Keras神经网络efficientnet模型搭建yolov3目标检测平台
目录
- 什么是EfficientNet模型
- 源码下载
- EfficientNet模型的实现思路
- 1、EfficientNet模型的特点
- 2、EfficientNet网络的结构
- EfficientNet的代码构建
- 1、模型代码的构建
- 2、Yolov3上的应用
什么是EfficientNet模型
2019年,谷歌新出EfficientNet,在其它网络的基础上,大幅度的缩小了参数的同时提高了预测准确度,简直太强了,我这样的强者也要跟着做下去
EfficientNet,网络如其名,这个网络非常的有效率,怎么理解有效率这个词呢,我们从卷积神经网络的发展来看:
从最初的VGG16发展到如今的Xception,人们慢慢发现,提高神经网络的性能不仅仅在于堆叠层数,更重要的几点是:
1、网络要可以训练,可以收敛。
2、参数量要比较小,方便训练,提高速度。
3、创新神经网络的结构,学到更重要的东西。
而EfficientNet很好的做到了这一点,它利用更少的参数量(关系到训练、速度)得到最好的识别度(学到更重要的特点)。
源码下载
https://github.com/bubbliiiing/efficientnet-yolo3-keras
EfficientNet模型的实现思路
1、EfficientNet模型的特点
EfficientNet模型具有很独特的特点,这个特点是参考其它优秀神经网络设计出来的。经典的神经网络特点如下:
1、利用残差神经网络增大神经网络的深度,通过更深的神经网络实现特征提取。
2、改变每一层提取的特征层数,实现更多层的特征提取,得到更多的特征,提升宽度。
3、通过增大输入图片的分辨率也可以使得网络可以学习与表达的东西更加丰富,有利于提高精确度。
EfficientNet就是将这三个特点结合起来,通过一起缩放baseline模型(MobileNet中就通过缩放α实现缩放模型,不同的α有不同的模型精度,α=1时为baseline模型;
ResNet其实也是有一个baseline模型,在baseline的基础上通过改变图片的深度实现不同的模型实现),同时调整深度、宽度、输入图片的分辨率完成一个优秀的网络设计。
EfficientNet的效果如下:

在EfficientNet模型中,其使用一组固定的缩放系数统一缩放网络深度、宽度和分辨率。
假设想使用 2N倍的计算资源,我们可以简单的对网络深度扩大αN倍、宽度扩大βN 、图像尺寸扩大γN倍,这里的α,β,γ都是由原来的小模型上做微小的网格搜索决定的常量系数。
如图为EfficientNet的设计思路,从三个方面同时拓充网络的特性。

2、EfficientNet网络的结构
EfficientNet一共由一个Stem + 16个Blocks + Con2D + GlobalAveragePooling2D + Dense组成,其核心内容是16个Blocks,其它的结构与常规的卷积神经网络差距不大。
下图展示的是EfficientNet-B0也就是EfficientNet的设计基线的结构:

第一部分是Stem,用于进行初步的特征提取,实际内容是一个卷积+标准化+激活函数。
第二部分是16个Blocks,是efficientnet特有的特征提取结构,在Blocks堆叠的过程中完成高效的特征提取。
第三部分是Con2D + GlobalAveragePooling2D + Dense,是efficientnet的分类头,在构建efficientnet-yolov3的时候没有使用到。
整个efficientnet由7个部分的Block组成,对应上图的Block1-Block7,其中每个部分的Block的的参数如下:
DEFAULT_BLOCKS_ARGS = [
{'kernel_size': 3, 'repeats': 1, 'filters_in': 32, 'filters_out': 16,
'expand_ratio': 1, 'id_skip': True, 'strides': 1, 'se_ratio': 0.25},
{'kernel_size': 3, 'repeats': 2, 'filters_in': 16, 'filters_out': 24,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 5, 'repeats': 2, 'filters_in': 24, 'filters_out': 40,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 3, 'repeats': 3, 'filters_in': 40, 'filters_out': 80,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 5, 'repeats': 3, 'filters_in': 80, 'filters_out': 112,
'expand_ratio': 6, 'id_skip': True, 'strides': 1, 'se_ratio': 0.25},
{'kernel_size': 5, 'repeats': 4, 'filters_in': 112, 'filters_out': 192,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 3, 'repeats': 1, 'filters_in': 192, 'filters_out': 320,
'expand_ratio': 6, 'id_skip': True, 'strides': 1, 'se_ratio': 0.25}
]
Block的通用结构如下,其总体的设计思路是一个结合深度可分离卷积和注意力机制的逆残差结构,每个Block可分为两部分:
左边为主干部分,首先利用1x1卷积升维,再使用3x3或者5x5的逐层卷积进行跨特征点的特征提取。完成特征提取后添加一个通道注意力机制,最后利用1x1卷积降维。
右边为残差边,不进行处理。

Block实现代码如下:
#-------------------------------------------------#
# efficient_block
#-------------------------------------------------#
def block(inputs, activation_fn=tf.nn.swish, drop_rate=0., name='',
filters_in=32, filters_out=16, kernel_size=3, strides=1,
expand_ratio=1, se_ratio=0., id_skip=True):
filters = filters_in * expand_ratio
#-------------------------------------------------#
# 利用Inverted residuals
# part1 利用1x1卷积进行通道数上升
#-------------------------------------------------#
if expand_ratio != 1:
x = layers.Conv2D(filters, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'expand_conv')(inputs)
