python3 使用traceback定位异常实例
1、我们使用正常的输出语句
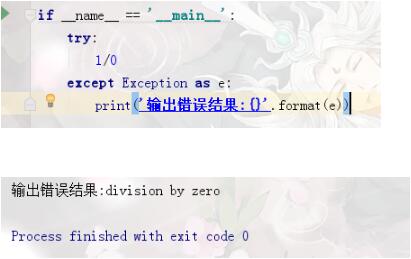
得到的是(输出结果:division by zero)虽然得到了错误的日志输出,但是不知道为什么出错,也不能定位具体出错位置。
2、现在我们使用 traceback
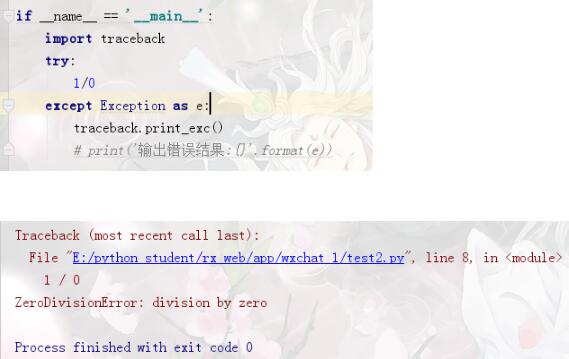
就可以得到具体的错误,以及定位到出错的位置。这样就能更方便调试错误。
参考文献
traceback文档地址:
https://docs.python.org/2/library/traceback.html
以下为google翻译(仅供参考,):
该模块提供了一个标准接口,用于提取,格式化和打印Python程序的堆栈跟踪。它在打印堆栈跟踪时完全模仿了Python解释器的行为。当您想要在程序控制下打印堆栈跟踪时,这非常有用,例如在解释器周围的“包装器”中。
该模块使用回溯对象 - 这是存储在变量中的对象类型sys.exc_traceback(不建议使用), sys.last_traceback并作为第三项返回 sys.exc_info()。
该模块定义了以下功能:
traceback.print_tb(tb [,limit [,file ] ] )
打印以限制回溯对象tb中的堆栈跟踪条目。如果 省略limit或者None打印所有条目。如果省略文件或None输出转到sys.stderr; 否则它应该是一个打开的文件或类似文件的对象来接收输出。
traceback.print_exception(etype,value,tb [,limit [,file ] ] )
打印异常信息,最多限制堆栈跟踪条目从traceback tb到文件。这与print_tb()以下方式不同:(1)如果tb不是None,则打印标题; (2)在堆栈跟踪后打印异常etype和值 ; (3)如果etype是且值具有适当的格式,则打印出发生语法错误的行,其中插入符号表示错误的大致位置。Traceback (most recent call last):SyntaxError
traceback.print_exc([ limit [,file ] ] )
这是一个简写。(实际上,它用于以线程安全的方式检索相同的信息,而不是使用已弃用的变量。)print_exception(sys.exc_type, sys.exc_value, sys.exc_traceback, limit, file)sys.exc_info()
traceback.format_exc([ 限制] )
这就像print_exc(limit)但返回一个字符串而不是打印到文件。
版本2.4中的新功能。
traceback.print_last([ limit [,file ] ] )
这是一个简写。通常,只有在异常达到交互式提示后才会起作用(请参阅参考资料)。print_exception(sys.last_type, sys.last_value, sys.last_traceback, limit, file)sys.last_type
traceback.print_stack([ f [,limit [,file ] ] ] )
此函数从其调用点打印堆栈跟踪。可选的 f参数可用于指定要启动的备用堆栈帧。可选的limit和file参数具有相同的含义 print_exception()。
traceback.extract_tb(tb [,限制] )
返回从追溯对象tb中提取的最多限制 “预处理”堆栈跟踪条目的列表。它对堆栈跟踪的替代格式化很有用。如果省略limit,则提取所有条目。“预处理”堆栈跟踪条目是4元组(文件名,行号,函数名*,文本),表示通常为堆栈跟踪打印的信息。该文本是开头和结尾的空白剥离的字符串; 如果源不可用则是。NoneNone
traceback.extract_stack([ f [,limit ] ] )
从当前堆栈帧中提取原始回溯。返回值的格式与extract_tb()。可选的f和limit 参数具有与之相同的含义print_stack()。
traceback.format_list(extracted_list )
给定由extract_tb()or extract_stack()返回的元组列表,返回准备打印的字符串列表。结果列表中的每个字符串对应于参数列表中具有相同索引的项。每个字符串以换行符结尾; 对于那些源文本行不是的项目,字符串也可以包含内部换行符 None。
traceback.format_exception_only(etype,value )
格式化回溯的异常部分。参数是异常类型,etype和值,例如由sys.last_type和 给出的sys.last_value。返回值是一个字符串列表,每个字符串以换行符结尾。通常,列表包含单个字符串; 但是,对于 SyntaxError异常,它包含多行(打印时)显示有关语法错误发生位置的详细信息。指示发生了哪个异常的消息是列表中的始终最后一个字符串。
traceback.format_exception(etype,value,tb [,limit ] )
格式化堆栈跟踪和异常信息。参数与相应的参数具有相同的含义print_exception()。返回值是一个字符串列表,每个字符串以换行符结尾,一些包含内部换行符。连接和打印这些行时,将打印完全相同的文本print_exception()。
traceback.format_tb(tb [,限制] )
简写。format_list(extract_tb(tb, limit))
traceback.format_stack([ f [,limit ] ] )
简写。format_list(extract_stack(f, limit))
traceback.tb_lineno(tb )
此函数返回traceback对象中设置的当前行号。这个函数是必要的,因为在2.3之前的Python版本中,当-O标志传递给Python时,tb.tb_lineno没有正确更新。此功能在2.3版本中没有用处。
回溯示例
