Mysql using使用详解
目录
- 示例
- 第一种
- 第二种
- 第三种
示例
在平时,我们做关联表查询的时候一般是这样的
select * from 表1 inner join 表2 on 表1.相同的列=表2.相同的列;
然后可以改成这样也是同样的效果
select 表1的列 from 表1 inner join 表2 on 表1.相同的列=表2 .相同的列
然后还可以改成这样
select * from 表1 inner join 表2 using(相同的列);
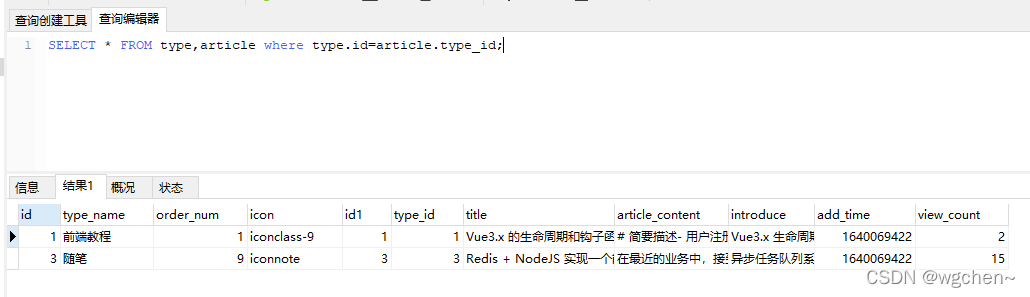
第一种
SELECT * FROM type,article where type.id=article.type_id;

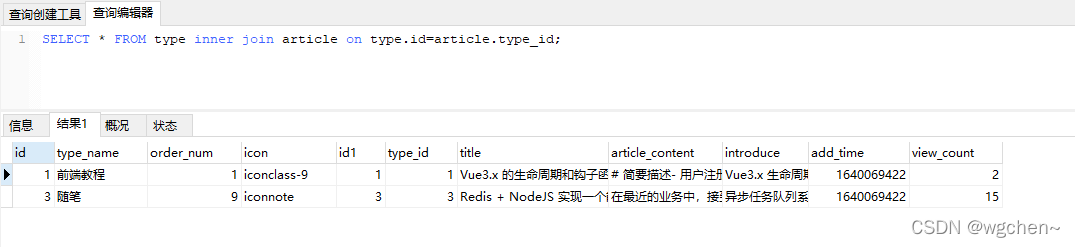
第二种
SELECT * FROM type inner join article on type.id=article.type_id;
第三种
SELECT type.*,article.* FROM type inner join article USING(id);

表
CREATE TABLE `type` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '类型编号',
`type_name` varchar(255) DEFAULT '' COMMENT '文章类型名称',
`order_num` int(11) NOT NULL DEFAULT '0',
`icon` varchar(255) DEFAULT '' COMMENT '自定义图标',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='文章类型表';
INSERT INTO `demo`.`type` (`id`, `type_name`, `order_num`, `icon`) VALUES ('1', '前端教程', '1', 'iconclass-9');
INSERT INTO `demo`.`type` (`id`, `type_name`, `order_num`, `icon`) VALUES ('2', '前端工具', '2', 'icontoolset');
INSERT INTO `demo`.`type` (`id`, `type_name`, `order_num`, `icon`) VALUES ('3', '随笔', '9', 'iconnote');
CREATE TABLE `article` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`type_id` int(11) DEFAULT '0' COMMENT '文章类型编号',
`title` varchar(255) DEFAULT '' COMMENT '文章标题',
`article_content` text COMMENT '文章主体内容',
`introduce` text COMMENT '文章简介',
`add_time` int(11) DEFAULT NULL COMMENT '文章发布时间',
`view_count` int(11) DEFAULT '0' COMMENT '浏览次数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='文章内容表';
