Redis数据库分布式设计方案介绍
目录
- 1 哈希取余分区
- 2 一致性哈希算法分区
- 2.1 一致性哈希环
- 2.2 节点映射
- 2.3 落键规则
- 2.4 优缺点
- 3 哈希槽计算
- 总结
问题:1-2亿数据需要缓存,如何设计?
1 哈希取余分区
2亿条记录就是2亿个k,v,假设有3台机器构成一个集群,用户每次读写操作都是根据公:hash(key) % N个机器台数,计算出哈希值,并用来决定数据映射到哪一个节点上。取数据的时候只需要个根据公式在相应的机器,用key就可以取到value。
优点: 简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
缺点:原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
2 一致性哈希算法分区
提出一致性Hash解决方案,目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
2.1 一致性哈希环
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说, 一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环 ,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下图:整个空间 按顺时针方向组织 ,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。

2.2 节点映射
将集群中各个IP节点映射到环上的某一个位置。
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的 哈希函数 计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:
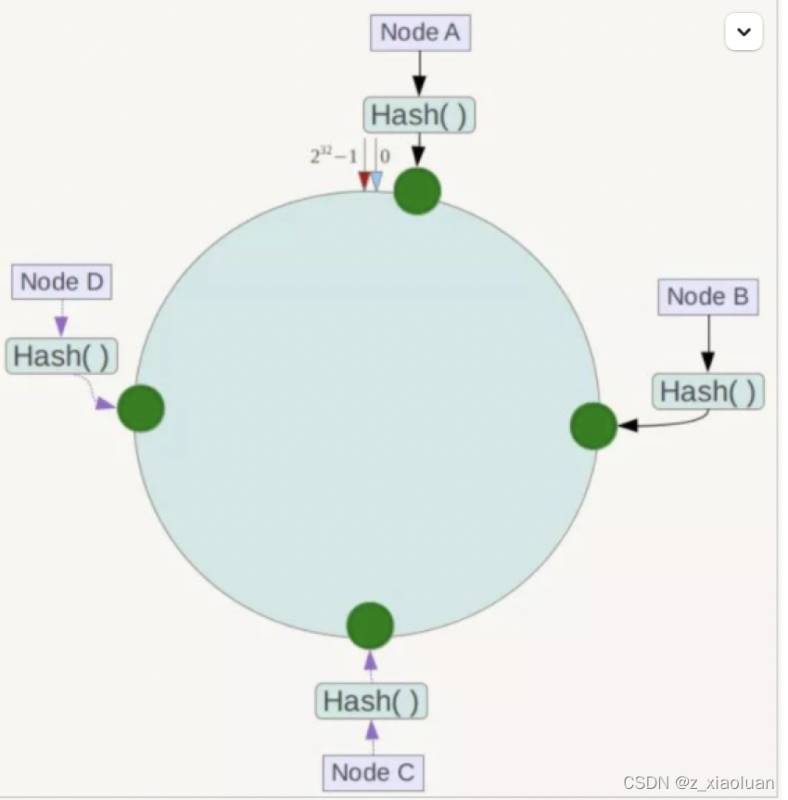
2.3 落键规则
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置, 从此位置沿环顺时针“行走” ,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
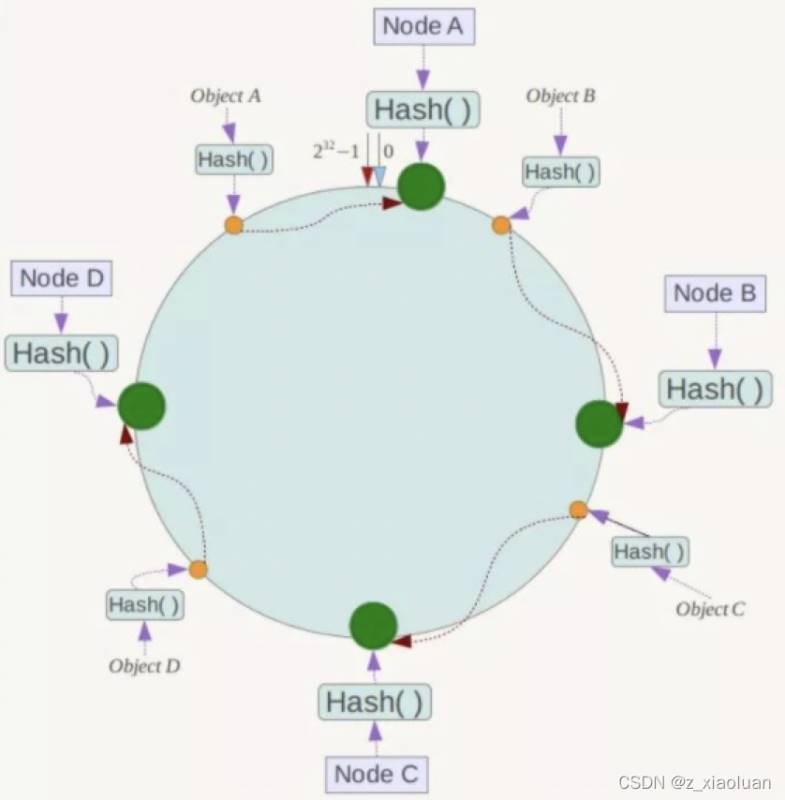
2.4 优缺点
优点:容错性和扩展性
容错性:
假设Node C宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性Hash算法中,如果一台服务器不可用,则 受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据 ,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据,并且这些数据会转移到D进行存储。
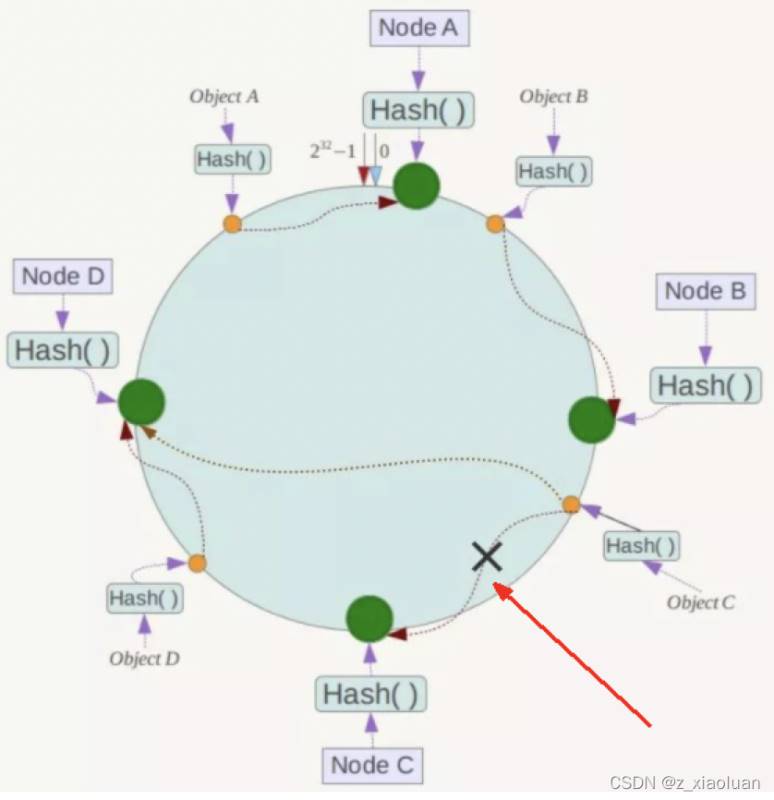
缺点:数据倾斜(节点少不宜)
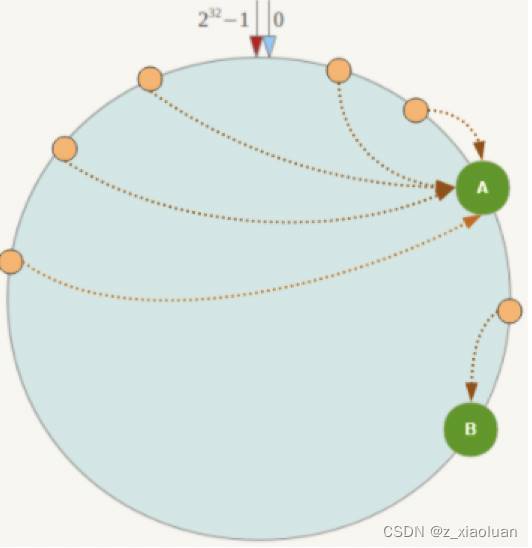
一致性Hash算法在服务 节点太少时 ,容易因为节点分布不均匀而造成 数据倾斜 (被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:
3 哈希槽计算
为了解决一致性哈希算法的倾斜问题
解决均匀分配的问题, 在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系 ,现在就相当于节点上放的是槽,槽里放的是数据。

槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
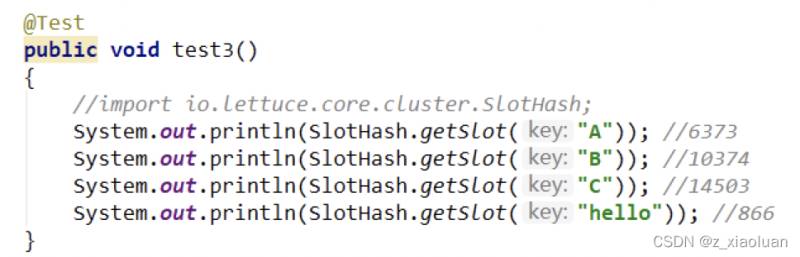
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
Redis 集群中内置了 16384 个哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在 Redis 集群中放置一个 key-value时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,也就是映射到某个节点上。如下代码,key之A 、B在Node2, key之C落在Node3上

总结
到此这篇关于Redis数据库分布式设计方案介绍的文章就介绍到这了,更多相关Redis分布式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

巧用Redis实现分布式锁详细介绍
目录 前言 手写Redis分布式锁 Redisson lock() lock(long leaseTime, TimeUnit unit) tryLock(long waitTime, long leaseTime, TimeUnit unit) RedLock红锁 总结 前言 无论是synchronized还是Lock,都运行在线程级别上,必须运行在同一个JVM中.如果竞争资源的进程不在同一个JVM中时,这样线程锁就无法起到作用,必须使用分布式锁来控制多个进程对资源的访问. 分布式锁的实现一般
-
Redis分布式锁如何实现续期
目录 Redis分布式锁如何续期 Redis分布式锁的正确姿势 如何回答 源码分析 真相大白 Redis分布式锁的5个坑 一.锁未被释放 二.B的锁被A给释放了 三.数据库事务超时 四.锁过期了,业务还没执行完 五.redis主从复制的坑 Redis分布式锁如何续期 Redis分布式锁的正确姿势 据肥朝了解,很多同学在用分布式锁时,都是直接百度搜索找一个Redis分布式锁工具类就直接用了.关键是该工具类中还充斥着很多System.out.println();等语句.其实Redis分布式锁比较正确
-
Redis实现分布式锁方法详细
目录 1. 单机数据一致性 2. 分布式数据一致性 3. Redis实现分布式锁 3.1 方式一 3.2 方式二(改进方式一) 3.3 方式三(改进方式二) 3.4 方式四(改进方式三) 3.5 方式五(改进方式四) 3.6 小结 在单体应用中,如果我们对共享数据不进行加锁操作,会出现数据一致性问题,我们的解决办法通常是加锁. 在分布式架构中,我们同样会遇到数据共享操作问题,本文章使用Redis来解决分布式架构中的数据一致性问题. 1. 单机数据一致性 单机数据一致性架构如下图所示:多个可客户访
-
带你轻松掌握Redis分布式锁