这个简单的例子实现了一个基本的read-eval-print循环,类似于标准Python交互式解释器循环(但不太有用)。有关解释器循环的更完整实现,请参阅该code 模块。
import sys, traceback
def run_user_code(envdir):
source = raw_input(">>> ")
try:
exec source in envdir
except:
print "Exception in user code:"
print '-'*60
traceback.print_exc(file=sys.stdout)
print '-'*60
envdir = {}
while 1:
run_user_code(envdir)
以下示例演示了打印和格式化异常和回溯的不同方法:
import sys, traceback
def lumberjack():
bright_side_of_death()
def bright_side_of_death():
return tuple()[0]
try:
lumberjack()
except IndexError:
exc_type, exc_value, exc_traceback = sys.exc_info()
print "*** print_tb:"
traceback.print_tb(exc_traceback, limit=1, file=sys.stdout)
print "*** print_exception:"
traceback.print_exception(exc_type, exc_value, exc_traceback,
limit=2, file=sys.stdout)
print "*** print_exc:"
traceback.print_exc()
print "*** format_exc, first and last line:"
formatted_lines = traceback.format_exc().splitlines()
print formatted_lines[0]
print formatted_lines[-1]
print "*** format_exception:"
print repr(traceback.format_exception(exc_type, exc_value,
exc_traceback))
print "*** extract_tb:"
print repr(traceback.extract_tb(exc_traceback))
print "*** format_tb:"
print repr(traceback.format_tb(exc_traceback))
print "*** tb_lineno:", exc_traceback.tb_lineno
该示例的输出看起来类似于:
*** print_tb:
File "<doctest...>", line 10, in <module>
lumberjack()
*** print_exception:
Traceback (most recent call last):
File "<doctest...>", line 10, in <module>
lumberjack()
File "<doctest...>", line 4, in lumberjack
bright_side_of_death()
IndexError: tuple index out of range
*** print_exc:
Traceback (most recent call last):
File "<doctest...>", line 10, in <module>
lumberjack()
File "<doctest...>", line 4, in lumberjack
bright_side_of_death()
IndexError: tuple index out of range
*** format_exc, first and last line:
Traceback (most recent call last):
IndexError: tuple index out of range
*** format_exception:
['Traceback (most recent call last):\n',
' File "<doctest...>", line 10, in <module>\n lumberjack()\n',
' File "<doctest...>", line 4, in lumberjack\n bright_side_of_death()\n',
' File "<doctest...>", line 7, in bright_side_of_death\n return tuple()[0]\n',
'IndexError: tuple index out of range\n']
*** extract_tb:
[('<doctest...>', 10, '<module>', 'lumberjack()'),
('<doctest...>', 4, 'lumberjack', 'bright_side_of_death()'),
('<doctest...>', 7, 'bright_side_of_death', 'return tuple()[0]')]
*** format_tb:
[' File "<doctest...>", line 10, in <module>\n lumberjack()\n',
' File "<doctest...>", line 4, in lumberjack\n bright_side_of_death()\n',
' File "<doctest...>", line 7, in bright_side_of_death\n return tuple()[0]\n']
*** tb_lineno: 10
以下示例显示了打印和格式化堆栈的不同方法:
import traceback
def another_function():
lumberstack()