INSERT INTO `demo`.`article` (`id`, `type_id`, `title`, `article_content`, `introduce`, `add_time`, `view_count`) VALUES ('1', '1', 'Vue3.x 的生命周期和钩子函数', '# 简要描述\r\n\r\n- 用户注册接口\r\n\r\n 请求URL\r\n- ` http://xx.com/api/user/register `\r\n \r\n 请求方式\r\n- POST \r\n\r\n 参数\r\n\r\n|参数名|必选|类型|说明|\r\n|:---- |:---|:----- |----- |\r\n|username |是 |string |用户名 |\r\n|password |是 |string | 密码 |\r\n|name |否 |string | 昵称 |\r\n\r\n# 返回示例 \r\n\r\n```\r\n {\r\n \"error_code\": 0,\r\n \"data\": {\r\n \"uid\": \"1\",\r\n \"username\": \"12154545\",\r\n \"name\": \"吴系挂\",\r\n \"groupid\": 2 ,\r\n \"reg_time\": \"1436864169\",\r\n \"last_login_time\": \"0\",\r\n }\r\n }\r\n```\r\n\r\n返回参数说明 \r\n\r\n|参数名|类型|说明|\r\n|:----- |:-----|----- |\r\n|groupid |int |用户组id,1:超级管理员;2:普通用户 |\r\n\r\n# 备注 \r\n\r\n- 更多返回错误代码请看首页的错误代码描述', 'Vue3.x 生命周期', '1640069422', '2');
INSERT INTO `demo`.`article` (`id`, `type_id`, `title`, `article_content`, `introduce`, `add_time`, `view_count`) VALUES ('3', '3', 'Redis + NodeJS 实现一个能处理海量数据的异步任务队列系统', '在最近的业务中,接到了一个需要处理约十万条数据的需求。这些数据都以字符串的形式给到,并且处理它们的步骤是异步且耗时的(平均处理一条数据需要 25s 的时间)。如果以串行的方式实现,其耗时是相当长的:', '异步任务队列系统', '1640069422', '15');
到此这篇关于Mysql using使用详解的文章就介绍到这了,更多相关Mysql using内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL中USING 和 HAVING 用法实例简析
本文实例讲述了MySQL中USING 和 HAVING 用法.分享给大家供大家参考,具体如下: USING 用于表连接时给定连接条件(可以理解为简写形式),如 SELECT * FROM table1 JOIN table2 ON table1.id = table2.id 使用 USING 可以写为 SELECT * FROM table1 JOIN table2 USING(id) HAVING 引入 HAVING 是因为 WHERE 无法和统计函数一起使用 如表 order (定单)有如下
-
浅谈mysql数据库中的using的用法
mysql中using的用法为: using()用于两张表的join查询,要求using()指定的列在两个表中均存在,并使用之用于join的条件. 示例: 复制代码 代码如下: select a.*, b.* from a left join b using(colA); 等同于: 复制代码 代码如下: select a.*, b.* from a left join b on a.colA = b.colA; 以上所述就是本文的全部内容,希望大家能够喜欢.
