python 还原梯度下降算法实现一维线性回归
首先我们看公式:
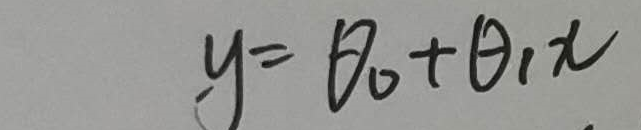
这个是要拟合的函数
然后我们求出它的损失函数, 注意:这里的n和m均为数据集的长度,写的时候忘了

注意,前面的theta0-theta1x是实际值,后面的y是期望值
接着我们求出损失函数的偏导数:
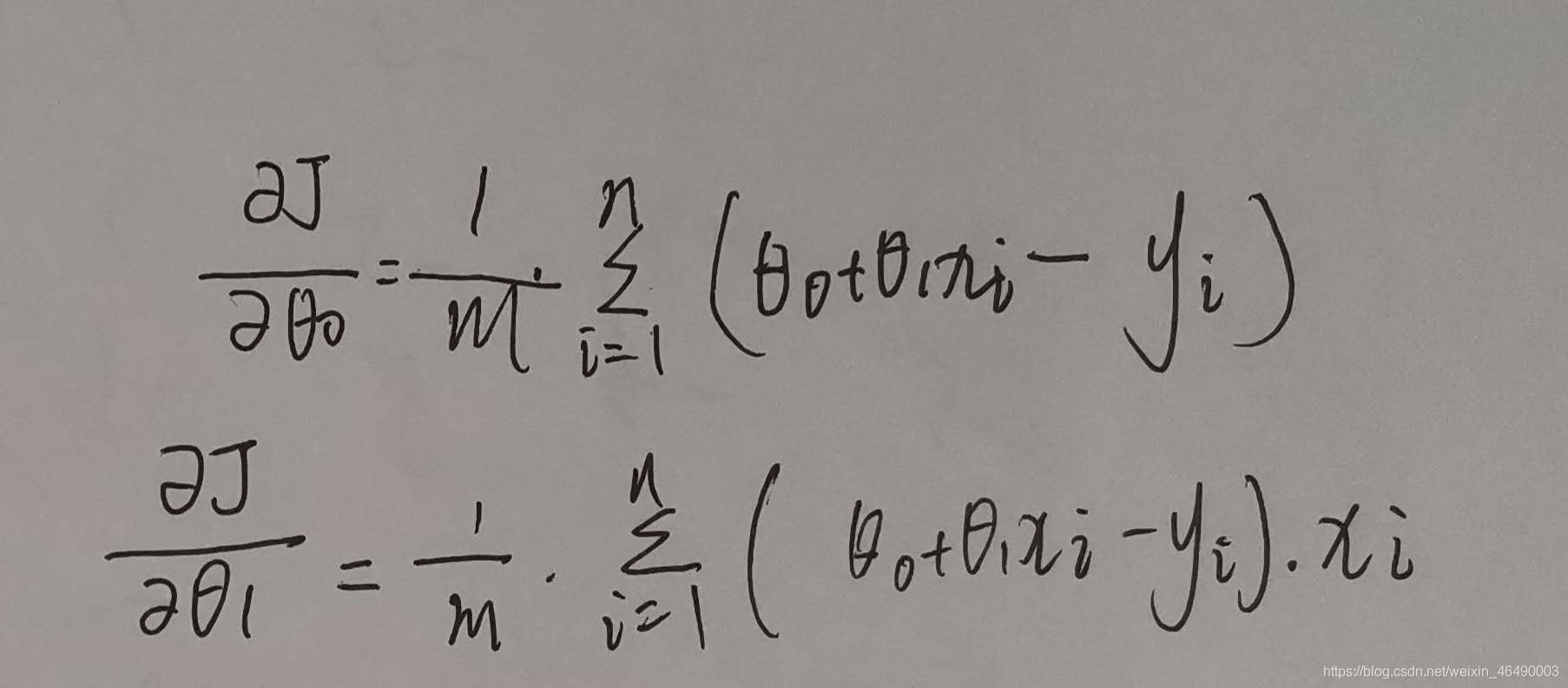
最终,梯度下降的算法:

学习率一般小于1,当损失函数是0时,我们输出theta0和theta1.
