R语言绘制带ErrorBar的分组条形图代码的分享
目录
- 第一种实现方法:用aggregate计算数据
- 第二种实现方法:用dplyr包计算数据
笔者近期画了一张带error bar的分组条形图,将相关的代码分享一下。
感谢网友青山屋主的建议,提示笔者要严谨区分技术重复和生物学重复,所以笔者对文章做修改后重发。如果各位有任何建议,欢迎指正。
本文旨在给出一种利用R对生物学重复数据画带error bar的分组条形图的方法。
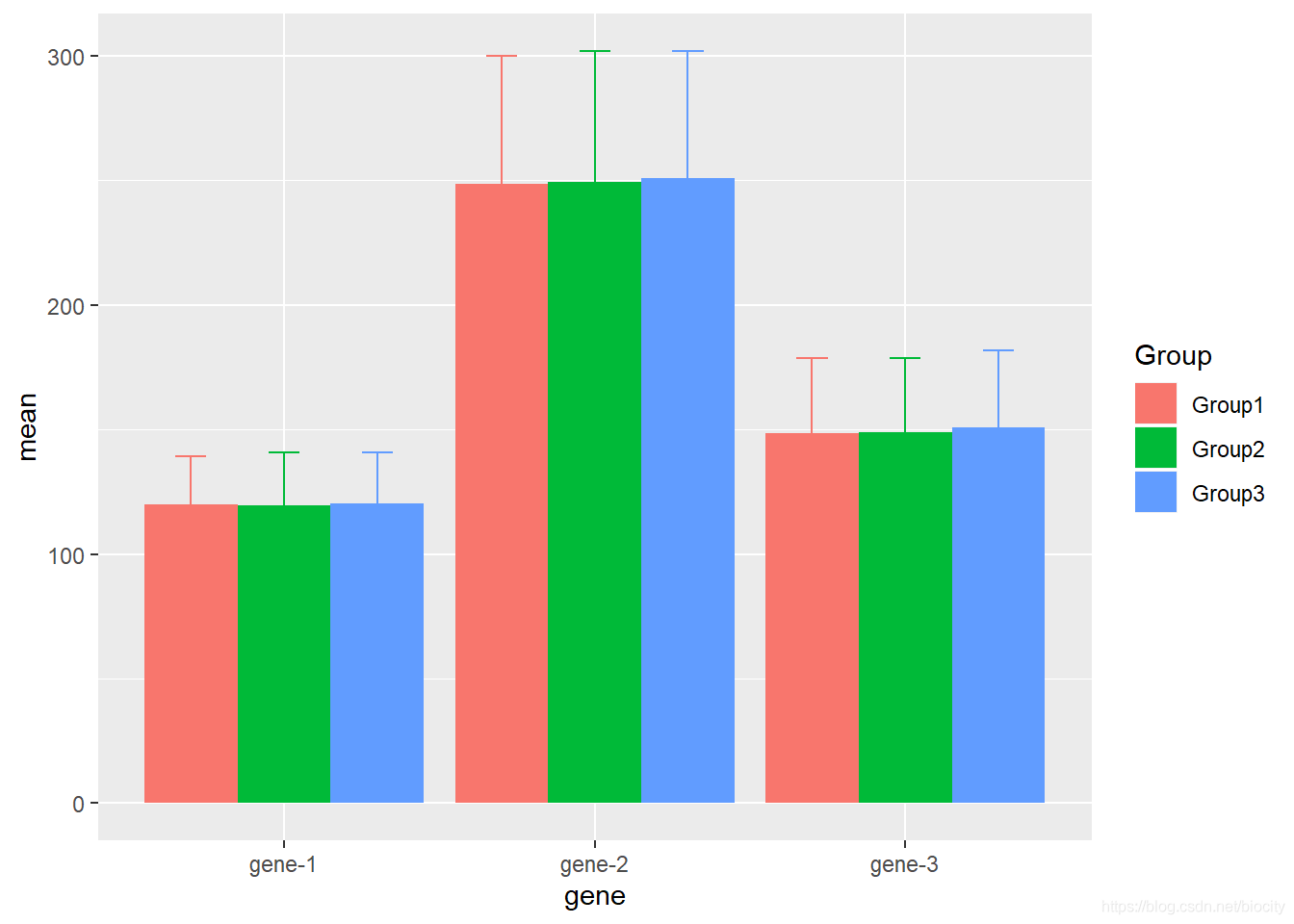
所用数据是模拟生成的:分成三个组,每个组进行了若干次生物学重复;测量的是3种基因的表达量。数据的部分内容如下:
## gene1 gene2 gene3 Group ## 1 49.72475 267.0007 126.2007 Group1 ## 2 114.62184 173.8780 150.2641 Group2 ## 3 128.03351 227.9456 152.6378 Group3 ## 4 134.90841 385.1979 148.2739 Group1 ## 5 136.56659 190.0663 122.6201 Group2 ## 6 143.88241 329.0516 236.9131 Group3
两种方法的完整代码放在了文末。如有问题,欢迎指正!