目录 1. 什么是分布式锁 2. 分布式锁该具备的特性 3. 基于数据库做分布式锁 4. 基于Redis做分布式锁 4.1 超时问题 4.2 可重入锁 4.3 集群环境的缺陷 4.4 Redlock 目前很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题. 基于 CAP理论,任何一个分布式系统都无法同时满足一致性(Consistency).可用性(Availability)和分区容错性(Partition tolerance),最多只能同时满足两项. 我们为
-
Redis分布式锁详细介绍
目录 分布式锁 redis实现分布式锁的原理 死锁问题 超时问题 锁误放问题 可重入性 Redlock 分布式锁 在单进程应用中,当一段代码同一时间内只能由一个线程执行时, 多线程下可能会出错,例如两个线程同时对一个数字做累加,两个线程同时拿到了该数字,例如40,一个线程加了10,一个线程加了20,正确结果应该是70, 但由于两个线程在自己的内存中一个算出的是50,一个算出的是60,此时二者都将自己的结果往该数字原本的地方写(保存), 这时候,肯定会有一个线程的值会被覆盖,因为读取->计算->
-
Redis数据库分布式设计方案介绍
目录 1 哈希取余分区 2 一致性哈希算法分区 2.1 一致性哈希环 2.2 节点映射 2.3 落键规则 2.4 优缺点 3 哈希槽计算 总结 问题:1-2亿数据需要缓存,如何设计? 1 哈希取余分区 2亿条记录就是2亿个k,v,假设有3台机器构成一个集群,用户每次读写操作都是根据公:hash(key) % N个机器台数,计算出哈希值,并用来决定数据映射到哪一个节点上.取数据的时候只需要个根据公式在相应的机器,用key就可以取到value. 优点: 简单粗暴,直接有效,只需要预估好数据规划好节
-
关于Redis数据库入门详细介绍
目录 1.Redis是什么? 2.Redis特点: 单线程为何如此快? 3.redis 对比 memcached 4.redis 典型应用场景: 5.Redis下载与安装: Redis服务控制: Redis 命令工具: redis-benchmark 测试工具 redis-cli 命令行工具: 1.Redis是什么? 非关系型数据库:NoMsql 主流的 NoSQL 数据库有Redis. MongBD. Hbase. Memcached 等. Redis译为"远程字典服务",它是一款基
-
Redis数据库的应用场景介绍
一.MySql+Memcached架构的问题 实际MySQL是适合进行海量数据存储的,通过Memcached将热点数据加载到cache,加速访问,很多公司都曾经使用过这样的架构,但随着业务数据量的不断增加,和访问量的持续增长,我们遇到了很多问题: 1)MySQL需要不断进行拆库拆表,Memcached也需不断跟着扩容,扩容和维护工作占据大量开发时间. 2)Memcached与MySQL数据库数据一致性问题. 3)Memcached数据命中率低或down机,大量访问直接穿透到DB,MySQL无法支
-
关于Redis数据库三种持久化方案介绍
目录 一.回顾Redis 二.方案一:bgsave 三.方案二:配置文件rdb 四.方案三:aof 总结 一.回顾Redis 1.redis的特点 redis是一个内存中的数据结构存储系统.优点:内存操作速度比硬盘很快.缺点:但是内存没有办法保存数据. 2.redis提供了磁盘持久化 通过磁盘持久化功能,就可以把内存中的数据,持久化到磁盘当中去.数据就可以长时间的进行保存. 二.方案一:bgsave 1.如何操作 启动redis-cli 客户端,输入一条数据,并输入持久化命令basave就可以完