x = layers.BatchNormalization(axis=3, name=name + 'expand_bn')(x)
x = layers.Activation(activation_fn, name=name + 'expand_activation')(x)
else:
x = inputs
#------------------------------------------------------#
# 如果步长为2x2的话,利用深度可分离卷积进行高宽压缩
# part2 利用3x3卷积对每一个channel进行卷积
#------------------------------------------------------#
if strides == 2:
x = layers.ZeroPadding2D(padding=correct_pad(x, kernel_size),
name=name + 'dwconv_pad')(x)
conv_pad = 'valid'
else:
conv_pad = 'same'
x = layers.DepthwiseConv2D(kernel_size,
strides=strides,
padding=conv_pad,
use_bias=False,
depthwise_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'dwconv')(x)
x = layers.BatchNormalization(axis=3, name=name + 'bn')(x)
x = layers.Activation(activation_fn, name=name + 'activation')(x)
#------------------------------------------------------#
# 完成深度可分离卷积后
# 对深度可分离卷积的结果施加注意力机制
#------------------------------------------------------#
if 0 < se_ratio <= 1:
filters_se = max(1, int(filters_in * se_ratio))
se = layers.GlobalAveragePooling2D(name=name + 'se_squeeze')(x)
se = layers.Reshape((1, 1, filters), name=name + 'se_reshape')(se)
#------------------------------------------------------#
# 通道先压缩后上升,最后利用sigmoid将值固定到0-1之间
#------------------------------------------------------#
se = layers.Conv2D(filters_se, 1,
padding='same',
activation=activation_fn,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'se_reduce')(se)
se = layers.Conv2D(filters, 1,
padding='same',
activation='sigmoid',
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'se_expand')(se)
x = layers.multiply([x, se], name=name + 'se_excite')
#------------------------------------------------------#
# part3 利用1x1卷积进行通道下降
#------------------------------------------------------#
x = layers.Conv2D(filters_out, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'project_conv')(x)
x = layers.BatchNormalization(axis=3, name=name + 'project_bn')(x)
#------------------------------------------------------#
# part4 如果满足残差条件,那么就增加残差边
#------------------------------------------------------#
if (id_skip is True and strides == 1 and filters_in == filters_out):
if drop_rate > 0:
x = layers.Dropout(drop_rate,
noise_shape=(None, 1, 1, 1),
name=name + 'drop')(x)
x = layers.add([x, inputs], name=name + 'add')
return x
EfficientNet的代码构建
1、模型代码的构建
EfficientNet的实现代码如下,该代码是EfficientNet在YoloV3上的应用,可以参考一下:
import math
from copy import deepcopy
import tensorflow as tf
from keras import backend, layers
#-------------------------------------------------#
# 一共七个大结构块,每个大结构块都有特定的参数
#-------------------------------------------------#
DEFAULT_BLOCKS_ARGS = [
{'kernel_size': 3, 'repeats': 1, 'filters_in': 32, 'filters_out': 16,
'expand_ratio': 1, 'id_skip': True, 'strides': 1, 'se_ratio': 0.25},
{'kernel_size': 3, 'repeats': 2, 'filters_in': 16, 'filters_out': 24,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 5, 'repeats': 2, 'filters_in': 24, 'filters_out': 40,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 3, 'repeats': 3, 'filters_in': 40, 'filters_out': 80,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 5, 'repeats': 3, 'filters_in': 80, 'filters_out': 112,
'expand_ratio': 6, 'id_skip': True, 'strides': 1, 'se_ratio': 0.25},