第一种实现方法:用aggregate计算数据
# 导入数据
setwd("E:/")
df <- read.csv("gene_exp.csv", header=T)
# 可以在这里改列名,这些列名就是最终图上X轴的标签名。
colnames(df)[1:3] <- c("gene-1", "gene-2", "gene-3")
str(df) # 显示数据集内容
## 'data.frame': 3000 obs. of 4 variables: ## $ gene-1: num 49.7 114.6 128 134.9 136.6 ... ## $ gene-2: num 267 174 228 385 190 ... ## $ gene-3: num 126 150 153 148 123 ... ## $ Group : Factor w/ 3 levels "Group1","Group2",..: 1 2 3 1 2 3 1 2 3 1 ...
# 将上述"宽数据"转化为"长数据"
library(reshape2)
df_reshape <- melt(df, id.vars=c("Group"))
str(df_reshape)
## 'data.frame': 9000 obs. of 3 variables: ## $ Group : Factor w/ 3 levels "Group1","Group2",..: 1 2 3 1 2 3 1 2 3 1 ... ## $ variable: Factor w/ 3 levels "gene-1","gene-2",..: 1 1 1 1 1 1 1 1 1 1 ... ## $ value : num 49.7 114.6 128 134.9 136.6 ...
# 获取三个组各个基因表达量的平均值
df_mean <- aggregate(df_reshape$value, list(Group=df_reshape$Group,
gene=df_reshape$variable), mean, na.rm=T)
# 获取三个组各个基因表达量的标准差
df_sd <- aggregate(df_reshape$value, list(Group=df_reshape$Group,
gene=df_reshape$variable), sd, na.rm=T)
# 合并mean和sd
colnames(df_mean)[3] <- "mean"
colnames(df_sd)[3] <- "sd"
df_stat <- merge(df_mean, df_sd, by=c("Group", "gene"))
str(df_stat)
## 'data.frame': 9 obs. of 4 variables: ## $ Group: Factor w/ 3 levels "Group1","Group2",..: 1 1 1 2 2 2 3 3 3 ## $ gene : Factor w/ 3 levels "gene-1","gene-2",..: 1 2 3 1 2 3 1 2 3 ## $ mean : num 120 249 149 119 250 ... ## $ sd : num 19.4 51.4 30.2 21.2 52.3 ...
# 画图
#直接在画图的语句中计算出error_bar所需的数据:
#(即下面的ymin=mean-sd和ymax=mean+sd语句)。
library(ggplot2)
dodge <- position_dodge(width=.9)
ggplot(data=df_stat) +
geom_bar(aes(x=gene, y=mean, fill=Group),
stat="identity", position=dodge) +
geom_errorbar(aes(x=gene, ymin=mean-sd, ymax=mean+sd, color=Group),
stat="identity", position=dodge, width=.3)
第二种实现方法:用dplyr包计算数据
# 导入数据
setwd("E:/")
df <- read.csv("gene_exp.csv", header=T)
# 可以在这里改列名,这些列名就是最终图上X轴的标签名。
colnames(df)[1:3] <- c("gene-1", "gene-2", "gene-3")
str(df) # 显示数据集内容
## 'data.frame': 3000 obs. of 4 variables: ## $ gene-1: num 49.7 114.6 128 134.9 136.6 ... ## $ gene-2: num 267 174 228 385 190 ... ## $ gene-3: num 126 150 153 148 123 ... ## $ Group : Factor w/ 3 levels "Group1","Group2",..: 1 2 3 1 2 3 1 2 3 1 ...
