python实战项目scrapy管道学习爬取在行高手数据
目录
- 爬取目标站点分析
- 编码时间
- 爬取结果展示
爬取目标站点分析
本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。

本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。
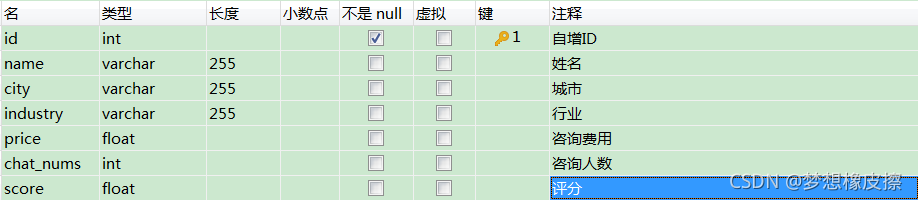
对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。
class ZaihangItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field() # 姓名
city = scrapy.Field() # 城市
industry = scrapy.Field() # 行业
price = scrapy.Field() # 价格
chat_nums = scrapy.Field() # 聊天人数
score = scrapy.Field() # 评分
编码时间
项目的创建过程参考上一案例即可,本文直接从采集文件开发进行编写,该文件为 zh.py。
本次目标数据分页地址需要手动拼接,所以提前声明一个实例变量(字段),该字段为 page,每次响应之后,判断数据是否为空,如果不为空,则执行 +1 操作。
请求地址模板如下:
https://www.zaih.com/falcon/mentors?first_tag_id=479&first_tag_name=心理&page={}
当页码超过最大页数时,返回如下页面状态,所以数据为空状态,只需要判断 是否存在 class=empty 的 section 即可。

解析数据与数据清晰直接参考下述代码即可。
import scrapy
from zaihang_spider.items import ZaihangItem
class ZhSpider(scrapy.Spider):
name = 'zh'
allowed_domains = ['www.zaih.com']
page = 1 # 起始页码
url_format = 'https://www.zaih.com/falcon/mentors?first_tag_id=479&first_tag_name=%E5%BF%83%E7%90%86&page={}' # 模板
start_urls = [url_format.format(page)]
def parse(self, response):
empty = response.css("section.empty") # 判断数据是否为空
if len(empty) > 0:
return # 存在空标签,直接返回
mentors = response.css(".mentor-board a") # 所有高手的超链接
for m in mentors:
item = ZaihangItem() # 实例化一个对象
name = m.css(".mentor-card__name::text").extract_first()
city = m.css(".mentor-card__location::text").extract_first()
industry = m.css(".mentor-card__title::text").extract_first()
price = self.replace_space(m.css(".mentor-card__price::text").extract_first())
chat_nums = self.replace_space(m.css(".mentor-card__number::text").extract()[0])
score = self.replace_space(m.css(".mentor-card__number::text").extract()[1])
# 格式化数据
item["name"] = name
item["city"] = city
item["industry"] = industry
item["price"] = price
item["chat_nums"] = chat_nums
item["score"] = score
yield item
# 再次生成一个请求
self.page += 1
next_url = format(self.url_format.format(self.page))
yield scrapy.Request(url=next_url, callback=self.parse)
def replace_space(self, in_str):
in_str = in_str.replace("\n", "").replace("\r", "").replace("¥", "")
return in_str.strip()
开启 settings.py 文件中的 ITEM_PIPELINES,注意类名有修改
ITEM_PIPELINES = {
'zaihang_spider.pipelines.ZaihangMySQLPipeline': 300,
}
修改 pipelines.py 文件,使其能将数据保存到 MySQL 数据库中
在下述代码中,首先需要了解类方法 from_crawler,该方法是 __init__ 的一个代理,如果其存在,类被初始化时会被调用,并得到全局的 crawler,然后通过 crawler 就可以获取 settings.py 中的各个配置项。
除此之外,还存在一个 from_settings 方法,一般在官方插件中也有应用,示例如下所示。
@classmethod
def from_settings(cls, settings):
host= settings.get('HOST')
return cls(host)
@classmethod