{'kernel_size': 5, 'repeats': 4, 'filters_in': 112, 'filters_out': 192,
'expand_ratio': 6, 'id_skip': True, 'strides': 2, 'se_ratio': 0.25},
{'kernel_size': 3, 'repeats': 1, 'filters_in': 192, 'filters_out': 320,
'expand_ratio': 6, 'id_skip': True, 'strides': 1, 'se_ratio': 0.25}
]
#-------------------------------------------------#
# Kernel的初始化器
#-------------------------------------------------#
CONV_KERNEL_INITIALIZER = {
'class_name': 'VarianceScaling',
'config': {
'scale': 2.0,
'mode': 'fan_out',
'distribution': 'normal'
}
}
#-------------------------------------------------#
# 用于计算卷积层的padding的大小
#-------------------------------------------------#
def correct_pad(inputs, kernel_size):
img_dim = 1
input_size = backend.int_shape(inputs)[img_dim:(img_dim + 2)]
if isinstance(kernel_size, int):
kernel_size = (kernel_size, kernel_size)
if input_size[0] is None:
adjust = (1, 1)
else:
adjust = (1 - input_size[0] % 2, 1 - input_size[1] % 2)
correct = (kernel_size[0] // 2, kernel_size[1] // 2)
return ((correct[0] - adjust[0], correct[0]),
(correct[1] - adjust[1], correct[1]))
#-------------------------------------------------#
# 该函数的目的是保证filter的大小可以被8整除
#-------------------------------------------------#
def round_filters(filters, divisor, width_coefficient):
filters *= width_coefficient
new_filters = max(divisor, int(filters + divisor / 2) // divisor * divisor)
if new_filters < 0.9 * filters:
new_filters += divisor
return int(new_filters)
#-------------------------------------------------#
# 计算模块的重复次数
#-------------------------------------------------#
def round_repeats(repeats, depth_coefficient):
return int(math.ceil(depth_coefficient * repeats))
#-------------------------------------------------#
# efficient_block
#-------------------------------------------------#
def block(inputs, activation_fn=tf.nn.swish, drop_rate=0., name='',
filters_in=32, filters_out=16, kernel_size=3, strides=1,
expand_ratio=1, se_ratio=0., id_skip=True):
filters = filters_in * expand_ratio
#-------------------------------------------------#
# 利用Inverted residuals
# part1 利用1x1卷积进行通道数上升
#-------------------------------------------------#
if expand_ratio != 1:
x = layers.Conv2D(filters, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'expand_conv')(inputs)
x = layers.BatchNormalization(axis=3, name=name + 'expand_bn')(x)
x = layers.Activation(activation_fn, name=name + 'expand_activation')(x)
else:
x = inputs
#------------------------------------------------------#
# 如果步长为2x2的话,利用深度可分离卷积进行高宽压缩
# part2 利用3x3卷积对每一个channel进行卷积
#------------------------------------------------------#
if strides == 2:
x = layers.ZeroPadding2D(padding=correct_pad(x, kernel_size),
name=name + 'dwconv_pad')(x)
conv_pad = 'valid'
else:
conv_pad = 'same'
x = layers.DepthwiseConv2D(kernel_size,
strides=strides,
padding=conv_pad,
use_bias=False,
depthwise_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'dwconv')(x)
x = layers.BatchNormalization(axis=3, name=name + 'bn')(x)
x = layers.Activation(activation_fn, name=name + 'activation')(x)
#------------------------------------------------------#
# 完成深度可分离卷积后
# 对深度可分离卷积的结果施加注意力机制
#------------------------------------------------------#
if 0 < se_ratio <= 1:
filters_se = max(1, int(filters_in * se_ratio))
