python3+selenium获取页面加载的所有静态资源文件链接操作
软件版本:
python 3.7.2
selenium 3.141.0
pycharm 2018.3.5
具体实现流程如下,废话不多说,直接上代码:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
d = DesiredCapabilities.CHROME
chrome_options = Options()
#使用无头浏览器
chrome_options.add_argument('--headless')
chrome_options.add_argument('--user-agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36')
#浏览器启动默认最大化
chrome_options.add_argument("--start-maximized");
#该处替换自己的chrome驱动地址
browser = webdriver.Chrome("D://googleDever//chromedriver.exe",chrome_options=chrome_options,desired_capabilities=d)
browser.set_page_load_timeout(150)
browser.get("https://www.xxx.com")
#静态资源链接存储集合
urls = []
#获取静态资源有效链接
for log in browser.get_log('performance'):
if 'message' not in log:
continue
log_entry = json.loads(log['message'])
try:
#该处过滤了data:开头的base64编码引用和document页面链接
if "data:" not in log_entry['message']['params']['request']['url'] and 'Document' not in log_entry['message']['params']['type']:
urls.append(log_entry['message']['params']['request']['url'])
except Exception as e:
pass
print(urls)
打印结果为页面渲染时加载的静态资源文件链接:
[http://www.xxx.com/aaa.js,http://www.xxx.com/css.css]
以上代码为selenium获取页面加载过程中预加载的各类静态资源文件链接,使用该功能获取到链接后,使用其他插件进行可对资源进行下载!
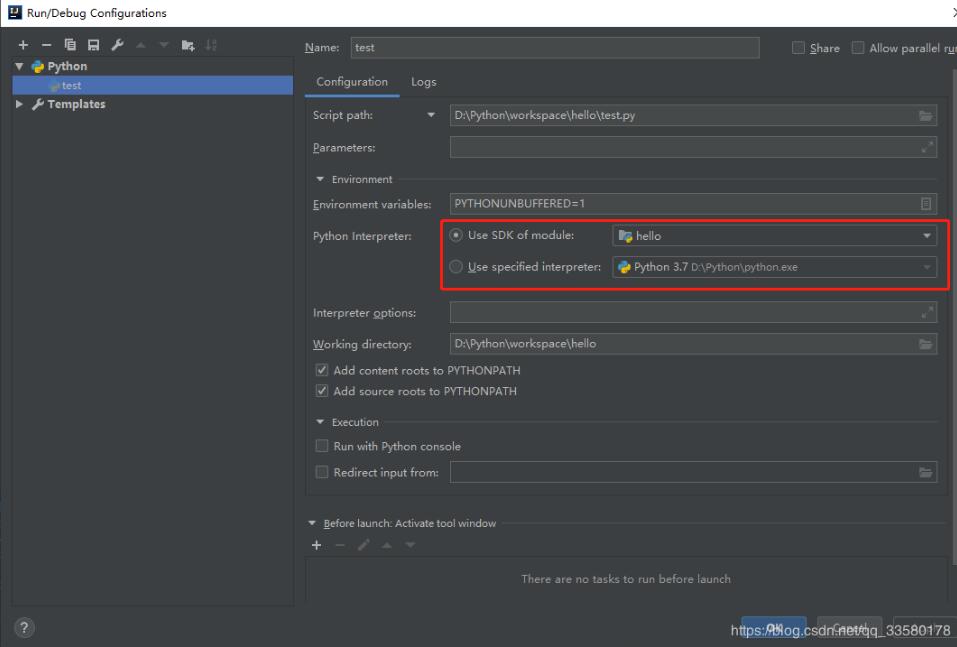
补充知识:在idea 中python import sys,import requests 报错
File->Project Structure
project -> sdk -> new -> ok
设置编译参数(主要是设置和检查Python JDK是否正确)
以上这篇python3+selenium获取页面加载的所有静态资源文件链接操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python使用selenium实现批量文件下载
背景 实现需求:批量下载联想某型号的全部驱动程序. 一般在做网络爬虫的时候,都是保存网页信息为主,或者下载单个文件.当涉及到多文件批量下载的时候,由于下载所需时间不定,下载的文件名不定,所以有一定的困难. 思路 参数配置 在涉及下载的时候,需要先对chromedriver进行参数配置,设定默认下载目录: global base_path profile = { 'download.default_directory': base_path } chrome_options = webdriver
-
python+selenium+chrome批量文件下载并自动创建文件夹实例
实现效果:通过url所绑定的关键名创建目录名,每次访问一个网页url后把文件下载下来 代码: 其中 data[i][0].data[i][1] 是代表 关键词(文件保存目录).网站链接(要下载文件的网站) def getDriverHttp(): for i in range(reCount): # 创建Chrome浏览器配置对象实例 chromeOptions = webdriver.ChromeOptions() # 设定下载文件的保存目录为d盘的tudi目录, # 如果该目录不存在,将会自
-
selenium获取当前页面的url、源码、title的方法
此篇博客学习的api如标题,分别是: current_url 获取当前页面的url: page_source 获取当前页面的源码: title 获取当前页面的title: 将以上方法按顺序练习一遍,效果如GIF: from selenium import webdriver from time import sleep sleep(2) driver = webdriver.Chrome() driver.get("https://www.baidu.com/") # 移动浏览器观看展
-
python selenium 获取标签的属性值、内容、状态方法
获取标签内容 使用element.attribute()方法获取dom元素的内容,如: dr = driver.find_element_by_id('tooltip') dr.get_attribute('data-original-title') #获取tooltip的内容 dr.text #获取该链接的text 获取标签属性 link=dr.find_element_by_id('tooltip') link.value_of_css_property('color') #获取toolti
-
python3+selenium获取页面加载的所有静态资源文件链接操作
