时) 5.1主从服务器分别安装mysql5.7 5.2主数据库与从数据库数据一致 5.3在主数据库里创建一个同步账号授权给从数据库使用 5.4在从库上测试连接 5.5配置主数据库 5.6配置从数据库 5.7配置并启动主从复制的功能(mysql02从数据库上) 5.8测试: 主库: 从库: 主库创建数据库clq并且加入数据: 从库中查看: 6.主从配置(数据不一致时) 6.1一般全备主
-
kettle在windows上安装配置与实践案例
目录 第1章 kettle概述 1.1 什么是kettle 1.2 Kettle核心知识点 1.2.1 Kettle工程存储方式 1.2.2 Kettle的两种设计 1.2.3 Kettle的组成 1.3 kettle特点 第2章 kettle安装部署和使用 2.1 kettle安装地址 2.2 Windows下安装使用 2.2.1 概述 2.2.2 安装 2.2.3 案例 2.3 创建资源库 2.3.1 数据库资源库 2.3.2 文件资源库 第1章 kettle概述 1.1 什么是kettle
-
linux下安装apache与php;Apache+PHP+MySQL配置攻略
1.apache 在如下页面下载apache的for Linux 的源码包 http://www.apache.org/dist/httpd/; 存至/home/xx目录,xx是自建文件夹,我建了一个wj的文件夹. 命令列表: cd /home/wj tar -zxvf httpd-2.0.54.tar.gz mv httpd-2.0.54 apache cd apache ./configure --prefix=/usr/local/apache2 --enable-mod