se = layers.GlobalAveragePooling2D(name=name + 'se_squeeze')(x)
se = layers.Reshape((1, 1, filters), name=name + 'se_reshape')(se)
#------------------------------------------------------#
# 通道先压缩后上升,最后利用sigmoid将值固定到0-1之间
#------------------------------------------------------#
se = layers.Conv2D(filters_se, 1,
padding='same',
activation=activation_fn,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'se_reduce')(se)
se = layers.Conv2D(filters, 1,
padding='same',
activation='sigmoid',
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'se_expand')(se)
x = layers.multiply([x, se], name=name + 'se_excite')
#------------------------------------------------------#
# part3 利用1x1卷积进行通道下降
#------------------------------------------------------#
x = layers.Conv2D(filters_out, 1,
padding='same',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name=name + 'project_conv')(x)
x = layers.BatchNormalization(axis=3, name=name + 'project_bn')(x)
#------------------------------------------------------#
# part4 如果满足残差条件,那么就增加残差边
#------------------------------------------------------#
if (id_skip is True and strides == 1 and filters_in == filters_out):
if drop_rate > 0:
x = layers.Dropout(drop_rate,
noise_shape=(None, 1, 1, 1),
name=name + 'drop')(x)
x = layers.add([x, inputs], name=name + 'add')
return x
def EfficientNet(width_coefficient,
depth_coefficient,
drop_connect_rate=0.2,
depth_divisor=8,
activation_fn=tf.nn.swish,
blocks_args=DEFAULT_BLOCKS_ARGS,
inputs=None,
**kwargs):
img_input = inputs
#-------------------------------------------------#
# 创建stem部分
# 416,416,3 -> 208,208,32
#-------------------------------------------------#
x = img_input
x = layers.ZeroPadding2D(padding=correct_pad(x, 3),
name='stem_conv_pad')(x)
x = layers.Conv2D(round_filters(32, depth_divisor, width_coefficient), 3,
strides=2,
padding='valid',
use_bias=False,
kernel_initializer=CONV_KERNEL_INITIALIZER,
name='stem_conv')(x)
x = layers.BatchNormalization(axis=3, name='stem_bn')(x)
x = layers.Activation(activation_fn, name='stem_activation')(x)
#-------------------------------------------------#
# 进行一个深度的copy
#-------------------------------------------------#
blocks_args = deepcopy(blocks_args)
#-------------------------------------------------#
# 计算总的efficient_block的数量
#-------------------------------------------------#
b = 0
blocks = float(sum(args['repeats'] for args in blocks_args))
feats = []
filters_outs = []
#------------------------------------------------------------------------------#
# 对结构块参数进行循环、一共进行7个大的结构块。
# 每个大结构块下会重复小的efficient_block、每个大结构块的shape变化为:
# 208,208,32 -> 208,208,16 -> 104,104,24 -> 52,52,40
# -> 26,26,80 -> 26,26,112 -> 13,13,192 -> 13,13,320
# 输入为208,208,32,最终获得三个shape的有效特征层
# 104,104,24、26,26,112、13,13,320
#------------------------------------------------------------------------------#
for (i, args) in enumerate(blocks_args):
assert args['repeats'] > 0
args['filters_in'] = round_filters(args['filters_in'], depth_divisor, width_coefficient)
args['filters_out'] = round_filters(args['filters_out'], depth_divisor, width_coefficient)
for j in range(round_repeats(args.pop('repeats'), depth_coefficient)):
if j > 0:
args['strides'] = 1
args['filters_in'] = args['filters_out']
