在PyTorch中使用标签平滑正则化的问题
什么是标签平滑?在PyTorch中如何去使用它?
在训练深度学习模型的过程中,过拟合和概率校准(probability calibration)是两个常见的问题。一方面,正则化技术可以解决过拟合问题,其中较为常见的方法有将权重调小,迭代提前停止以及丢弃一些权重等。另一方面,Platt标度法和isotonic regression法能够对模型进行校准。但是有没有一种方法可以同时解决过拟合和模型过度自信呢?
标签平滑也许可以。它是一种去改变目标变量的正则化技术,能使模型的预测结果不再仅为一个确定值。标签平滑之所以被看作是一种正则化技术,是因为它可以防止输入到softmax函数的最大logits值变得特别大,从而使得分类模型变得更加准确。
在这篇文章中,我们定义了标签平滑化,在测试过程中我们将它应用到交叉熵损失函数中。
标签平滑?
假设这里有一个多分类问题,在这个问题中,目标变量通常是一个one-hot向量,即当处于正确分类时结果为1,否则结果是0。
标签平滑改变了目标向量的最小值,使它为ε。因此,当模型进行分类时,其结果不再仅是1或0,而是我们所要求的1-ε和ε,从而带标签平滑的交叉熵损失函数为如下公式。
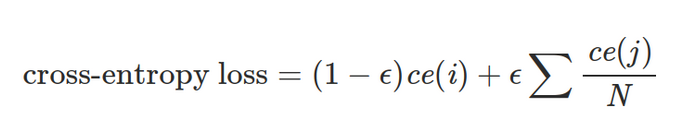
在这个公式中,ce(x)表示x的标准交叉熵损失函数,例如:-log(p(x)),ε是一个非常小的正数,i表示对应的正确分类,N为所有分类的数量。
直观上看,标记平滑限制了正确类的logit值,并使得它更接近于其他类的logit值。从而在一定程度上,它被当作为一种正则化技术和一种对抗模型过度自信的方法。
PyTorch中的使用
在PyTorch中,带标签平滑的交叉熵损失函数实现起来非常简单。首先,让我们使用一个辅助函数来计算两个值之间的线性组合。
deflinear_combination(x, y, epsilon):return epsilon*x + (1-epsilon)*y
下一步,我们使用PyTorch中一个全新的损失函数:nn.Module.
import torch.nn.functional as F
defreduce_loss(loss, reduction='mean'):return loss.mean() if reduction=='mean'else loss.sum() if reduction=='sum'else loss
classLabelSmoothingCrossEntropy(nn.Module):def__init__(self, epsilon:float=0.1, reduction='mean'):
super().__init__()
self.epsilon = epsilon
self.reduction = reduction
defforward(self, preds, target):
n = preds.size()[-1]
log_preds = F.log_softmax(preds, dim=-1)
loss = reduce_loss(-log_preds.sum(dim=-1), self.reduction)
nll = F.nll_loss(log_preds, target, reduction=self.reduction)
return linear_combination(loss/n, nll, self.epsilon)
我们现在可以在代码中删除这个类。对于这个例子,我们使用标准的fast.ai pets example.
from fastai.vision import *
from fastai.metrics import error_rate
# prepare the data
path = untar_data(URLs.PETS)
path_img = path/'images'
fnames = get_image_files(path_img)
bs = 64
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$'
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs) \
.normalize(imagenet_stats)
# train the model
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.loss_func = LabelSmoothingCrossEntropy()
learn.fit_one_cycle(4)
最后将数据转换成模型可以使用的格式,选择ResNet架构并以带标签平滑的交叉熵损失函数作为优化目标。经过四轮循环后,其结果如下
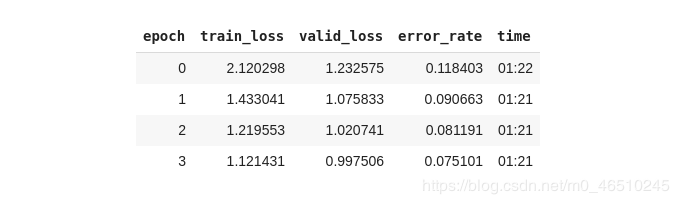
我们所得结果的错误率仅为7.5%,这对于10行左右的代码来说是完全可以接受的,并且在模型中大多数参数还都选择的是默认设置。
因此,在模型中还有许多参数可以进行调整,从而使得模型的表现性能更好,例如:可以使用不同的优化器、超参数、模型架构等。
结论
在这篇文章中,我们了解了什么是标签平滑以及什么时候去使用它,并且我们还知道了如何在PyTorch中实现它。之后,我们训练了一个先进的计算机视觉模型,仅使用十行代码就识别出了不同品种的猫和狗。
模型正则化和模型校准是两个重要的概念。若想成为一个深度学习的资深玩家,就应该好好地去理解这些能够对抗过拟合和模型过度自信的工具。
作者简介: Dimitris Poulopoulos,是BigDataStack的一名机器学习研究员,同时也是希腊Piraeus大学的博士。曾为欧盟委员会、欧盟统计局、国际货币基金组织、欧洲央行等客户设计过与AI相关的软件。
总结
到此这篇关于如何在PyTorch中使用标签平滑正则化的文章就介绍到这了,更多相关PyTorch正则化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch标签转onehot形式实例
代码: import torch class_num = 10 batch_size = 4 label = torch.LongTensor(batch_size, 1).random_() % class_num print(label.size()) one_hot = torch.zeros(batch_size, class_num).scatter_(1, label, 1) print(one_hot) 输出: torch.Size([4, 1]) tensor([[0., 0.,
-
pytorch实现onehot编码转为普通label标签
label转onehot的很多,但是onehot转label的有点难找,所以就只能自己实现以下,用的topk函数,不知道有没有更好的实现 one_hot = torch.tensor([[0,0,1],[0,1,0],[0,1,0]]) print(one_hot) label = torch.topk(one_hot, 1)[1].squeeze(1) print(label) tensor([[0, 0, 1], [0, 1, 0], [0, 1, 0]]) tensor([2, 1, 1]
-
在PyTorch中使用标签平滑正则化的问题
什么是标签平滑?在PyTorch中如何去使用它? 在训练深度学习模型的过程中,过拟合和概率校准(probability calibration)是两个常见的问题.一方面,正则化技术可以解决过拟合问题,其中较为常见的方法有将权重调小,迭代提前停止以及丢弃一些权重等.另一方面,Platt标度法和isotonic regression法能够对模型进行校准.但是有没有一种方法可以同时解决过拟合和模型过度自信呢? 标签平滑也许可以.它是一种去改变目标变量的正则化技术,能使模型的预测结果不再仅为一个确定值.
