Python机器学习NLP自然语言处理基本操作词向量模型
目录
- 概述
- 词向量
- 词向量维度
- Word2Vec
- CBOW 模型
- Skip-Gram 模型
- 负采样模型
- 词向量的训练过程
- 1. 初始化词向量矩阵
- 2. 神经网络反向传播
- 词向量模型实战
- 训练模型
- 使用模型
概述
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.

词向量
我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量.
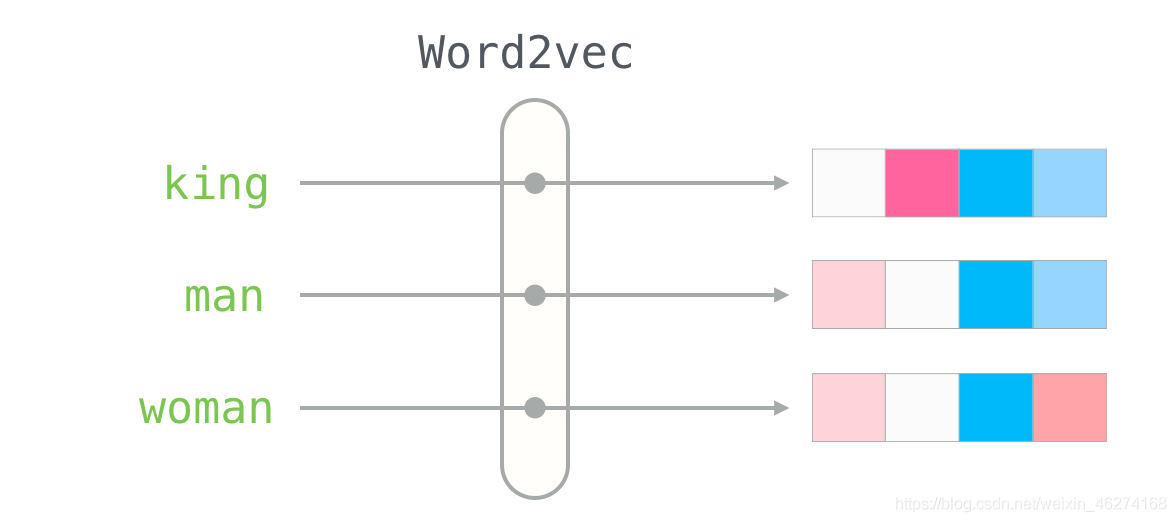
当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量我们就可以使用不同方法来计算相似度.

那我们如何来描述语言的特征呢? 我们把语言分割成一个个词, 然后在词的层面上构建特征.

词向量维度
词向量的维度越高, 其所能提供的信息也就越多, 计算结果的可靠性就更值得信赖.
50 维的词向量:

用热度图表示一下:


从上图我们可以看出, 相似的词在特征表达中比较相似. 由此也可以证明词的特征是有意义的.
Word2Vec
Word2Vec 是一个经过预训练的 2 层神经网络, 可以帮助我们将单词转换为向量. Word2Vec 分为两种学习的方法: CBOW 和 Skip-Gram.

CBOW 模型
CBOW (Continuous Bag-of-Words) 是根据单词周围的上下文来预测中间的词. 如图:

Skip-Gram 模型
Skip-Gram 用于预测同一句子中当前单词前后的特定范围内的单词.

Skip-Gram 所需的训练数据集:


负采样模型
如果一个语料库稍微大一些, 可能的结果简直太多了. 词向量模型的最后一层相当于 softmax (转换为概率), 计算起来会非常耗时.
我们可以将输入改成两个单词, 判断这两个词是否为前后对应的输入和输出, 即一个二分类任务.


但是我们会发现一个问题, 此时的训练集构建出来的标签全为 1, 无法进行较好的训练. 这时候负采样模型就派上用场了. (默认为 5 个)


词向量的训练过程
1. 初始化词向量矩阵
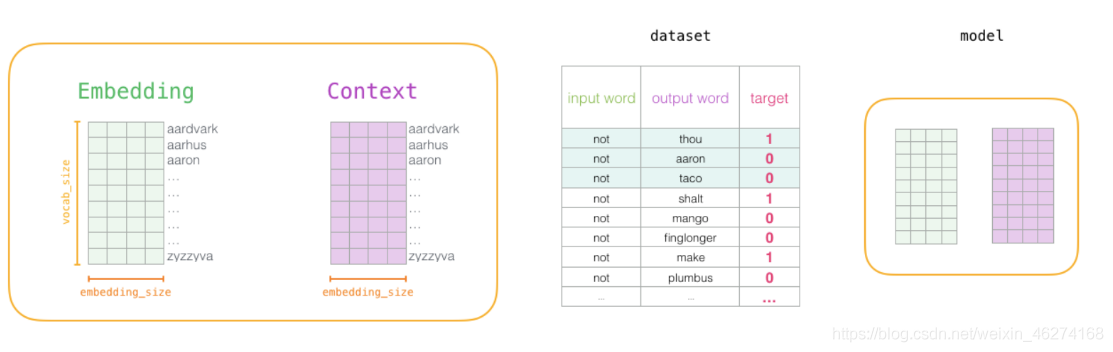

2. 神经网络反向传播
通过神经网络反向传播来计算更新. 此时不光更新权重参数矩阵 W, 也会更新输入数据.