接下来上代码!
class LinearRegression():
def __init__(self, data, theta0, theta1, learning_rate):
self.data = data
self.theta0 = theta0
self.theta1 = theta1
self.learning_rate = learning_rate
self.length = len(data)
# hypothesis
def h_theta(self, x):
return self.theta0 + self.theta1 * x
# cost function
def J(self):
temp = 0
for i in range(self.length):
temp += pow(self.h_theta(self.data[i][0]) - self.data[i][1], 2)
return 1 / (2 * self.m) * temp
# partial derivative
def pd_theta0_J(self):
temp = 0
for i in range(self.length):
temp += self.h_theta(self.data[i][0]) - self.data[i][1]
return 1 / self.m * temp
def pd_theta1_J(self):
temp = 0
for i in range(self.length):
temp += (self.h_theta(data[i][0]) - self.data[i][1]) * self.data[i][0]
return 1 / self.m * temp
# gradient descent
def gd(self):
min_cost = 0.00001
round = 1
max_round = 10000
while min_cost < abs(self.J()) and round <= max_round:
self.theta0 = self.theta0 - self.learning_rate * self.pd_theta0_J()
self.theta1 = self.theta1 - self.learning_rate * self.pd_theta1_J()
print('round', round, ':\t theta0=%.16f' % self.theta0, '\t theta1=%.16f' % self.theta1)
round += 1
return self.theta0, self.theta1
def main():
data = [[1, 2], [2, 5], [4, 8], [5, 9], [8, 15]] # 这里换成你想拟合的数[x, y]
# plot scatter
x = []
y = []
for i in range(len(data)):
x.append(data[i][0])
y.append(data[i][1])
plt.scatter(x, y)
# gradient descent
linear_regression = LinearRegression(data, theta0, theta1, learning_rate)
theta0, theta1 = linear_regression.gd()
# plot returned linear
x = np.arange(0, 10, 0.01)
y = theta0 + theta1 * x
plt.plot(x, y)
plt.show()
到此这篇关于python 还原梯度下降算法实现一维线性回归 的文章就介绍到这了,更多相关python 一维线性回归 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
sklearn+python:线性回归案例
使用一阶线性方程预测波士顿房价 载入的数据是随sklearn一起发布的,来自boston 1993年之前收集的506个房屋的数据和价格.load_boston()用于载入数据. from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split import time from sklearn.linear_model import LinearRegression bosto
-
python用线性回归预测股票价格的实现代码