def lumberstack():
traceback.print_stack()
print repr(traceback.extract_stack())
print repr(traceback.format_stack())
another_function()
File "<doctest>", line 10, in <module>
another_function()
File "<doctest>", line 3, in another_function
lumberstack()
File "<doctest>", line 6, in lumberstack
traceback.print_stack()
[('<doctest>', 10, '<module>', 'another_function()'),
('<doctest>', 3, 'another_function', 'lumberstack()'),
('<doctest>', 7, 'lumberstack', 'print repr(traceback.extract_stack())')]
[' File "<doctest>", line 10, in <module>\n another_function()\n',
' File "<doctest>", line 3, in another_function\n lumberstack()\n',
' File "<doctest>", line 8, in lumberstack\n print repr(traceback.format_stack())\n']
最后一个示例演示了最后几个格式化函数:
import traceback
traceback.format_list([('spam.py', 3, '<module>', 'spam.eggs()'),
('eggs.py', 42, 'eggs', 'return "bacon"')])
[' File "spam.py", line 3, in <module>\n spam.eggs()\n',
' File "eggs.py", line 42, in eggs\n return "bacon"\n']
an_error = IndexError('tuple index out of range')
traceback.format_exception_only(type(an_error), an_error)
['IndexError: tuple index out of range\n']
以上这篇python3 使用traceback定位异常实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python traceback捕获并打印异常的方法
异常处理是日常操作了,但是有时候不能只能打印我们处理的结果,还需要将我们的异常打印出来,这样更直观的显示错误 下面来介绍traceback模块来进行处理 try: 1/0 except Exception, e: print e 输出结果是integer division or modulo by zero,只知道是报了这个错,但是却不知道在哪个文件哪个函数哪一行报的错. 使用traceback try: 1/0 except Exception, e: traceback.print_exc(
-
Python random库使用方法及异常处理方案
1.random库的使用: random库是使用随机数的Python标准库 从概率论角度来说,随机数是随机产生的数据(比如抛硬币),但时计算机是不可能产生随机值,真正的随机数也是在特定条件下产生的确定值,只不过这些条件我们没有理解,或者超出了我们的理解范围.计算机不能产生真正的随机数,那么伪随机数也就被称为随机数 --伪随机数:计算机中通过采用梅森旋转算法生成的(伪)随机序列元素 python中用于生成伪随机数的函数库是random 因为是标准库,使用时候只需要importrandom rand
-
Python使用try except处理程序异常的三种常用方法分析
本文实例讲述了Python使用try except处理程序异常的三种常用方法.分享给大家供大家参考,具体如下: 如果你在写python程序时遇到异常后想进行如下处理的话,一般用try来处理异常,假设有下面的一段程序: try: 语句1 语句2 . . 语句N except .........: do something ....... 但是你并不知道"语句1至语句N"在执行会出什么样的异常,但你还要做异常处理,且想把出现的异常打印出来,并不停止程序的运行,所以在"except
-
浅谈Python traceback的优雅处理
刚接触Python的时候,简单的异常处理已经可以帮助我们解决大多数问题,但是随着逐渐地深入,我们会发现有很多情况下简单的异常处理已经无法解决问题了,如下代码,单纯的打印异常所能提供的信息会非常有限. def func1(): raise Exception("--func1 exception--") def main(): try: func1() except Exception as e: print e if __name__ == '__main__': main() 执行后
-
基于python traceback实现异常的获取与处理
这篇文章主要介绍了基于python traceback实现异常的获取与处理,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.traceback.print_exc() 2.traceback.format_exc() 3.traceback.print_exception() 简单说下这三个方法是做什么用的: 1.print_exc():是对异常栈输出 2.format_exc():是把异常栈以字符串的形式返回,print(traceback
-
python3 使用traceback定位异常实例
1.我们使用正常的输出语句 得到的是(输出结果:division by zero)虽然得到了错误的日志输出,但是不知道为什么出错,也不能定位具体出错位置. 2.现在我们使用 traceback 就可以得到具体的错误,以及定位到出错的位置.这样就能更方便调试错误. 参考文献 traceback文档地址: https://docs.python.org/2/library/traceback.html 以下为google翻译(仅供参考,): 该模块提供了一个标准接口,用于提取,格式化和打印Pytho
-
python3中使用__slots__限定实例属性操作分析
本文实例讲述了python3中使用__slots__限定实例属性操作.分享给大家供大家参考,具体如下: 正常情况下,当我们定义了一个class,创建了一个class的实例后,我们可以给该实例绑定任何属性和方法,这就是动态语言的灵活性.先定义class: # 类定义 class Person(object): pass 然后,尝试给实例绑定一个属性: p = Person() p.name = "jadeshu" print(p.name) 输出: jadeshu 还可以尝试给实例绑定一
-

Python3操作SQL Server数据库(实例讲解)
1.前言 前面学完了SQL Server的基本语法,接下来学习如何在程序中使用sql,毕竟不能在程序中使用的话,实用性就不那么大了. 2.最基本的SQL查询语句 python是使用pymssql这个模块来操作SQL Server数据库的,所有需要先安装pymssql. 这个直接在命令行里输入pip install pymssql安装就行了 然后还要配置好自己本地的SQL Server数据库,进入Microsoft SQL Server Management Studio中可以进行设置.如果你选择
-
.NET程序调试技巧(一):快速定位异常的一些方法
作为一个程序员,解BUG是我们工作中常做的工作,甚至可以说解决问题能力是一个人工作能力的重要体现.因为这体现了一个程序员的技术水平.技术深度.经验等等. 那么在我们解决BUG的过程中,定位问题是非常重要的.有句话叫"发现问题是解决问题的一半. 本文讲述就快速定位异常(专指.NET程序异常)的方法.包括在本机定位异常,在客户环境定位.net程序异常,在客户环境定位SilverLight异常. 一:定位本机异常 在我们本机定位异常很容易.假设我们都是使用的的VisualStudio,那么只需要在调试
-
python3之微信文章爬虫实例讲解
前提: python3.4 windows 作用:通过搜狗的微信搜索接口http://weixin.sogou.com/来搜索相关微信文章,并将标题及相关链接导入Excel表格中 说明:需xlsxwriter模块,另程序编写时间为2017/7/11,以免之后程序无法使用可能是网站做过相关改变,程序较为简单,除去注释40多行. 正题: 思路:打开初始Url --> 正则获取标题及链接 --> 改变page循环第二步 --> 将得到的标题及链接导入Excel 爬虫的第一步都是先手工操作一遍(
-
Python3.6 Schedule模块定时任务(实例讲解)
一,编程环境 PyCharm2016,Anaconda3 Python3.6 需要安装schedule模块,该模块网址:https://pypi.python.org/pypi/schedule 打开Anaconda Prompt,输入:conda install schedule 提示:Package Not Found Error 于是,使用 pip 安装.由于Anaconda3 中已经自带了pip,如下图: 于是 cmd 命令行切换到 scripts 目录,执行 pip.exe insta
-
Python3处理HTTP请求的实例
Python3处理HTTP请求的包:http.client,urllib,urllib3,requests 其中,http 比较 low-level,一般不直接使用 urllib更 high-level一点,属于标准库.urllib3跟urllib类似,拥有一些重要特性而且易于使用,但是属于扩展库,需要安装 requests 基于urllib3 ,也不是标准库,但是使用非常方便 个人感觉,如果非要用标准库,就使用urllib.如果没有限制,就用requests # import http.cli
-
python3实现字符串操作的实例代码
python3字符串操作 x = 'abc' y = 'defgh' print(x + y) #x+y print(x * 3) #x*n print(x[2]) #x[i] print(y[0:-1]) #str[i:j] #求长度 >>> len(x) 11 #将其他类型转换为字符串 >>> str(123) '123' #将数字转为对应的utf-8字符 >>> chr(97) 'a' #将字符转为对应的数字 >>> ord('
-
使用python3+xlrd解析Excel的实例
实例如下所示: # -*- coding: utf-8 -*- import xlrd def open_excel(file = 'file.xls'):#打开要解析的Excel文件 try: data = xlrd.open_workbook(file) return data except Exception as e: print(e) def excel_by_index(file = 'file.xls', colindex = 0, by_index = 0):#按表的索引读取 d
-
python3.7简单的爬虫实例详解
python3.7简单的爬虫,具体代码如下所示: #https://www.runoob.com/w3cnote/python-spider-intro.html #Python 爬虫介绍 import urllib.parse import urllib.request from http import cookiejar url = "http://www.baidu.com" response1 = urllib.request.urlopen(url) print("