词向量模型实战
格式:
Word2Vec(tokenized, sg=1, window=5, min_count=2, negative=1, sample=0.001, hs=1, workers=4)
参数:
seg: 1 为skip-gram算法, 对低配词敏感. 默认 sg=0, CBOW算法
window: 句子中当前词与目标词时间的最大距离. 3表示在目标词前看3-b个词, 后面看b个词 (b在0-3之间随机)
min_count: 对词进行过滤, 频率小于min-cout的单词会被忽视, 默认值为5
训练模型
import jieba
from gensim.models import Word2Vec
# 获取停用词
file = open("../stop_words/cn_stopwords.txt", encoding="utf-8")
stop_word = set(file.read())
print("停用词:", stop_word) # 调试输出
# 定义语料
content = [
"长江是中国第一大河,干流全长6397公里(以沱沱河为源),一般称6300公里。流域总面积一百八十余万平方公里,年平均入海水量约九千六百余亿立方米。以干流长度和入海水量论,长江均居世界第三位。",
"黄河,中国古代也称河,发源于中华人民共和国青海省巴颜喀拉山脉,流经青海、四川、甘肃、宁夏、内蒙古、陕西、山西、河南、山东9个省区,最后于山东省东营垦利县注入渤海。干流河道全长5464千米,仅次于长江,为中国第二长河。黄河还是世界第五长河。",
"黄河,是中华民族的母亲河。作为中华文明的发祥地,维系炎黄子孙的血脉.是中华民族民族精神与民族情感的象征。",
"黄河被称为中华文明的母亲河。公元前2000多年华夏族在黄河领域的中原地区形成、繁衍。",
"在兰州的“黄河第一桥”内蒙古托克托县河口镇以上的黄河河段为黄河上游。",
"黄河上游根据河道特性的不同,又可分为河源段、峡谷段和冲积平原三部分。 ",
"黄河,是中华民族的母亲河。"
]
# 分词
seg = [jieba.lcut(sentence) for sentence in content]
# 去除停用词 & 标点符号操作
tokenized = []
for sentence in seg:
words = []
for word in sentence:
if word not in stop_word & {'(', ')'}:
words.append(word)
tokenized.append(words)
print(tokenized) # 调试输出
# 创建模型
model = Word2Vec(tokenized, sg=1, window=5, min_count=2, negative=1, sample=0.001, hs=1, workers=4)
# 保存模型
model.save("model")
输出结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\Windows\AppData\Local\Temp\jieba.cache
停用词: {'它', '算', '比', '庶', '针', '乎', '相', '幸', '上', '慢', '叫', '傥', '时', '出', '尔', '吱', '着', '要', '身', '所', '大', '?', '是', '家', '介', '几', '随', '由', '况', '”', '像', '有', '儿', '归', '果', '简', '唷', '您', '啦', '间', '止', '仅', '啊', '喂', '步', '待', ' ', '岂', '料', '二', '或', '结', '乃', '竟', '人', '方', '若', '无', '3', '哼', '6', '鉴', '莫', '谁', '会', '们', '吗', '呸', '让', '根', '固', '惟', '致', '余', '就', '乘', '拿', '啐', '换', '循', '次', '哩', '代', '死', '类', '\n', '经', '始', '问', '较', ':', '咧', '否', '令', '登', '首', '许', '云', '尚', '得', '这', '诸', '夫', '罢', '见', '多', '种', '嘿', '该', '然', '小', '除', '虽', '两', '呀', '己', '极', '天', '前', '咦', '进', '设', '望', '对', '彼', '徒', '反', '咚', '$', '哎', '唉', '呼', '哒', '受', '直', '据', '连', '体', '哇', '宁', '?', '遵', '言', '任', '今', '点', '凭', '紧', '俺', '独', '如', '旦', '正', '哦', '下', '已', '打', '接', '呃', '》', '可', '在', '边', '纵', '何', '叮', '矣', '每', '过', '沿', '则', '尽', '样', '愿', '!', '全', '呗', '0', '值', '非', '《', '另', '转', '给', '成', '年', '切', '特', '往', '恰', '5', '巴', '处', '依', '嗳', '哪', '悉', '拘', '到', '些', '眨', '赖', '巧', '逐', '眼', '自', '2', '说', '此', '越', '基', '消', '哧', '至', '哗', '很', '毋', '用', '省', '般', '借', '。', '还', '曰', '最', ',', '冒', '述', '诚', '光', '兼', '啥', '个', '呵', '别', '其', '免', '曾', '继', '怎', '先', '甚', '使', '譬', '8', '呜', '再', '鄙', '抑', '候', '了', '总', '以', '他', '都', '倘', '一', '截', '离', '作', '冲', '啪', '道', '分', '喻', '靠', '因