-
Oracle10个分区和Mysql分区区别详解
Oracle10g分区常用的是:range(范围分区).list(列表分区).hash(哈希分区).range-hash(范围-哈希分区).range-list(列表-复合分区). Range分区:Range分区是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中. 如按照时间划分,2010年1月的数据放到a分区,2月的数据放到b分区,在创建的时候,需要指定基于的列,以及分区的范围值. 在按时间分区时,如果某些记录暂无法预测范围,可以创建m
-
MySQL 序列 AUTO_INCREMENT详解及实例代码
MySQL 序列 AUTO_INCREMENT详解及实例代码 MySQL序列是一组整数:1, 2, 3, ...,由于一张数据表只能有一个字段自增主键, 如果你想实现其他字段也实现自动增加,就可以使用MySQL序列来实现. 本章我们将介绍如何使用MySQL的序列. 使用AUTO_INCREMENT MySQL中最简单使用序列的方法就是使用 MySQL AUTO_INCREMENT 来定义列. 实例 以下实例中创建了数据表insect, insect中id无需指定值可实现自动增长. mysql>
-
MySQL prepare原理详解
Prepare的好处 Prepare SQL产生的原因.首先从mysql服务器执行sql的过程开始讲起,SQL执行过程包括以下阶段 词法分析->语法分析->语义分析->执行计划优化->执行.词法分析->语法分析这两个阶段我们称之为硬解析.词法分析识别sql中每个词,语法分析解析SQL语句是否符合sql语法,并得到一棵语法树(Lex).对于只是参数不同,其他均相同的sql,它们执行时间不同但硬解析的时间是相同的.而同一SQL随着查询数据的变化,多次查询执行时间可能不同,但硬解
-
CentOS 7.0下使用yum安装mysql的方法详解
CentOS7默认数据库是mariadb,配置等用着不习惯,因此决定改成mysql,但是CentOS7的yum源中默认好像是没有mysql的.为了解决这个问题,我们要先下载mysql的repo源. 1.下载mysql的repo源 $ wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm 2.安装mysql-community-release-el7-5.noarch.rpm包 $ sudo rpm -ivh mys
-

在Linux系统安装MySql步骤截图详解
如下是我工作中的记录,介绍的是linux系统下使用官方编译好的二进制文件进行安装MySql的安装过程和安装截屏,这种安装方式速度快,安装步骤简单! 需要的朋友可以按照如下步骤进行安装,可以快速安装MySql,希望可以帮助大家:)! 1.下载mysql的linux版本的二进制安装包: 地址:http://dev.mysql.com/downloads/mysql/ 这里我将安装包重命名为:tingyun-mysql-5.6.22.tar.gz 说明:根据自己需要可以不进行重命名操作 2.解压安装包
-
mysql分区功能详解,以及实例分析
一,什么是数据库分区 前段时间写过一篇关于mysql分表的 的文章,下面来说一下什么是数据库分区,以mysql为例.mysql数据库中的数据是以文件的形势存在磁盘上的,默认放在/mysql/data下面 (可以通过my.cnf中的datadir来查看),一张表主要对应着三个文件,一个是frm存放表结构的,一个是myd存放表数据的,一个是myi存表 索引的.如果一张表的数据量太大的话,那么myd,myi就会变的很大,查找数据就会变的很慢,这个时候我们可以利用mysql的分区功能,在物理上将这 一张
-
PHP与MySQL交互使用详解
PHP与MySQL交互使用详解 1.创建自动连接数据库的代码,并生成一些必要的代码.我们仔细研究一下数据库的连接函数,会发现是这样的一行代码. $link_id=@mysql_connect($hostname,$username,$password); 所以我们在include文件connect.inc中添加以下代码就可以了.connect.inc<?php$hostname='localhost'; $username='phpstar';$password='phpstar';$dbnam
-
LINUX启动/重启/停上MYSQL的命令(详解)
如何启动/停止/重启MySQL 一.启动方式 1.使用 service 启动:service mysqld start 2.使用 mysqld 脚本启动:/etc/inint.d/mysqld start 3.使用 safe_mysqld 启动:safe_mysqld& 二.停止 1.使用 service 启动:service mysqld stop 2.使用 mysqld 脚本启动:/etc/inint.d/mysqld stop 3.mysqladmin shutdown 三.重启 1.使用
-
LINUX重启MYSQL的命令详解
如何启动/停止/重启MySQL 一.启动方式 1.使用 service 启动:service mysqld start 2.使用 mysqld 脚本启动:/etc/inint.d/mysqld start 3.使用 safe_mysqld 启动:safe_mysqld& 二.停止 1.使用 service 启动:service mysqld stop 2.使用 mysqld 脚本启动:/etc/inint.d/mysqld stop 3. mysqladmin shutdown 三.重启 1.
-
Linux中对MySQL优化实例详解
Linux中对MySQL优化实例详解 vim /etc/my.cnf以下只列出my.cnf文件中[mysqld]段落中的内容,其他段落内容对MySQL运行性能影响甚微,因而姑且忽略. [mysqld] port = 3306 serverid = 1 socket = /tmp/mysql.sock skip-locking 避免MySQL的外部锁定,减少出错几率增强稳定性. skip-name-resolve 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析