def from_crawler(cls, crawler):
# FIXME: for now, stats are only supported from this constructor
return cls.from_settings(crawler.settings)
在编写下述代码前,需要提前在 settings.py 中写好配置项。
settings.py 文件代码
HOST = "127.0.0.1" PORT = 3306 USER = "root" PASSWORD = "123456" DB = "zaihang"
pipelines.py 文件代码
import pymysql
class ZaihangMySQLPipeline:
def __init__(self, host, port, user, password, db):
self.host = host
self.port = port
self.user = user
self.password = password
self.db = db
self.conn = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('HOST'),
port=crawler.settings.get('PORT'),
user=crawler.settings.get('USER'),
password=crawler.settings.get('PASSWORD'),
db=crawler.settings.get('DB')
)
def open_spider(self, spider):
self.conn = pymysql.connect(host=self.host, port=self.port, user=self.user, password=self.password, db=self.db)
def process_item(self, item, spider):
# print(item)
# 存储到 MySQL
name = item["name"]
city = item["city"]
industry = item["industry"]
price = item["price"]
chat_nums = item["chat_nums"]
score = item["score"]
sql = "insert into users(name,city,industry,price,chat_nums,score) values ('%s','%s','%s',%.1f,%d,%.1f)" % (
name, city, industry, float(price), int(chat_nums), float(score))
print(sql)
self.cursor = self.conn.cursor() # 设置游标
try:
self.cursor.execute(sql) # 执行 sql
self.conn.commit()
except Exception as e:
print(e)
self.conn.rollback()
return item
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
管道文件中三个重要函数,分别是 open_spider,process_item,close_spider。
# 爬虫开启时执行,只执行一次
def open_spider(self, spider):
# spider.name = "橡皮擦" # spider对象动态添加实例变量,可以在spider模块中获取该变量值,比如在 parse(self, response) 函数中通过self 获取属性
# 一些初始化动作
pass
# 处理提取的数据,数据保存代码编写位置
def process_item(self, item, spider):
pass
# 爬虫关闭时执行,只执行一次,如果爬虫运行过程中发生异常崩溃,close_spider 不会执行
def close_spider(self, spider):
# 关闭数据库,释放资源
pass
爬取结果展示

以上就是python实战项目scrapy管道学习爬取在行高手数据的详细内容,更多关于python scrapy管道学习爬取在行的资料请关注我们其它相关文章!
相关推荐
-

一步步教你用python的scrapy编写一个爬虫
介绍 本文将介绍我是如何在python爬虫里面一步一步踩坑,然后慢慢走出来的,期间碰到的所有问题我都会详细说明,让大家以后碰到这些问题时能够快速确定问题的来源,后面的代码只是贴出了核心代码,更详细的代码暂时没有贴出来. 流程一览 首先我是想爬某个网站上面的所有文章内容,但是由于之前没有做过爬虫(也不知道到底那个语言最方便),所以这里想到了是用python来做一个爬虫(毕竟人家的名字都带有爬虫的含义
-
python实战scrapy操作cookie爬取博客涉及browsercookie
browsercookie 知识铺垫 第一个要了解的知识点是使用 browsercookie 获取浏览器 cookie ,该库使用命令 pip install browsercookie 安装即可. 接下来获取 firefox 浏览器的 cookie,不使用 chrome 谷歌浏览器的原因是在 80 版本之后,其 cookie 的加密方式进行了修改,所以使用 browsercookie 模块会出现如下错误 win32crypt must be available to decrypt Chrom
-
python编程scrapy简单代码实现搜狗图片下载器
学习任何编程技术,都要有紧有送,今天这篇博客就到了放松的时候了,我们学习一下如何用 scrapy 下载图片吧. 目标站点说明 这次要采集的站点为搜狗图片频道,该频道数据由接口直接返回,接口如下: https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&category=feed&start=10&len=10 https://pic.sogou.com/napi/pc/recommend?key=homeFeedData&a
-
详解python3 + Scrapy爬虫学习之创建项目
最近准备做一个关于scrapy框架的实战,爬取腾讯社招信息并存储,这篇博客记录一下创建项目的步骤 pycharm是无法创建一个scrapy项目的 因此,我们需要用命令行的方法新建一个scrapy项目 请确保已经安装了scrapy,twisted,pypiwin32 一:进入你所需要的路径,这个路径存储你创建的项目 我的将放在E盘的Scrapy目录下 二:创建项目:scrapy startproject ***(这个是项目名) 这样就创建好了一个名为tencent的项目 三:进入项目新建一个爬虫:
-
python爬虫Scrapy框架:媒体管道原理学习分析
目录 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 图像管道具有一些额外的图像处理功能: 1.2.媒体管道的设置 二.ImagesPipeline类简介 三.小案例:使用图片管道爬取百度图片 3.1.spider文件 3.2.items文件 3.3.settings文件 3.4.pipelines文件 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 避免重新下载最近下载的媒体 指定存储位置(文件系统目录,Amazon S3 bucket,谷歌云存储bucket)
-
python实战项目scrapy管道学习爬取在行高手数据
目录 爬取目标站点分析 编码时间 爬取结果展示 爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据. 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示. 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕. class ZaihangItem(scrapy.Item): # define the fields for your item here like: name
-
python实战之Scrapy框架爬虫爬取微博热搜
前言:大概一年前写的,前段时间跑了下,发现还能用,就分享出来了供大家学习,代码的很多细节不太记得了,也尽力做了优化. 因为毕竟是微博,反爬技术手段还是很周全的,怎么绕过反爬的话要在这说都可以单独写几篇文章了(包括网页动态加载,ajax动态请求,token密钥等等,特别是二级评论,藏得很深,记得当时想了很久才成功拿到),直接上代码. 主要实现的功能: 0.理所应当的,绕过了各种反爬. 1.爬取全部的热搜主要内容. 2.爬取每条热搜的相关微博. 3.爬取每条相关微博的评论,评论用户的各种详细信息.
-
Python实战快速上手BeautifulSoup库爬取专栏标题和地址
目录 安装 解析标签 解析属性 根据class值解析 根据ID解析 多层筛选 提取a标签中的网址 实战-获取博客专栏 标题+网址 BeautifulSoup库快速上手 安装 pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 使用PyCharm的命令行 解析标签 from bs4 import BeautifulS
-
python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用xpath提取此标签对象并返回: 调用点击事件,并循环上述过程: 最终效果图: 代码: from selenium import webdriver import time import re class Douyu(object): def __init__(self): # 开始时的url self.start
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
Python 详解通过Scrapy框架实现爬取CSDN全站热榜标题热词流程
目录 前言 环境部署 实现过程 创建项目 定义Item实体 关键词提取工具 爬虫构造 中间件代码构造 制作自定义pipeline settings配置 执行主程序 执行结果 总结 前言 接着我的上一篇:Python 详解爬取并统计CSDN全站热榜标题关键词词频流程 我换成Scrapy架构也实现了一遍.获取页面源码底层原理是一样的,Scrapy架构更系统一些.下面我会把需要注意的问题,也说明一下. 提供一下GitHub仓库地址:github本项目地址 环境部署 scrapy安装 pip insta
-
Python 详解通过Scrapy框架实现爬取百度新冠疫情数据流程
目录 前言 环境部署 插件推荐 爬虫目标 项目创建 webdriver部署 项目代码 Item定义 中间件定义 定义爬虫 pipeline输出结果文本 配置文件改动 验证结果 总结 前言 闲来无聊,写了一个爬虫程序获取百度疫情数据.申明一下,研究而已.而且页面应该会进程做反爬处理,可能需要调整对应xpath. Github仓库地址:代码仓库 本文主要使用的是scrapy框架. 环境部署 主要简单推荐一下 插件推荐 这里先推荐一个Google Chrome的扩展插件xpath helper,可以验
-
Python爬虫实战之爬取京东商品数据并实实现数据可视化
一.开发工具 Python版本:3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 原理其实挺简单的,首先,我们利用之前开源的DecryptLogin库来实现一下微博的模拟登录操作: '''模拟登录京东''' @staticmethod def login(): lg = login.Login() infos_return, session