', '等', '什', '达', '嘘', '朝', '按', '句', '话', '者', '及', '管', '故', '关', '外', '喽', '孰', '兮', '向', '限', '面', '没', '加', '顺', '咳', '贼', '么', '亦', '里', '奈', '各', '照', '呕', '“', '之', '万', '于', '似', '9', '我', '而', '7', '少', '从', '怕', '地', '论', '哉', ';', '去', '某', '又', '_', '4', '将', '把', '和', '能', '呢', '犹', '来', '也', '阿', '啷', '便', '与', '内', '好', '本', '吧', '齐', '知', '单', '欤', '唯', '跟', '吓', '喔', '第', '部', '喏', '却', '嗡', '那', '为', '距', '嗬', '1', '起', '咋', '嘛', '被', '即', '并', '哟', '嗯', '、', '仍', '位', '嘻', '趁', '哈', '凡', '例', '腾', '乌', '焉', '替', '且', '假', '但', '漫', '办', '同', '才', '中', '她', '旧', '真', '妨', '开', '既', '通', '难', '赶', '咱', '确', '看', '你', '综', '期', '只', '临', '具', '肯', '旁', '后', '嘎', '的', '当', '不'}
Loading model cost 1.641 seconds.
Prefix dict has been built successfully.
[['长江', '是', '中国', '第一', '大河', ',', '干流', '全长', '6397', '公里', '(', '以', '沱沱河', '为源', ')', ',', '一般', '称', '6300', '公里', '。', '流域', '总面积', '一百八十', '余万平方公里', ',', '年', '平均', '入海', '水量', '约', '九千', '六百余', '亿立方米', '。', '以', '干流', '长度', '和', '入海', '水量', '论', ',', '长江', '均', '居', '世界', '第三位', '。'], ['黄河', ',', '中国', '古代', '也', '称河', ',', '发源', '于', '中华人民共和国', '青海省', '巴颜喀拉山', '脉', ',', '流经', '青海', '、', '四川', '、', '甘肃', '、', '宁夏', '、', '内蒙古', '、', '陕西', '、', '山西', '、', '河南', '、', '山东', '9', '个', '省区', ',', '最后', '于', '山东省', '东营', '垦利县', '注入', '渤海', '。', '干流', '河道', '全长', '5464', '千米', ',', '仅次于', '长江', ',', '为', '中国', '第二', '长河', '。', '黄河', '还是', '世界', '第五', '长河', '。'], ['黄河', ',', '是', '中华民族', '的', '母亲河', '。', '作为', '中华文明', '的', '发祥地', ',', '维系', '炎黄子孙', '的', '血脉', '.', '是', '中华民族', '民族', '精神', '与', '民族', '情感', '的', '象征', '。'], ['黄河', '被', '称为', '中华文明', '的', '母亲河', '。', '公元前', '2000', '多年', '华夏', '族', '在', '黄河', '领域', '的', '中原地区', '形成', '、', '繁衍', '。'], ['在', '兰州', '的', '“', '黄河', '第一', '桥', '”', '内蒙古', '托克托县', '河口镇', '以上', '的', '黄河', '河段', '为', '黄河', '上游', '。'], ['黄河', '上游', '根据', '河道', '特性', '的', '不同', ',', '又', '可', '分为', '河源', '段', '、', '峡谷', '段', '和', '冲积平原', '三', '部分', '。', ' '], ['黄河', ',', '是', '中华民族', '的', '母亲河', '。']]
使用模型
from gensim.models import Word2Vec
# 加载模型
model = Word2Vec.load("model")
# 判断相似度
sim1 = model.wv.similarity("黄河", "长江")
print(sim1)
sim2 = model.wv.similarity("黄河", "黄河")
print(sim2)
# 预测最接近的人
most_similar = model.wv.most_similar(positive=["黄河", "母亲河"], negative=["长江"])
print(most_similar)
输出结果:
0.20415045
0.99999994
[('公里', 0.15817636251449585), ('上游', 0.15374179184436798), ('入海', 0.15248821675777435), ('干流', 0.15130287408828735), ('的', 0.14548806846141815), ('是', 0.11208685487508774), ('段', 0.09545847028493881), ('为', 0.0872812420129776), ('于', 0.05294770747423172), ('长河', 0.02978350967168808)]
以上就是Python机器学习NLP自然语言处理基本操作词向量模型的详细内容,更多关于NLP自然语言处理的资料请关注我们其它相关文章!
相关推荐
-