-
Redis分布式锁介绍与使用
目录 分布式锁 业务逻辑分析 Redis命令 代码实现 分布式锁误删问题 问题原因分析 代码实现 Lua脚本 首先,使用idea模拟搭建一个tomcat服务器集群,并使用Nginx对集群中的服务器实现负载均衡 配置完负载均衡之后,发送两次请求就会在idea的运行窗口中发现,两次请求的运行是分别在两个服务器中完成,这就是集群的轮询机制 分布式锁 业务逻辑分析 在单JVM虚拟机多线程执行的情况下,可以使用JVM内部的锁机制来控制多进程的并发执行,借此可以保证一个用户只能下一个优惠券订单.但是在分
-
Redis数据库中实现分布式锁的方法
分布式锁是一个在很多环境中非常有用的原语,它是不同进程互斥操作共享资源的唯一方法.有很多的开发库和博客描述如何使用Redis实现DLM(Distributed Lock Manager),但是每个开发库使用不同的方式,而且相比更复杂的设计与实现,很多库使用一些简单低可靠的方式来实现. 这篇文章尝试提供更标准的算法来使用Redis实现分布式锁.我们提出一种算法,叫做Relock,它实现了我们认为比vanilla单一实例方式更安全的DLM(分布式锁管理).我们希望社区分析它并提供反馈,以做为更加复杂
-
Jedis操作Redis数据库的方法
本文实例为大家分享了Jedis操作Redis数据库的具体代码,供大家参考,具体内容如下 关于NoSQL的介绍不写了,直接上代码 第一步导包,不多讲 基本操作: package demo; import org.junit.Test; import redis.clients.jedis.Jedis; import redis.clients.jedis.JedisPool; import redis.clients.jedis.JedisPoolConfig; public class Demo
-
SpringBoot使用Redis实现分布式锁
前言 在单机应用时代,我们对一个共享的对象进行多线程访问的时候,使用java的synchronized关键字或者ReentrantLock类对操作的对象加锁就可以解决对象的线程安全问题. 分布式应用时代这个方法却行不通了,我们的应用可能被部署到多台机器上,运行在不同的JVM里,一个对象可能同时存在多台机器的内存中,怎样使共享对象同时只被一个线程处理就成了一个问题. 在分布式系统中为了保证一个对象在高并发的情况下只能被一个线程使用,我们需要一种跨JVM的互斥机制来控制共享资源的访问,此时就需要用到
-
基于redis实现分布式锁的原理与方法
前言 系统的不断扩大,分布式锁是最基本的保障.与单机的多线程不一样的是,分布式跨多个机器.线程的共享变量无法跨机器. 为了保证一个在高并发存场景下只能被同一个线程操作,java并发处理提供ReentrantLock或Synchronized进行互斥控制.但是这仅仅对单机环境有效.我们实现分布式锁大概通过三种方式. redis实现分布式锁 数据库实现分布式锁 zk实现分布式锁 今天我们介绍通过redis实现分布式锁.实际上这三种和java对比看属于一类.都是属于程序外部锁. 原理剖析 上述三种分布