软件版本: python 3.7.2 selenium 3.141.0 pycharm 2018.3.5 具体实现流程如下,废话不多说,直接上代码: from selenium import webdriver from selenium.webdriver.chrome.options import Options from selenium.webdriver.common.desired_capabilities import DesiredCapabilities d = Desired
-
vue 防止页面加载时看到花括号的解决操作
如下所示: <style> [v-cloak]{ display:none } </style> v-cloak v-text v-html v-cloak用于大段 v-text用于单个标签 v-html用于带有标签的处理 补充知识:vue花括号数据绑定不成功的问题 我就废话不多说了,大家还是直接看案例吧~ <!DOCTYPE html> <html> <head> <meta charset="utf-8" />
-
Android 加载assets中的资源文件实例代码
Android 加载assets资源 在android中,如何加载assets目录下的文件夹呢?方法很简单,使用 AssetManager, 即 AssetManager assetManager = getAssets(); 例子如下: AssetManager assetManager = getAssets(); try { String[] files = assetManager.list("Files"); for(int i=0; i<FILES.LENGTH; {
-
java selenium智能等待页面加载完成示例代码
java selenium 智能等待页面加载完成 我们经常会碰到用selenium操作页面上某个元素的时候, 需要等待页面加载完成后, 才能操作. 否则页面上的元素不存在,会抛出异常. 或者碰到AJAX异步加载,我们需要等待元素加载完成后, 才能操作 selenium 中提供了非常简单,智能的方法,来判断元素是否存在. 阅读目录 实例要求 隐式等待 显式等待 实例要求 实例:set_timeout.html 下面的html 代码, 点击click 按钮5秒后, 页面上会出现一个红色的div
-
Python selenium页面加载慢超时的解决方案
开发环境: win10-64 python2.7.16 chrome77 from selenium import webdriver driver = webdriver.Chrome(executable_path='chromedriver.exe') driver.get('http://全部加载完成超级慢的网站') user = 'abc' pwd = '123 driver.find_element_by_id('email').send_keys(user) driver.fi
-

js实现的页面加载完毕之前loading提示效果完整示例【附demo源码下载】
本文实例讲述了js实现的页面加载完毕之前loading提示效果.分享给大家供大家参考,具体如下: 一.JS代码: //获取浏览器页面可见高度和宽度 var _PageHeight = document.documentElement.clientHeight, _PageWidth = document.documentElement.clientWidth; //计算loading框距离顶部和左部的距离(loading框的宽度为215px,高度为61px) var _LoadingTop =
-
JavaScript判断页面加载完之后再执行预定函数的技巧
JavaScript 脚本语言的执行,是需要触发的.一般的做法就是在网页中,直接编写几个函数,有的在代码被加载的时候就被浏览器处理,或者使用类似下面的代码来触发实现函数的相关功能. <div id="link" onclick="fun()" ></div> 上面代码的意思就是,当鼠标点击 id 为 link 的元素的时候,就触发了它的 onclick 事件,然后执行使用 JavaScript 定义的 fun 函数.这样的做法肯定是很不合理的
-
完美解决JS文件页面加载时的阻塞问题
关于页面加载时的时间消费,许多书中都做出了介绍,也提出了很多种方法.本文章就详细介绍XHR注入. 概述:JS分拆的方法 1.XHR注入:就是用ajax异步请求同域包含脚本的文件,然后将返回的字符串转化为脚本使用,该方法不会造成页面渲染和onload事件的阻塞,因为是异步处理,推荐使用. 2.iframe注入:加载一个iframe框架,通过使用iframe框架中的脚本来避免src方式加载脚本的阻塞,但是iframe元素开销较大,不推荐. 3.DOM注入:就是创建script元素,通过制定该元素的s
-
Javascript代码在页面加载时的执行顺序介绍
一.在HTML中嵌入Javasript的方法1.直接在Javascript代码放在标记对<script>和</script>之间2.由<script />标记的src属性制定外部的js文件3.放在事件处理程序中,比如:<p onclick="alert('我是由onclick事件执行的Javascript')">点击我</p>4.作为URL的主体,这个URL使用特殊的Javascript:协议,比如:<a href=&q
-
jquery实现在页面加载完毕后获取图片高度或宽度
日前,本技术屌丝又遇到了一个很有意思的问题,应项目要求,需要在页面加载完毕之后获取图片的高度,以此来调整图片上面的覆盖层相对于图片顶端的位置. 但在jquery(function(){ /*XXXXXX*/});里面写了之后发现不是很理想,因为当jquery准备就绪的时候,此时图片绝大部分情况下都没加载完毕,这可急坏了本屌丝~~~T~T 本屌丝就想啊,要是jquery有个跟js的onload()的方法多好啊,擦~真是天上掉下个大狗屎,恰巧砸到本屌丝~~在网上搜了下,还真有这么个方法,写法如下: