C/C++字节序的深入理解
目录
- 字节序
- 大端序
- 小端序
- 主机字节序和网络字节序
- 大端序和小端序的互转
字节序
最近在看 redis 的内存编码,里面涉及到字节序相关的内容。这里就当复习一下,做个简单的回顾。
数据存储在内存中,是以字节为单位的,如果是单字节数据(如char、unsigned char、int8)就不会有字节序的问题。但是多字节数据(如 int、float、double)就要考虑字节序的问题了。字节序共分为两种:大端序 和 小端序。
大端序
数据的高位字节存储在地址的低端;低位字节存储在地址的高端。如图所示,值为 0x12345678 的四字节整数在大端序的主机上的内存排布。

小端序
数据的高位字节存储在地址的高端;低位字节存储在地址的低端。如图所示,值为 0x12345678 的四字节整数在小端序的主机上的内存排布。
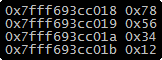
主机字节序和网络字节序
除了主机字节序,还有网络字节序。主机字节序由CPU决定,Intel Core 经测试都是小端字节序。而网络字节序采用的是大端序。测试字节序可以通过一段 C 的源码搞定。
#include <stdio.h>
int main(int argc, char *argv[]) {
int i;
int x = 0x12345678;
for (i = 0; i < sizeof(int); ++i) {
unsigned char *p = ((unsigned char *)(&x)) + i;
unsigned char v = *p;
printf("%p 0x%d%d\n", p, v>>4, v & 0xf );
}
return 0;
}
取得整数 x 的首地址转换成 unsigned char* 指针后再向前偏移 i 个单位,分别得到这 sizeof(int) 个字节的地址,然后用 * 取得每个地址上的值,通过位运算转换成 16进制 输出。
Linux 系统可以通过指令获取 CPU 的类型:
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c 4 Intel(R) Core(TM) i3-2120 CPU @ 3.30GHz
大端序和小端序的互转
大端序和小端序的互相转换,其实就是内存翻转,在知道一个整数或者一个指针的字节数的时候,就是做一个镜像的交换。这里以 64位 整型为例:
void memrev64(void *p) {
unsigned char *x = p, t;
t = x[0];
x[0] = x[7];
x[7] = t;
t = x[1];
x[1] = x[6];
x[6] = t;
t = x[2];
x[2] = x[5];
x[5] = t;
t = x[3];
x[3] = x[4];
x[4] = t;
}
uint64_t intrev64(uint64_t v) {
memrev64(&v);
return v;
}
64位整数的字节数为8,所以在字节序进行转换的时候:
第0个字节和第7个字节交换;
第1个字节和第6个字节交换;
第2个字节和第5个字节交换;
第3个字节和第4个字节交换;
对于 32位整数、16位整数的情况,就更加简单了,不再累述。
到此这篇关于C/C++字节序的深入理解的文章就介绍到这了,更多相关C语言 字节序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于C++内存中字节对齐问题的详细介绍
一.什么是字节对齐计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐. 二.对齐的作用和原因:1.平台原因(移植原因):不是所有的硬件平台都能访问任意地址上的任意数据的:某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常.各个硬件平台对存储空间的处理上有很大的不同.一些平台对某些特定类型
-

C++中int类型按字节打印输出的方法
前言 今天在项目编程中,遇到一个问题,u32类型的参数,要赋值给一个u8 array[3],想用memcpy()函数进行赋值,由于类型大小不一致,一时不知道怎么做,经过查找,得以解决.说明如下; 项目是在内网中做,在查找过程中用自己笔记本做了一下实验,vs2013版本. 类似主题是int类型按字节打印数据,sizeof(int)实验验证后为4字节,就分别打印出这4个字节中的数值. 先贴上代码 #include<iostream> using namespace std; int main()
-
C++多字节字符与宽字节字符相互转换
最近在C++编程中经常遇到需要多字节字符与宽字节字符相互转换的问题,一直自己贴那几句代码.觉得麻烦,于是就自己写了一个类来封装wchar_t与char类型间的转换,其他的,诸如:CString\ LPWSTR\TCHAR CHAR\LPSTR之间也是一样用 复制代码 代码如下: #include <iostream> using namespace std; class CUser { public: CUser(); virtual~ CUser(); char* WcharToChar(w
-
浅谈C++中的string 类型占几个字节
在C语言中我们操作字符串肯定用到的是指针或者数组,这样相对来说对字符串的处理还是比较麻烦的,好在C++中提供了 string 类型的支持,让我们在处理字符串时方便了许多. 首先,我写了一段测试代码,如下所示: 复制代码 代码如下: #include <iostream>using namespace std; int main(void){ string str_test1; string str_test2 = "Hello World"; int value1, val
-
C/C++字节序的深入理解
