Pandas中常用的七个时间戳处理函数使用总结
目录
- 1、查找特定日期的某一天的名称
- 2、执行算术计算
- 3、使用时区信息来操作转换日期时间
- 4、使用日期时间戳
- 5、创建日期系列
- 6、操作日期序列
- 7、使用时间戳数据对数据进行切片
在零售、经济和金融等行业,数据总是由于货币和销售而不断变化,生成的所有数据都高度依赖于时间。如果这些数据没有时间戳或标记,实际上很难管理所有收集的数据。Python 程序允许我们使用 NumPy timedelta64 和 datetime64 来操作和检索时间序列数据。sklern库中也提供时间序列功能,但 Pandas 为我们提供了更多且好用的函数。
Pandas 库中有四个与时间相关的概念
- 日期时间:日期时间表示特定日期和时间及其各自的时区。它在 pandas 中的数据类型是 datetime64[ns] 或 datetime64[ns, tz]。
- 时间增量:时间增量表示时间差异,它们可以是不同的单位。示例:“天、小时、减号”等。换句话说,它们是日期时间的子类。
- 时间跨度:时间跨度被称为固定周期内的相关频率。时间跨度的数据类型是 period[freq]。
- 日期偏移:日期偏移有助于从当前日期计算选定日期,日期偏移量在 pandas 中没有特定的数据类型。
时间序列分析至关重要,因为它们可以帮助我们了解随着时间的推移影响趋势或系统模式的因素。在数据可视化的帮助下,分析并做出后续决策。
现在让我们看几个使用这些函数的例子
1、查找特定日期的某一天的名称
import pandas as pd day = pd.Timestamp(‘2021/1/5') day.day_name()

上面的程序是显示特定日期的名称。第一步是导入 panda 的并使用 Timestamp 和 day_name 函数。“Timestamp”功能用于输入日期,“day_name”功能用于显示指定日期的名称。
2、执行算术计算
import pandas as pd day = pd.Timestamp(‘2021/1/5') day1 = day + pd.Timedelta(“3 day”) day1.day_name() day2 = day1 + pd.offsets.BDay() day2.day_name()

在第一个代码中,显示三天后日期名称。“Timedelta”功能允许输入任何天单位(天、小时、分钟、秒)的时差。
在第二个代码中,使用“offsets.BDay()”函数来显示下一个工作日。换句话说,这意味着在星期五之后,下一个工作日是星期一。
3、使用时区信息来操作转换日期时间
获取时区的信息
import pandas as pd import numpy as np from datetime import datetime dat_ran = dat_ran.tz_localize(“UTC”) dat_ran
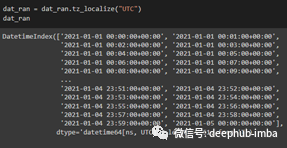
转换为美国时区
dat_ran.tz_convert(“US/Pacific”)

代码的目标是更改日期的时区。首先需要找到当前时区。这是“tz_localize()”函数完成的。我们现在知道当前时区是“UTC”。使用“tz_convert()”函数,转换为美国/太平洋时区。
4、使用日期时间戳
import pandas as pd import numpy as np from datetime import datetime dat_ran = pd.date_range(start = ‘1/1/2021', end = ‘1/5/2021', freq = ‘Min') print(type(dat_ran[110]))

5、创建日期系列
import pandas as pd import numpy as np from datetime import datetime dat_ran = pd.date_range(start = ‘1/1/2021', end = ‘1/5/2021', freq = ‘Min') print(dat_ran)

上面的代码生成了一个日期系列的范围。使用“date_range”函数,输入开始和结束日期,可以获得该范围内的日期。
6、操作日期序列
import pandas as pd from datetime import datetime import numpy as np dat_ran = pd.date_range(start ='1/1/2019', end ='1/08/2019',freq ='Min') df = pd.DataFrame(dat_ran, columns =[‘date']) df[‘data'] = np.random.randint(0, 100, size =(len(dat_ran))) print(df.head(5))
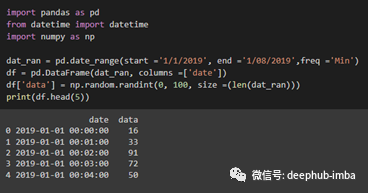
在上面的代码中,使用“DataFrame”函数将字符串类型转换为dataframe。最后“np.random.randint()”函数是随机生成一些假定的数据。
7、使用时间戳数据对数据进行切片
import pandas as pd from datetime import datetime import numpy as np dat_ran = pd.date_range(start ='1/1/2019', end ='1/08/2019', freq ='Min') df = pd.DataFrame(dat_ran, columns =[‘date']) df[‘data'] = np.random.randint(0, 100, size =(len(dat_ran))) string_data = [str(x) for x in dat_ran] print(string_data[1:5])

上面代码是是第6条的的延续。在创建dataframe并将其映射到随机数后,对列表进行切片。
最后总结,本文通过示例演示了时间序列和日期函数的所有基础知识。建议参考本文中的内容并尝试pandas中的其他日期函数进行更深入的学习,因为这些函数在我们实际工作中非常的重要。
以上就是Pandas中常用的七个时间戳处理函数使用总结的详细内容,更多关于Pandas时间戳处理函数的资料请关注我们其它相关文章!
相关推荐
-
Python获取网络时间戳的两种方法详解
目录 方法一 代码实现 调用方法 返回结果 方法二 代码实现 调用方法 返回结果 在我们进行注册码的有效期验证时,通常使用获取网络时间的方式来进行比对. 以下为获取网络时间的几种方式. 方法一 需要的时间会比较长,个别电脑上可能会出现不兼容现象 代码实现 def get_web_server_time(self, host_URL, year_str='-', time_str=':'): ''' 获取网络时间,需要的时间会比较长,个别电脑上可能会出现不兼容现象 :param host_URL:
-
python如何快速生成时间戳
import time now_time = time.time() print(now_time) 结果是 1594604269.1730552 知识点扩展: 获取秒级时间戳与毫秒级时间戳.微秒级时间戳 import time import datetime t = time.time() print (t) #原始时间数据 print (int(t)) #秒级时间戳 print (int(round(t * 1000))) #毫秒级时间戳 print (int(round(t * 10000
-
Python 转换时间戳为指定格式日期
目录 当前时间 实例1: 实例2: 指定时间戳 实例1: 实例2: 总结 我们将会启用到time库: 当前时间 实例1: import time # 获得当前时间时间戳 now = int(time.time()) #转换为其他日期格式,如:"%Y-%m-%d %H:%M:%S" timeArray = time.localtime(now) otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
-
Python Pandas 转换unix时间戳方式
使用pandas自带的pd.to_datetime把 unix 时间戳转为时间时默认是转换为 GMT标准时间 北京时间比这个时间还要加 8个小时, 使用python 自带的 time.localtime 转换时 默认是会处理好时区的问题,可以直接转换为 北京时间的: pandas需要自己处理时区问题 如果是pandas的字段(df.TIME为格式如上的时间戳)可以使用下面的方式转换: 以上这篇Python Pandas 转换unix时间戳方式就是小编分享给大家的全部内容了,希望能给大家一个参考
-
利用Pandas和Numpy按时间戳将数据以Groupby方式分组
首先说一下需求,我需要将数据以分钟为单位进行分组,然后每一分钟内的数据作为一行输出,因为不同时间的数据量不一样,所以所有数据按照最长的那组数据为准,不足的数据以各自的最后一个数据进行补足. 之后要介绍一下我的数据源,之前没用的数据列已经去除,我只留下要用到的数据data列和时间戳time列,时间戳是以秒计的,可以看到一共是407454行. data time 0 6522.50 1.530668e+09 1 6522.66 1.530668e+09 2 6523.79 1.530668e+09
-
Pandas-Cookbook 时间戳处理方式
我就废话不多说,直接上代码吧! # -*-coding:utf-8-*- # by kevinelstri # 2017.2.17 # --------------------- # Chapter 8 - How to deal with timestamps.ipynb # --------------------- import pandas as pd ''' 8.1 Parsing Unix timestamps ''' popcon = pd.read_csv('../data/po
-

Pandas中常用的七个时间戳处理函数使用总结
目录 1.查找特定日期的某一天的名称 2.执行算术计算 3.使用时区信息来操作转换日期时间 4.使用日期时间戳 5.创建日期系列 6.操作日期序列 7.使用时间戳数据对数据进行切片 在零售.经济和金融等行业,数据总是由于货币和销售而不断变化,生成的所有数据都高度依赖于时间.如果这些数据没有时间戳或标记,实际上很难管理所有收集的数据.Python 程序允许我们使用 NumPy timedelta64 和 datetime64 来操作和检索时间序列数据.sklern库中也提供时间序列功能,但 Pan
-
pandas中字典和dataFrame的相互转换
目录 一.字典转dataFrame 1.字典转dataFrame比较简单,直接给出示例: 二.dataFrame转字典 1.DataFrame.to_dict() 函数介绍 2.orient =‘dict’ 3. orient =‘list’ 4.orient =‘series’ 5.orient =‘split’ 6.orient =‘records’ 7.orient =‘index’ 8.指定列为key生成字典的实现步骤(按行) 9.指定列为key,value生成字典的实现 总结 一.字典
-
Pandas中八个常用option设置的示例详解
目录 前言 1. 显示更多行 2. 显示更多列 3. 改变列宽 4. 设置float列的精度 5. 数字格式化显示 用逗号格式化大值数字 设置数字精度 百分号格式化 6. 更改绘图方法 7. 配置info()的输出 8. 打印出当前设置并重置所有选项 前言 通过pandas的使用,我们经常要交互式地展示表格(dataframe).分析表格.而表格的格式就显得尤为重要了,因为大部分时候如果我们直接展示表格,格式并不是很友好. 其实呢,这些痛点都可以通过pandas的option来解决.短短几行代码
-
Pandas中Series的属性,方法,常用操作使用案例
目录 1. Series 对象的创建 1.1 创建一个空的 Series 对象 1.2 通过列表创建一个 Series 对象 1.3 通过元组创建一个 Series 对象 1.4 通过字典创建一个 Series 对象 1.5 通过 ndarray 创建一个 Series 对象 1.6 创建 Series 对象时指定索引 1.7 通过一个标量(数)创建一个 Series 对象 2. Series 的属性 2.1 values ---- 返回一个 ndarray 数组 2.2 index ----
-
Pandas中DataFrame常用操作指南
目录 前言 1. 基本使用: 2. 数据select, del, update. 3.运算. 4. Group by 操作. 5. 导出到csv文件 总结 前言 Pandas是Python下一个开源数据分析的库,它提供的数据结构DataFrame极大的简化了数据分析过程中一些繁琐操作. 1. 基本使用: 创建DataFrame. DataFrame是一张二维的表,大家可以把它想象成一张Excel表单或者Sql表. Excel 2007及其以后的版本的最大行数是1048576,最大列数是16384
-
Pandas中resample方法详解
Pandas中的resample,重新采样,是对原样本重新处理的一个方法,是一个对常规时间序列数据重新采样和频率转换的便捷的方法. 方法的格式是: DataFrame.resample(rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start',kind=None, loffset=None, limit=None, base=0) 参数详解是: 参数 说明 freq 表示重采样频率,
-
工作中常用js的汇总
一.javascript 中防止重复点击.防止点击过快 防止重复点击可以添加一个开关,让这个开关默认为 true,第一次点击将其变为 false,点击事件的执行需要判断这个开关是否为 true,为 true 执行,false 不执行.例子如下: var isclick= true; function click(){ if(isclick){ isclick = false; //下面添加需要执行的事件 ... } 如果只是防止点击过快,还可以设置定时器,在一定时间后,自动将开关变为 true,
-
详解pandas中缺失数据处理的函数
目录 一.缺失值类型 1.np.nan 2.None 3.NA标量 二.缺失值判断 1.对整个dataframe判断缺失 2.对某个列判断缺失 三.缺失值统计 1.列缺失 2.行缺失 3.缺失率 四.缺失值筛选 五.缺失值填充 六.缺失值删除 1.全部直接删除 2.行缺失删除 3.列缺失删除 4.按缺失率删除 七.缺失值参与计算 1.加法 2.累加 3.计数 4.聚合分组 五.源码 今天分享一篇pandas缺失值处理的操作指南! 一.缺失值类型 在pandas中,缺失数据显示为NaN.缺失值有3
-
工作中常用js功能汇总
一.javascript 中防止重复点击.防止点击过快 防止重复点击可以添加一个开关,让这个开关默认为 true,第一次点击将其变为 false,点击事件的执行需要判断这个开关是否为 true,为 true 执行,false 不执行.例子如下: var isclick= true; function click(){ if(isclick){ isclick = false; //下面添加需要执行的事件 ... } 如果只是防止点击过快,还可以设置定时器,在一定时间后,自动将开关变为 true,
-
Extjs中常用表单介绍与应用
目标: 知道表单面板如何创建 了解表单面板中xtype的类型的应用 知道表单面板如何验证,绑定,取值 综合应用表单面板(玩转它) 内容: 首先我们要理解的是FormPanel也是继承panel组件的.所以它有着panel的属性 要创建一个表单面板其实很简单 var MyformPanel=new Ext.form.formpanel(); 表单面板和面板一样只是作为一个容器出现的,需要我们使用items加入各控件元素来丰富我们的表单面板, defaults:{},此属性提取了items中各组件项