简述python&pytorch 随机种子的实现
随机数广泛应用在科学研究, 但是计算机无法产生真正的随机数, 一般成为伪随机数. 它的产生过程: 给定一个随机种子(一个正整数), 根据随机算法和种子产生随机序列. 给定相同的随机种子, 计算机产生的随机数列是一样的(这也许是伪随机的原因).
随机种子是什么?
随机种子是针对随机方法而言的。
随机方法:常见的随机方法有 生成随机数,以及其他的像 随机排序 之类的,后者本质上也是基于生成随机数来实现的。在深度学习中,比较常用的随机方法的应用有:网络的随机初始化,训练集的随机打乱等。
随机种子的取值范围?
可以是任意数字,如10,1000
python random
下面以python的random函数为例, 做了一个测试.
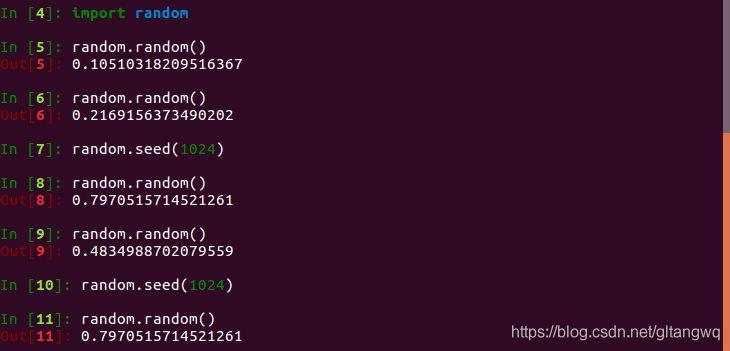
当用户未指定随机种子, 系统默认随机生成, 一般与系统当前时间有关.用户指定随机种子后, 使用随机函数产生的随机数可以复现.种子确定后, 每次使用随机函数相当于从随机序列去获取随机数, 每次获取的随机数是不同的.
pytorch
使用pytorch复现效果时, 总是无法做到完全的复现. 同一份代码运行两次, 有时结果差异很大. 这是由于算法中的随机性导致的. 要想每次获得的结果一致, 必须固定住随机种子. 首先, 我们需要找到算法在哪里使用了随机性, 再相应的固定住随机种子.
def seed_torch():
seed = 1024 # 用户设定
# seed = int(time.time()*256)
# 保存随机种子
with open('seed.txt', 'w') as f:
f.write(str(seed))
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
seed_torch()
上面的代码固定了pytorch常用的随机种子, 但是如果你在预处理中涉及了随机性, 也需要固定住.
为了复现结果, 我们固定住了随机种子. 但pytorch训练模型时, 不同的随机种子会产生不同的结果. 每次使用固定的随机种子, 可能错失好的结果. 为此, 我们可以每次使用不一样的随机种子, 并保存下来
到此这篇关于简述python&pytorch 随机种子的实现的文章就介绍到这了,更多相关pytorch 随机种子内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch生成随机数Tensor的方法汇总
在使用PyTorch做实验时经常会用到生成随机数Tensor的方法,比如: torch.rand() torch.randn() torch.normal() torch.linespace() 均匀分布 torch.rand(*sizes, out=None) → Tensor 返回一个张量,包含了从区间[0, 1)的均匀分布中抽取的一组随机数.张量的形状由参数sizes定义. 参数: sizes (int-) - 整数序列,定义了输出张量的形状 out (Tensor, optinal) -
-
pytorch随机采样操作SubsetRandomSampler()
这篇文章记录一个采样器都随机地从原始的数据集中抽样数据.抽样数据采用permutation. 生成任意一个下标重排,从而利用下标来提取dataset中的数据的方法 需要的库 import torch 使用方法 这里以MNIST举例 train_dataset = dsets.MNIST(root='./data', #文件存放路径 train=True, #提取训练集 transform=transforms.ToTensor(), #将图像转化为Tensor download=True) sa
-
pytorch实现保证每次运行使用的随机数都相同
其实在代码的开头添加下面几句话即可: # 保证训练时获取的随机数都是一样的 init_seed = 1 torch.manual_seed(init_seed) torch.cuda.manual_seed(init_seed) np.random.seed(init_seed) # 用于numpy的随机数 torch.manual_seed(seed) 为了生成随机数设置种子.返回一个torch.Generator对象 参数: seed (int) – 期望的种子数 torch.cuda.ma
-
Pytorch在dataloader类中设置shuffle的随机数种子方式
如题:Pytorch在dataloader类中设置shuffle的随机数种子方式 虽然实验结果差别不大,但是有时候也悬殊两个百分点 想要复现实验结果 发现用到随机数的地方就是dataloader类中封装的shuffle属性 查了半天没有关于这个的设置,最后在设置随机数种子里面找到了答案 以下方法即可: def setup_seed(seed): torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) np.random.seed(seed
-
PyTorch 随机数生成占用 CPU 过高的解决方法
PyTorch 随机数生成占用 CPU 过高的问题 今天在使用 pytorch 的过程中,发现 CPU 占用率过高.经过检查,发现是因为先在 CPU 中生成了随机数,然后再调用.to(device)传到 GPU,这样导致效率变得很低,并且CPU 和 GPU 都被消耗. 查阅PyTorch文档后发现,torch.randn(shape, out)可以直接在GPU中生成随机数,只要shape是tensor.cuda.Tensor类型即可.这样,就可以避免在 CPU 中生成过大的矩阵,而 shape
-
简述python&pytorch 随机种子的实现
随机数广泛应用在科学研究, 但是计算机无法产生真正的随机数, 一般成为伪随机数. 它的产生过程: 给定一个随机种子(一个正整数), 根据随机算法和种子产生随机序列. 给定相同的随机种子, 计算机产生的随机数列是一样的(这也许是伪随机的原因). 随机种子是什么? 随机种子是针对随机方法而言的. 随机方法:常见的随机方法有 生成随机数,以及其他的像 随机排序 之类的,后者本质上也是基于生成随机数来实现的.在深度学习中,比较常用的随机方法的应用有:网络的随机初始化,训练集的随机打乱等. 随机种子的取值
-
python设置随机种子实例讲解
对于原生的random模块 import random random.seed(1) 如果不设置,则python根据系统时间自己定一个. 也可以自己根据时间定一个随机种子,如: import time import random seed = int(time.time()) random.seed(seed) 以上知识点和实例非常简单,大家可以测试下,感谢你的学习和对我们的支持.
-
pytorch通过训练结果的复现设置随机种子
通过设置全局随机种子使得每次的训练结果相同可以复现 def seed_torch(seed=2018): random.seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) np.random.seed(seed) torch.manual_seed(seed) torch.cuda.manual_seed(seed) torch.backends.cudnn.deterministic = True 这里我主要讲一下模型在复现结果遇到的一些问题
-

Python Pytorch深度学习之数据加载和处理
目录 一.下载安装包 二.下载数据集 三.读取数据集 四.编写一个函数看看图像和landmark 五.数据集类 六.数据可视化 七.数据变换 1.Function_Rescale 2.Function_RandomCrop 3.Function_ToTensor 八.组合转换 九.迭代数据集 总结 一.下载安装包 packages: scikit-image:用于图像测IO和变换 pandas:方便进行csv解析 二.下载数据集 数据集说明:该数据集(我在这)是imagenet数据集标注为fac
-
Python NumPy随机抽模块介绍及方法
目录 1. 随机数 2. 随机抽样 3. 正态分布 4. 伪随机数的深度思考 1. 随机数 np.random.random()是最常用的随机数生成函数,该函数生成的随机数随机均匀分布于[0, 1)区间.如果不提供参数,np.random.random()函数返回一个浮点型随机数.np.random.random()函数还可以接受一个整型或元组参数,用于指定返回的浮点型随机数数组的结构(shape).也有很多人习惯使用np.random.rand()函数生成随机数,其功能和np.random.r
-
Python生成随机验证码的两种方法
使用python生成随机验证码的方法有很多种,今天小编给大家分享两种方法,大家可以灵活运用这两种方法,设计出适合自己的验证码方法. 方法一: 利用range方法,对于range方法不清楚的同学,请参考文章<python开发的range()函数> # -*- coding: utf-8 -*- import random def generate_verification_code(len=6): ''' 随机生成6位的验证码 ''' # 注意: 这里我们生成的是0-9A-Za-z的列表,当然你
-
Python生成随机数组的方法小结
本文实例讲述了Python生成随机数组的方法.分享给大家供大家参考,具体如下: 研究排序问题的时候常常需要生成随机数组来验证自己排序算法的正确性和性能,今天把Python生成随机数组的方法稍作总结,以备以后查看使用. 一.使用random模块生成随机数组 python的random模块中有一些生成随机数字的方法,例如random.randint, random.random, random.uniform, random.randrange,这些函数大同小异,均是在返回指定范围内的一个整数或浮点
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,
-
python生成随机mac地址的方法
本文实例讲述了python生成随机mac地址的方法.分享给大家供大家参考.具体实现方法如下: #!/usr/bin/python import random def randomMAC(): mac = [ 0x52, 0x54, 0x00, random.randint(0x00, 0x7f), random.randint(0x00, 0xff), random.randint(0x00, 0xff) ] return ':'.join(map(lambda x: "%02x" %