目录 字节序 大端序 小端序 主机字节序和网络字节序 大端序和小端序的互转 字节序 最近在看 redis 的内存编码,里面涉及到字节序相关的内容.这里就当复习一下,做个简单的回顾. 数据存储在内存中,是以字节为单位的,如果是单字节数据(如char.unsigned char.int8)就不会有字节序的问题.但是多字节数据(如 int.float.double)就要考虑字节序的问题了.字节序共分为两种:大端序 和 小端序. 大端序 数据的高位字节存储在地址的低端:低位字节存储在地址的高端.如图所示
-
基于大端法、小端法以及网络字节序的深入理解
关于字节序(大端法.小端法)的定义<UNXI网络编程>定义:术语"小端"和"大端"表示多字节值的哪一端(小端或大端)存储在该值的起始地址.小端存在起始地址,即是小端字节序:大端存在起始地址,即是大端字节序. 也可以说: 1.小端法(Little-Endian)就是低位字节排放在内存的低地址端即该值的起始地址,高位字节排放在内存的高地址端. 2.大端法(Big-Endian)就是高位字节排放在内存的低地址端即该值的起始地址,低位字节排放在内存的高地址端.举
-
Java整型数与网络字节序byte[]数组转换关系详解
本文实例讲述了Java整型数与网络字节序byte[]数组转换关系.分享给大家供大家参考,具体如下: 工作项目需要在java和c/c++之间进行socket通信,socket通信是以字节流或者字节包进行的,socket发送方须将数据转换为字节流或者字节包,而接收方则将字节流和字节包再转换回相应的数据类型.如果发送方和接收方都是同种语言,则一般只涉及到字节序的调整.而对于java和c/c++的通信,则情况就要复杂一些,主要是因为java中没有unsigned类型,并且java和c在某些数据类型上的长
-
c++中的字节序与符号位的问题
目录 c++的字节序与符号位 c++多字节值与字节序 多字节值与字节序 对于跨平台应用,字节序的两种处理方式 字节序的判断 整数字节序的转换 浮点数的字节序转换 c++的字节序与符号位 看这样一道题: #include <stdio.h> int main(void) { int w, h; int i = 0xa1b2c3d4; char *p = (char *)&i; for (int j = 0; j < 4; j++) {
-
Android 和 windows C/C++/QT通讯时字节存储
ava:采用大端字节序存储数据[低地址存放数据的高位,高地址存放数据的低位,数据高位存放在数组的前面] windows(intel平台):采用小端字节序存储数据[低地址存放数据的低位,高地址存放数据的高位,数据的高位存放在数组的后面](windows接收java发送过来的short,int需要调用ntohs和ntohl来转换到小数端) [数据高位]:0x1234的高位为 0x12 [数据低位]:0x1234的低位为 0x34 如: int ihex = 0x12345678; short she
-
Java JVM字节码指令集总结整理与介绍
目录 Java是怎么跨平台的 平台无关的基石 JVM字节码指令介绍 字节码与数据类型 加载和存储指令 算术指令 类型转换指令 宽化类型转换 窄化类型转换: 对象创建与访问指令 操作数栈管理指令 控制转移指令 方法调用和返回指令 异常处理指令 同步指令 JVM指令集大全 Java是怎么跨平台的 我们上计算机课的时候老师讲过:"计算机只能识别0和1,所以我们写的程序要经过编译器翻译成0和1组成的二进制格式计算机才能执行".我们编译后产生的.class文件是二进制的字节码,字节码是不能被机器
-
python中struct模块之字节型数据的处理方法
简介 这个模块处理python中常见类型数据和Python bytes之间转换.这可用于处理存储在文件或网络连接中的bytes数据以及其他来源.在python中没有专门处理字节的数据类型,建立字节型数据也比较麻烦,我们知道的bytes()函数也只能对无符号整型做处理,并且数据如下(没错,数字为多少就有多少个\x00,我们要是用这种方式来存储大量数据,结果可想而知): va = bytes(1) # va: '\x00' vb = bytes(2) # vb: '\x00\x00' vc = by
-
基于Nodejs的Tcp封包和解包的理解
我们知道,TCP是面向连接流传输的,其采用Nagle算法,在缓冲区对上层数据进行了处理.避免触发自动分片机制和网络上大量小数据包的同时也造成了粘包(小包合并)和半包(大包拆分)问题,导致数据没有消息保护边界,接收端接收到一次数据无法判断是否是一个完整数据包.那有什么方案可以解决这问题呢? 1.粘包问题解决方案及对比 很简单,既然消息没有边界,那我们在消息往下传之前给它加一个边界识别就好了. 发送固定长度的消息 使用特殊标记来区分消息间隔 把消息的尺寸与消息一块发送 第一种方案不够灵活:第二种有风
-
浅谈java中字节与字符的区别
最近在看Java中的IO相关知识,发现对字节和字符的理解还不够.写篇总结记录一下. 一.字节 所谓字节(Byte),是计算机数据存储的一种计量单位.一个二进制位称为比特(bit),8个比特组成一个字节,也就是说一个字节可以用于区分256个整数(0~255).由此我们可以知道,字节本是面向计算机数据存储及传输的基本单位,后续的字符也就是以字节为单位存储的,不同编码的字符占用的字节数不同. 那么在Java中,除了存储的意义外,Java还将字节Byte作为一种基本数据类型,该数据类型在内存中占用一个字
-
C语言进阶几分钟带你理解大小端存储模式
目录 正片开始 共用体原理 引申一下 字节顺序 大小端存储 共用体判断大小端 正片开始 C语言中数据类型的存储是较为严谨的,一块空间只能存储一种数据类型,要知道内存这个东西,在早期可是非常珍贵的. 尤其对于那些性能不好计算机更是如此,比如 Office1997,操作系统为Windows95 ,奔腾1的cpu,内存只有128M.就这么绿豆点大的存储空间,要想达到节约,利用最大化就必须在同一块空间中存入不同类型数据. 所以共用体的概念就随之产生,将几种不同类型的内容覆盖到同一内存单元,之前在我的一篇