线性回归在整个财务中广泛应用于众多应用程序中.在之前的教程中,我们使用普通最小二乘法(OLS)计算了公司的beta与相对索引的比较.现在,我们将使用线性回归来估计股票价格. 线性回归是一种用于模拟因变量(y)和自变量(x)之间关系的方法.通过简单的线性回归,只有一个自变量x.可能有许多独立变量属于多元线性回归的范畴.在这种情况下,我们只有一个自变量即日期.对于第一个日期上升到日期向量长度的整数,该日期将由1开始的整数表示,该日期可以根据时间序列数据而变化.当然,我们的因变量将是股票的价格.为了理
-
python 机器学习之支持向量机非线性回归SVR模型
本文介绍了python 支持向量机非线性回归SVR模型,废话不多说,具体如下: import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm from sklearn.model_selection import train_test_split def load_data_regression(): ''' 加载用于回归问题的数据集 ''' diabetes =
-

Python线性回归实战分析
一.线性回归的理论 1)线性回归的基本概念 线性回归是一种有监督的学习算法,它介绍的自变量的和因变量的之间的线性的相关关系,分为一元线性回归和多元的线性回归.一元线性回归是一个自变量和一个因变量间的回归,可以看成是多远线性回归的特例.线性回归可以用来预测和分类,从回归方程可以看出自变量和因变量的相互影响关系. 线性回归模型如下: 对于线性回归的模型假定如下: (1) 误差项的均值为0,且误差项与解释变量之间线性无关 (2) 误差项是独立同分布的,即每个误差项之间相互独立且每个误差项的方差是相等的
-
Python编程实现使用线性回归预测数据
本文中,我们将进行大量的编程--但在这之前,我们先介绍一下我们今天要解决的实例问题. 1) 预测房子价格 房价大概是我们中国每一个普通老百姓比较关心的问题,最近几年保障啊,小编这点微末工资着实有点受不了. 我们想预测特定房子的价值,预测依据是房屋面积. 2) 预测下周哪个电视节目会有更多的观众 闪电侠和绿箭侠是我最喜欢的电视节目,特别是绿箭侠,当初追的昏天黑地的,不过后来由于一些原因,没有接着往下看.我想看看下周哪个节目会有更多的观众. 3) 替换数据集中的缺失值 我们经常要和带有缺失值的数据集
-
Python实现的简单线性回归算法实例分析
本文实例讲述了Python实现的简单线性回归算法.分享给大家供大家参考,具体如下: 用python实现R的线性模型(lm)中一元线性回归的简单方法,使用R的women示例数据,R的运行结果: > summary(fit) Call: lm(formula = weight ~ height, data = women) Residuals: Min 1Q Median 3Q Max -1.7333 -1.1333 -0.3833 0.7417 3.116
-
关于多元线性回归分析——Python&SPSS
原始数据在这里 1.观察数据 首先,用Pandas打开数据,并进行观察. import numpy import pandas as pd import matplotlib.pyplot as plt %matplotlib inline data = pd.read_csv('Folds5x2_pp.csv') data.head() 会看到数据如下所示: 这份数据代表了一个循环发电厂,每个数据有5列,分别是:AT(温度), V(压力), AP(湿度), RH(压强), PE(输出电力).我
-
python 还原梯度下降算法实现一维线性回归
首先我们看公式: 这个是要拟合的函数 然后我们求出它的损失函数, 注意:这里的n和m均为数据集的长度,写的时候忘了 注意,前面的theta0-theta1x是实际值,后面的y是期望值 接着我们求出损失函数的偏导数: 最终,梯度下降的算法: 学习率一般小于1,当损失函数是0时,我们输出theta0和theta1. 接下来上代码! class LinearRegression(): def __init__(self, data, theta0, theta1, learning_rate): se
-
python使用梯度下降算法实现一个多线性回归
python使用梯度下降算法实现一个多线性回归,供大家参考,具体内容如下 图示: import pandas as pd import matplotlib.pylab as plt import numpy as np # Read data from csv pga = pd.read_csv("D:\python3\data\Test.csv") # Normalize the data 归一化值 (x - mean) / (std) pga.AT = (pga.AT - pga
-
python实现梯度下降算法的实例详解
python版本选择 这里选的python版本是2.7,因为我之前用python3试了几次,发现在画3d图的时候会报错,所以改用了2.7. 数据集选择 数据集我选了一个包含两个变量,三个参数的数据集,这样可以画出3d图形对结果进行验证. 部分函数总结 symbols()函数:首先要安装sympy库才可以使用.用法: >>> x1 = symbols('x2') >>> x1 + 1 x2 + 1 在这个例子中,x1和x2是不一样的,x2代表的是一个函数的变量,而x1代表
-
python实现梯度下降算法
梯度下降(Gradient Descent)算法是机器学习中使用非常广泛的优化算法.当前流行的机器学习库或者深度学习库都会包括梯度下降算法的不同变种实现. 本文主要以线性回归算法损失函数求极小值来说明如何使用梯度下降算法并给出python实现.若有不正确的地方,希望读者能指出. 梯度下降 梯度下降原理:将函数比作一座山,我们站在某个山坡上,往四周看,从哪个方向向下走一小步,能够下降的最快. 在线性回归算法中,损失函数为 在求极小值时,在数据量很小的时候,可以使用矩阵求逆的方式求最优的θ值.但当数
-
python梯度下降算法的实现
本文实例为大家分享了python实现梯度下降算法的具体代码,供大家参考,具体内容如下 简介 本文使用python实现了梯度下降算法,支持y = Wx+b的线性回归 目前支持批量梯度算法和随机梯度下降算法(bs=1) 也支持输入特征向量的x维度小于3的图像可视化 代码要求python版本>3.4 代码 ''' 梯度下降算法 Batch Gradient Descent Stochastic Gradient Descent SGD ''' __author__ = 'epleone' import
-
python应用Axes3D绘图(批量梯度下降算法)
本文实例为大家分享了python批量梯度下降算法的具体代码,供大家参考,具体内容如下 问题: 将拥有两个自变量的二阶函数绘制到空间坐标系中,并通过批量梯度下降算法找到并绘制其极值点 大体思路: 首先,根据题意确定目标函数:f(w1,w2) = w1^2 + w2^2 + 2 w1 w2 + 500 然后,针对w1,w2分别求偏导,编写主方法求极值点 而后,创建三维坐标系绘制函数图像以及其极值点即可 具体代码实现以及成像结果如下: import numpy as np import matplot
-
利用Python实现最小二乘法与梯度下降算法
导入所需库 %matplotlib inline import sympy import numpy as np import matplotlib.pyplot as plt from sympy.abc import x as a,y as b 生成模拟数据 # 模拟函数 y=3x-1 #自变量 x=np.linspace(-5,5,num=1000) #加入噪声 noise=np.random.rand(len(x))*2-1 #因变量 y=3*x-1+noise 查看所生成数据的图像 p
-
图文详解梯度下降算法的原理及Python实现
目录 1.引例 2.数值解法 3.梯度下降算法 4.代码实战:Logistic回归 1.引例 给定如图所示的某个函数,如何通过计算机算法编程求f(x)min? 2.数值解法 传统方法是数值解法,如图所示 按照以下步骤迭代循环直至最优: ① 任意给定一个初值x0: ② 随机生成增量方向,结合步长生成Δx: ③ 计算比较f(x0)与f(x0+Δx)的大小,若f(x0+Δx)<f(x0)则更新位置,否则重新生成Δx: ④ 重复②③直至收敛到最优f(x)min. 数值解法最大的优点是编程简明,但缺陷也很
-
PyTorch搭建一维线性回归模型(二)
PyTorch基础入门二:PyTorch搭建一维线性回归模型 1)一维线性回归模型的理论基础 给定数据集,线性回归希望能够优化出一个好的函数,使得能够和尽可能接近. 如何才能学习到参数和呢?很简单,只需要确定如何衡量与之间的差别,我们一般通过损失函数(Loss Funciton)来衡量:.取平方是因为距离有正有负,我们于是将它们变为全是正的.这就是著名的均方误差.我们要做的事情就是希望能够找到和,使得: 均方差误差非常直观,也有着很好的几何意义,对应了常用的欧式距离.现在要求解这个连续函数的最小
-
python实现简单的单变量线性回归方法
线性回归是机器学习中的基础算法之一,属于监督学习中的回归问题,算法的关键在于如何最小化代价函数,通常使用梯度下降或者正规方程(最小二乘法),在这里对算法原理不过多赘述,建议看吴恩达发布在斯坦福大学上的课程进行入门学习. 这里主要使用python的sklearn实现一个简单的单变量线性回归. sklearn对机器学习方法封装的十分好,基本使用fit,predict,score,来训练,预测,评价模型, 一个简单的事例如下: from pandas import DataFrame from pan