# 获取三个组各个基因表达量的平均值和标准差 library(tidyr) library(dplyr) df_stat <- tbl_df(df) %>% gather(gene, value, -Group) %>% # 将"宽数据"转化为"长数据" group_by(Group, gene) %>% # 将数据分组 summarise(mean=mean(value, na.rm=T), sd=sd(value, na.rm=T)) %>% # 计算每组数据的mean和sd ungroup() str(df_stat)
## Classes 'tbl_df', 'tbl' and 'data.frame': 9 obs. of 4 variables: ## $ Group: Factor w/ 3 levels "Group1","Group2",..: 1 1 1 2 2 2 3 3 3 ## $ gene : chr "gene-1" "gene-2" "gene-3" "gene-1" ... ## $ mean : num 120 249 149 119 250 ... ## $ sd : num 19.4 51.4 30.2 21.2 52.3 ...
# 画图
#直接在画图的语句中计算出error_bar所需的数据:
#(即下面的ymin=mean-sd和ymax=mean+sd语句)。
library(ggplot2)
dodge <- position_dodge(width=.9)
df_stat %>% ggplot() +
geom_bar(aes(x=gene, y=mean, fill=Group),
stat="identity", position=dodge) +
geom_errorbar(aes(x=gene, ymin=mean-sd, ymax=mean+sd, color=Group),
stat="identity", position=dodge, width=.3)
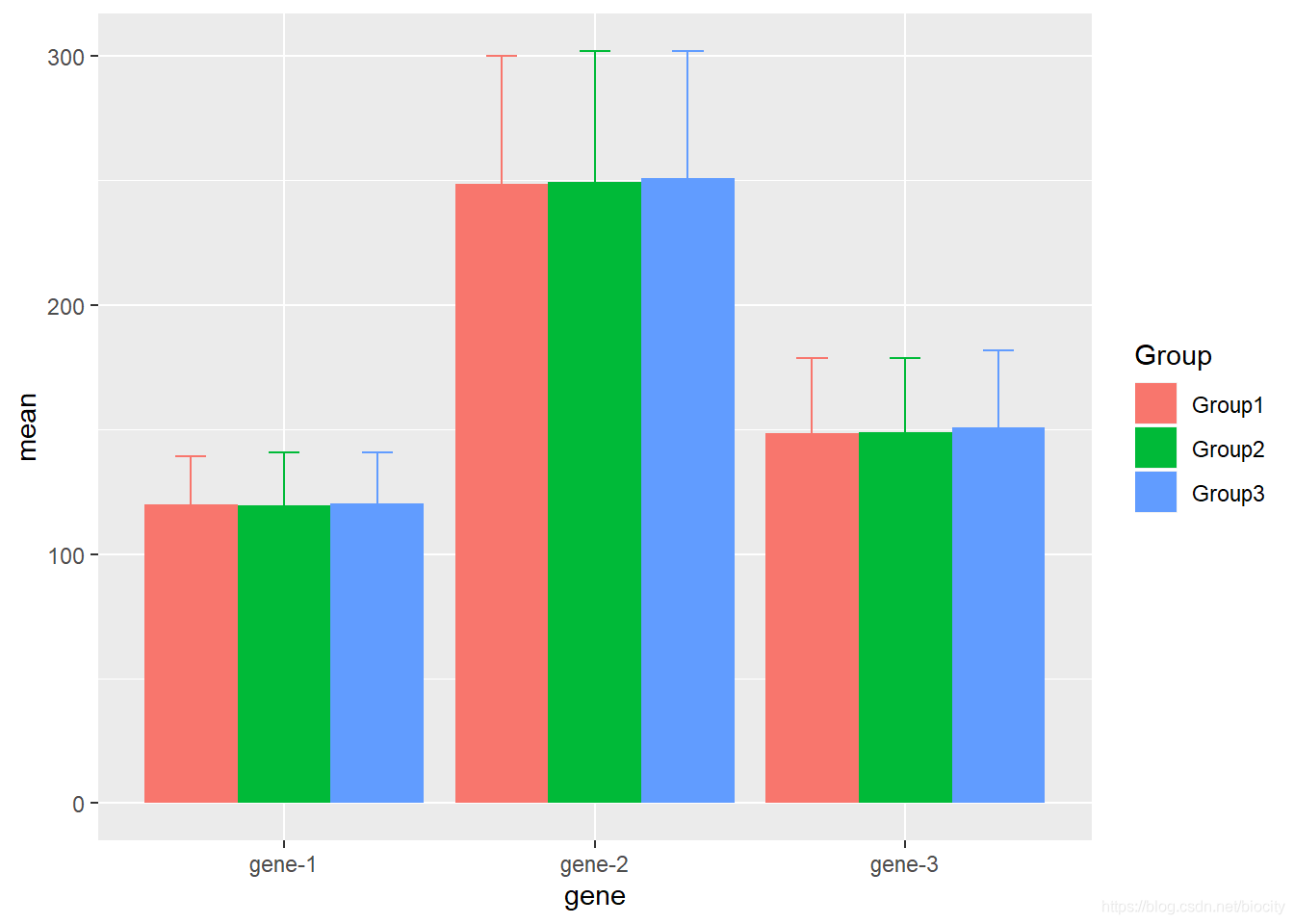
两种方法的结果是一样的,相对而言,dplyr的实现方法更简单快捷。
最后,两种方法的完整代码如下:
#################第一种实现方法:用aggregate计算数据######################
# 导入数据
setwd("E:/")
df <- read.csv("gene_exp.csv", header=T)
# 可以在这里改列名,这些列名就是最终图上X轴的标签名。
colnames(df)[1:3] <- c("gene-1", "gene-2", "gene-3")
str(df) # 显示数据集内容
# 将上述"宽数据"转化为"长数据"
library(reshape2)
df_reshape <- melt(df, id.vars=c("Group"))
str(df_reshape)
# 获取三个组各个基因表达量的平均值
df_mean <- aggregate(df_reshape$value, list(Group=df_reshape$Group,
gene=df_reshape$variable), mean, na.rm=T)
# 获取三个组各个基因表达量的标准差
df_sd <- aggregate(df_reshape$value, list(Group=df_reshape$Group,
gene=df_reshape$variable), sd, na.rm=T)
# 合并mean和sd
colnames(df_mean)[3] <- "mean"
colnames(df_sd)[3] <- "sd"
df_stat <- merge(df_mean, df_sd, by=c("Group", "gene"))
str(df_stat)
# 画图
#直接在画图的语句中计算出error_bar所需的数据:
#(即下面的ymin=mean-sd和ymax=mean+sd语句)。
library(ggplot2)
dodge <- position_dodge(width=.9)
ggplot(data=df_stat) +
geom_bar(aes(x=gene, y=mean, fill=Group),
stat="identity", position=dodge) +
geom_errorbar(aes(x=gene, ymin=mean-sd, ymax=mean+sd, color=Group),
stat="identity", position=dodge, width=.3)
####################第二种实现方法:用dplyr包计算数据######################
# 导入数据
setwd("E:/")
df <- read.csv("gene_exp.csv", header=T)
# 可以在这里改列名,这些列名就是最终图上X轴的标签名。
colnames(df)[1:3] <- c("gene-1", "gene-2", "gene-3")
str(df) # 显示数据集内容
# 获取三个组各个基因表达量的平均值和标准差
library(tidyr)
library(dplyr)
df_stat <- tbl_df(df) %>%
gather(gene, value, -Group) %>% # 将"宽数据"转化为"长数据"
group_by(Group, gene) %>% # 将数据分组
summarise(mean=mean(value, na.rm=T), sd=sd(value, na.rm=T)) %>% # 计算每组数据的mean和sd
ungroup()
str(df_stat)
# 画图
#直接在画图的语句中计算出error_bar所需的数据:
#(即下面的ymin=mean-sd和ymax=mean+sd语句)。
library(ggplot2)
dodge <- position_dodge(width=.9)
df_stat %>% ggplot() +
geom_bar(aes(x=gene, y=mean, fill=Group),
stat="identity", position=dodge) +
geom_errorbar(aes(x=gene, ymin=mean-sd, ymax=mean+sd, color=Group),
stat="identity", position=dodge, width=.3)
以上就是 R语言绘制带ErrorBar的分组条形图代码的分享的详细内容,更多关于 R语言绘制带ErrorBar的分组条形图的资料请关注我们其它相关文章!
相关推荐
-

R语言绘制散点图实例分析
散点图显示在笛卡尔平面中绘制的许多点. 每个点表示两个变量的值. 在水平轴上选择一个变量,在垂直轴上选择另一个变量. 使用plot()函数创建简单散点图. 语法 在R语言中创建散点图的基本语法是 - plot(x, y, main, xlab, ylab, xlim, ylim, axes) 以下是所使用的参数的描述 - x是其值为水平坐标的数据集. y是其值是垂直坐标的数据集. main要是图形的图块. xlab是水平轴上的标签. ylab是垂直轴上的标签. xlim是用于绘图的x的值的极限.
-
如何用R语言绘制饼图和条形图
R 语言提供来大量的库来实现绘图功能. 饼图,或称饼状图,是一个划分为几个扇形的圆形统计图表,用于描述量.频率或百分比之间的相对关系. R 语言使用 pie() 函数来实现饼图,语法格式如下: pie(x, labels = names(x), edges = 200, radius = 0.8, clockwise = FALSE, init.angle = if(clockwise) 90 else 0, density = NULL, angle = 45, col = NULL, bor
-
R语言绘图数据可视化pie chart饼图
目录 Step 1. 绘图数据的准备 Step2. 绘图数据的读取 Step3.绘图所需package的调用 Step4. 饼图百分比标签准备 Step5.绘图 今天要给大家介绍的Pie chart(饼图),本来是不打算写这个的,因为用Excel画饼图实在是太方便了.本着能少动一下是一下的懒人原则,是不打算用R画的,再说,本小仙不是掌握了R作图大器ggplot2么,实在需要用的时候我就一句ggplot()+geom_pie()不就搞定了. 结果后来用Excel画饼图调整颜色.大小的时候着实有些崩
-
R语言绘制饼状图代码实例
R编程语言有许多库来创建图表和图表. 饼图是将值表示为具有不同颜色的圆的切片. 切片被标记,并且对应于每个片的数字也在图表中表示. 在R语言中,饼图是使用pie()函数创建的,它使用正数作为向量输入. 附加参数用于控制标签,颜色,标题等. 语法 使用R语言创建饼图的基本语法是 pie(x, labels, radius, main, col, clockwise) 以下是所使用的参数的描述 x是包含饼图中使用的数值的向量. labels用于给出切片的描述. radius表示饼图圆的半径(值-1和
-
R语言绘制带ErrorBar的分组条形图代码的分享
目录 第一种实现方法:用aggregate计算数据 第二种实现方法:用dplyr包计算数据 笔者近期画了一张带error bar的分组条形图,将相关的代码分享一下. 感谢网友青山屋主的建议,提示笔者要严谨区分技术重复和生物学重复,所以笔者对文章做修改后重发.如果各位有任何建议,欢迎指正. 本文旨在给出一种利用R对生物学重复数据画带error bar的分组条形图的方法. 所用数据是模拟生成的:分成三个组,每个组进行了若干次生物学重复:测量的是3种基因的表达量.数据的部分内容如下: ## gene1
-
R语言可视化开发forestplot根据分组设置不同颜色
目录 分组设置颜色 给每行增加辅助线 分组设置颜色 library(forestplot) fn <- local({ i = 0 function(..., clr.line, clr.marker){ i <<- i + 1 if(i%%4==3){fpDrawNormalCI(..., clr.line = "#000000", clr.marker = "#00B9BF")} #4组中的第3组 else if(i%%4==0){fpDraw
-
R语言绘制带误差线的条形图
条形统计图是用一个单位长度表示一定的数量,根据数量的多少画成长短不同的直条.带误差的条形图可以通过误差线来判断显著性. 继续使用我们的汽车销售数据(公众号回复:汽车销售,可以获得该数据)来演示,先导入数据 library(foreign) library(ggplot2) library(tidyverse) bc <- read.spss("E:/r/test/tree_car.sav", use.value.labels=F, to.data.frame=T) names(b
-
R语言入门使用RStudio制作包含Rcpp代码的R包
目录 1. 创建项目 2. 修改一些文件 3. 打包 4. 使用Eigen或其它依赖库会出现的问题 前面博客中有提及,当我们进行模拟想要再次进行提速时,通常都会使用Rcpp将我们的R代码改成C++代码.具体Rcpp的使用可参考博客:Rcpp入门R代码提速方法过程,R语言学习RcppEigen进行矩阵运算. 平时在我们使用的时候,直接使用Rcpp::sourceCpp()就可以直接将我们的C++代码中的函数进行导入,这不会遇到什么问题,但如果我们想要使用snowfall进行并行时就不能再这样做了.
-
R语言实现PCA主成分分析图的示例代码
目录 简介 开始作图 1. PCA 分析图本质上是散点图 2. 为不同类别着色 3. 样式微调 简介 主成分分析(Principal Component Analysis,PCA)是一种无监督的数据降维方法,通过主成分分析可以尽可能保留下具备区分性的低维数据特征.主成分分析图能帮助我们直观地感受样本在降维后空间中的分簇和聚合情况,这在一定程度上亦能体现样本在原始空间中的分布情况,这对于只能感知三维空间的人类来说,不失为一种不错的选择. 再举个形象的栗子,假如你是一本养花工具宣传册的摄影师,你正在
-
R语言-使用ifelse进行数据分组
数据分组,根据数据分析对象的特征,按照一定的数值指标,把数据分析对象划分为不同的区间部分来研究,以揭示内在的联系和规律性: 在R中,我们常用ifelse函数来进行数据的分组,跟excel中的if函数是同一种用法. ifelse(condition,TRUE,FALSE) > data <- read.table('1.csv', sep='|', header=TRUE); > > level <- ifelse( + data$cost<=20, "(0,2
-
R语言数据可视化绘图bar chart条形图实现示例
时光飞逝,岁月如梭,转眼又是一年过去了,本小仙怎么还是一事无成呢! 转念一想,这种事也不是一次两次了,再多一个又何妨,哈哈! 回归正题,今天就给大家介绍下直方图(histogram)的“好兄弟”——条形图(bar chart).假设小仙同学现在要帮一家书店用图形展示2018年最受大家欢迎的书目,数据如下图. 条形图画出来还挺好看,可是跟小仙想象中的可不一样.明明我的数据是按照销量从高到低排列的,为什么画出来却是按照字母顺序排列的呢? 使用了对因子进行排序的函数reorder()之后,就变成了下图
-
R语言ggplot2x轴顺序设置自定义颜色的操作
先声明一下所用的数据集 第一个图如下 这个图主要在于x轴的顺序设置上,如果按不做任何处理的话>3那个就会在2之前,解决方法是b[,1]<-factor(b[,1],levels=c('2','3',">3")),这句代码可以重新设置因子的级别 完整代码如下: a[,1]<-factor(a[,1],levels=c('2','3',">3")) ggplot(a,aes(x=a[,1],y=a[,2]))+geom_bar(stat=&