Python机器学习NLP自然语言处理基本操作关键词
目录 概述 关键词 TF-IDF 关键词提取 TF IDF TF-IDF jieba TF-IDF 关键词抽取 jieba 词性 不带关键词权重 附带关键词权重 TextRank 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 关键词 关键词 (keywords), 即关键词语. 关键词能描述文章的本质, 在文献检索, 自动文摘, 文本聚类 / 分类等方面有着重要的应用. 关键词抽
-
Python机器学习NLP自然语言处理基本操作新闻分类
目录 概述 TF-IDF 关键词提取 TF IDF TF-IDF TfidfVectorizer 数据介绍 代码实现 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. TF-IDF 关键词提取 TF-IDF (Term Frequency-Inverse Document Frequency), 即词频-逆文件频率是一种用于信息检索与数据挖掘的常用加权技术. TF-IDF 可以帮助我
-
Python机器学习NLP自然语言处理Word2vec电影影评建模
目录 概述 词向量 词向量维度 代码实现 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量. 当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量
-
浅谈Python NLP入门教程
正文 本文简要介绍Python自然语言处理(NLP),使用Python的NLTK库.NLTK是Python的自然语言处理工具包,在NLP领域中,最常使用的一个Python库. 什么是NLP? 简单来说,自然语言处理(NLP)就是开发能够理解人类语言的应用程序或服务. 这里讨论一些自然语言处理(NLP)的实际应用例子,如语音识别.语音翻译.理解完整的句子.理解匹配词的同义词,以及生成语法正确完整句子和段落. 这并不是NLP能做的所有事情. NLP实现 搜索引擎: 比如谷歌,Yahoo等.谷歌搜索引
-
Python机器学习NLP自然语言处理基本操作之精确分词
目录 概述 分词器 jieba 安装 精确分词 全模式 搜索引擎模式 获取词性 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 分词器 jieba jieba 算法基于前缀词典实现高效的词图扫描, 生成句子中汉字所有可能成词的情况所构成的有向无环图. 通过动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词采用了基于汉字成词能力的 HMM 模型, 使用 Viter
-
Python机器学习NLP自然语言处理基本操作词向量模型
目录 概述 词向量 词向量维度 Word2Vec CBOW 模型 Skip-Gram 模型 负采样模型 词向量的训练过程 1. 初始化词向量矩阵 2. 神经网络反向传播 词向量模型实战 训练模型 使用模型 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了.
-
Python机器学习NLP自然语言处理基本操作词袋模型
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词袋模型 词袋模型 (Bag of Words Model) 能帮助我们把一个句子转换为向量表示. 词袋模型把文本看作是无序的词汇集合, 把每一单词都进行统计. 向量化 词袋模型首先会进行分词, 在分词之后. 通过通过统计在每个词在文本中出现的次数. 我们就可以得到该文本基于词语的特征, 如果将各个文本样本的这些词与对应的词频放在一起
-
Python机器学习NLP自然语言处理基本操作之Seq2seq的用法
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. Seq2seq Seq2seq 由 Encoder 和 Decoder 两个 RNN 组成. Encoder 将变长序列输出, 编码成 encoderstate 再由 Decoder 输出变长序列. Seq2seq 的使用领域: 机器翻译: Encoder-Decoder 的最经典应用 文本摘要: 输入是一段文本序列, 输出是这段文本
-
Python机器学习NLP自然语言处理基本操作电影影评分析
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天天气真好&
-
Python机器学习NLP自然语言处理基本操作家暴归类
目录 概述 数据介绍 词频统计 朴素贝叶斯 代码实现 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 数据介绍 该数据是家庭暴力的一份司法数据.分为 4 个不同类别: 报警人被老公打,报警人被老婆打,报警人被儿子打,报警人被女儿打. 今天我们就要运用我们前几次学到的知识, 来实现一个 NLP 分类问题. 词频统计 CountVectorizer是一个文本特征提取的方
-
Python机器学习NLP自然语言处理基本操作之京东评论分类
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 数据介绍 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天
-
Python机器学习NLP自然语言处理基本操作之命名实例提取
目录 概述 命名实例 HMM 随机场 马尔科夫随机场 CRF 命名实例实战 数据集 crf 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 命名实例 命名实例 (Named Entity) 指的是 NLP 任务中具有特定意义的实体, 包括人名, 地名, 机构名, 专有名词等. 举个例子: Luke Rawlence 代表人物 Aiimi 和 University o