-

Pytorch中的数据集划分&正则化方法
1.训练集&验证集&测试集 训练集:训练数据 验证集:验证不同算法(比如利用网格搜索对超参数进行调整等),检验哪种更有效 测试集:正确评估分类器的性能 正常流程:验证集会记录每个时间戳的参数,在加载test数据前会加载那个最好的参数,再来评估.比方说训练完6000个epoch后,发现在第3520个epoch的validation表现最好,测试时会加载第3520个epoch的参数. import torch import torch.nn as nn import torch.nn.func
-
pytorch中常用的损失函数用法说明
1. pytorch中常用的损失函数列举 pytorch中的nn模块提供了很多可以直接使用的loss函数, 比如MSELoss(), CrossEntropyLoss(), NLLLoss() 等 官方链接: https://pytorch.org/docs/stable/_modules/torch/nn/modules/loss.html pytorch中常用的损失函数 损失函数 名称 适用场景 torch.nn.MSELoss() 均方误差损失 回归 torch.nn.L1Loss() 平
-
在Pytorch中使用样本权重(sample_weight)的正确方法
step: 1.将标签转换为one-hot形式. 2.将每一个one-hot标签中的1改为预设样本权重的值 即可在Pytorch中使用样本权重. eg: 对于单个样本:loss = - Q * log(P),如下: P = [0.1,0.2,0.4,0.3] Q = [0,0,1,0] loss = -Q * np.log(P) 增加样本权重则为loss = - Q * log(P) *sample_weight P = [0.1,0.2,0.4,0.3] Q = [0,0,sample_wei
-
在pytorch中为Module和Tensor指定GPU的例子
pytorch指定GPU 在用pytorch写CNN的时候,发现一运行程序就卡住,然后cpu占用率100%,nvidia-smi 查看显卡发现并没有使用GPU.所以考虑将模型和输入数据及标签指定到gpu上. pytorch中的Tensor和Module可以指定gpu运行,并且可以指定在哪一块gpu上运行,方法非常简单,就是直接调用Tensor类和Module类中的 .cuda() 方法. import torch from PIL import Image import torch.nn as
-
关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇. TensorFlow: 228--->266 Keras: 42--->56 Pytorch: 87--->252 在使用pytorch中,自己有一些思考,如下: 1. loss计算和反向传播 import torch.nn as nn
-
pytorch中的transforms模块实例详解
pytorch中的transforms模块中包含了很多种对图像数据进行变换的函数,这些都是在我们进行图像数据读入步骤中必不可少的,下面我们讲解几种最常用的函数,详细的内容还请参考pytorch官方文档(放在文末). data_transforms = transforms.Compose([ transforms.RandomResizedCrop(224), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms
-
pytorch中的自定义数据处理详解
pytorch在数据中采用Dataset的数据保存方式,需要继承data.Dataset类,如果需要自己处理数据的话,需要实现两个基本方法. :.getitem:返回一条数据或者一个样本,obj[index] = obj.getitem(index). :.len:返回样本的数量 . len(obj) = obj.len(). Dataset 在data里,调用的时候使用 from torch.utils import data import os from PIL import Image 数
-
pytorch中图像的数据格式实例
计算机视觉方面朋友都需要跟图像打交道,在pytorch中图像与我们平时在matlab中见到的图像数据格式有所不同.matlab中我们通常使用函数imread()来轻松地读入一张图像,我们在变量空间中可看到数据的存储方式是H x W x C的顺序(其中H.W.C分别表示图像的高.宽和通道数,通道数一般为RGB三通道),另外,其中的每一个数据都是[0,255]的整数. 在使用pytorch的时候,我们通常要使用pytorch中torchvision包下面的datasets模块和transforms模
-
在Pytorch中使用Mask R-CNN进行实例分割操作
在这篇文章中,我们将讨论mask R-CNN背后的一些理论,以及如何在PyTorch中使用预训练的mask R-CNN模型. 1.语义分割.目标检测和实例分割 之前已经介绍过: 1.语义分割:在语义分割中,我们分配一个类标签(例如.狗.猫.人.背景等)对图像中的每个像素. 2.目标检测:在目标检测中,我们将类标签分配给包含对象的包围框. 一个非常自然的想法是把两者结合起来.我们只想在一个对象周围识别一个包围框,并且找到包围框中的哪些像素属于对象. 换句话说,我们想要一个掩码,它指示(使用颜色或灰