x = block(x, activation_fn, drop_connect_rate * b / blocks,
name='block{}{}_'.format(i + 1, chr(j + 97)), **args)
b += 1
feats.append(x)
if i == 2 or i == 4 or i == 6:
filters_outs.append(args['filters_out'])
return feats, filters_outs
def EfficientNetB0(inputs=None, **kwargs):
return EfficientNet(1.0, 1.0, inputs=inputs, **kwargs)
def EfficientNetB1(inputs=None, **kwargs):
return EfficientNet(1.0, 1.1, inputs=inputs, **kwargs)
def EfficientNetB2(inputs=None, **kwargs):
return EfficientNet(1.1, 1.2, inputs=inputs, **kwargs)
def EfficientNetB3(inputs=None, **kwargs):
return EfficientNet(1.2, 1.4, inputs=inputs, **kwargs)
def EfficientNetB4(inputs=None, **kwargs):
return EfficientNet(1.4, 1.8, inputs=inputs, **kwargs)
def EfficientNetB5(inputs=None, **kwargs):
return EfficientNet(1.6, 2.2, inputs=inputs, **kwargs)
def EfficientNetB6(inputs=None, **kwargs):
return EfficientNet(1.8, 2.6, inputs=inputs, **kwargs)
def EfficientNetB7(inputs=None, **kwargs):
return EfficientNet(2.0, 3.1, inputs=inputs, **kwargs)
2、Yolov3上的应用
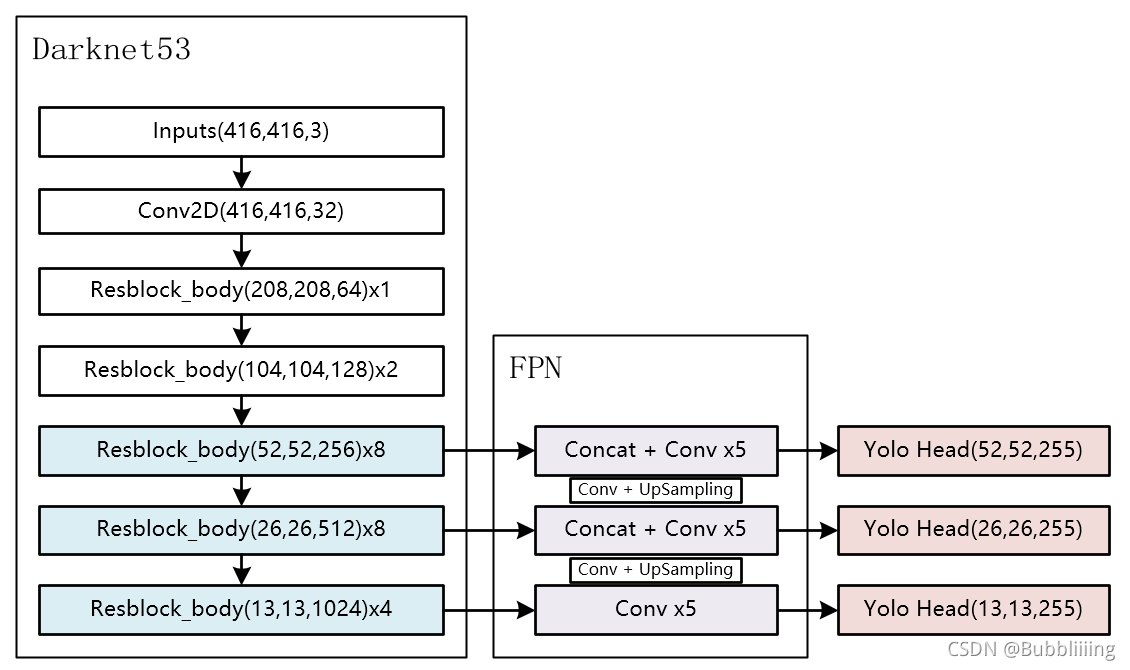
对于yolov3来讲,我们需要利用主干特征提取网络获得的三个有效特征进行加强特征金字塔的构建。
我们通过上述代码可以取出三个有效特征层,我们可以利用这三个有效特征层替换原来yolov3主干网络darknet53的有效特征层。
为了进一步减少参数量,我们减少了yolov3中用到的普通卷积的通道数。
最终EfficientNet-YoloV3的构建代码如下:
from functools import wraps
from keras.initializers import random_normal
from keras.layers import (BatchNormalization, Concatenate, Conv2D, Input,
Lambda, LeakyReLU, UpSampling2D)
from keras.models import Model
from keras.regularizers import l2
from utils.utils import compose
from nets.efficientnet import (EfficientNetB0, EfficientNetB1, EfficientNetB2,
EfficientNetB3, EfficientNetB4, EfficientNetB5,
EfficientNetB6, EfficientNetB7)
from nets.yolo_training import yolo_loss
Efficient = [EfficientNetB0,EfficientNetB1,EfficientNetB2,EfficientNetB3,EfficientNetB4,EfficientNetB5,EfficientNetB6,EfficientNetB7]
#------------------------------------------------------#
# 单次卷积DarknetConv2D
# 如果步长为2则自己设定padding方式。
# 测试中发现没有l2正则化效果更好,所以去掉了l2正则化
#------------------------------------------------------#
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_initializer' : random_normal(stddev=0.02), 'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides')==(2,2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
#---------------------------------------------------#
# 卷积块 -> 卷积 + 标准化 + 激活函数
# DarknetConv2D + BatchNormalization + LeakyReLU
#---------------------------------------------------#
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
#---------------------------------------------------#
# 特征层->最后的输出
#---------------------------------------------------#
def make_five_conv(x, num_filters):
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
x = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (1,1))(x)
return x
def make_yolo_head(x, num_filters, out_filters):
y = DarknetConv2D_BN_Leaky(num_filters*2, (3,3))(x)
y = DarknetConv2D(out_filters, (1,1))(y)
return y
#---------------------------------------------------#
# FPN网络的构建,并且获得预测结果
#---------------------------------------------------#
def yolo_body(input_shape, anchors_mask, num_classes, phi = 0):
inputs = Input(input_shape)
#---------------------------------------------------#
# 生成darknet53的主干模型
# 获得三个有效特征层,他们的shape分别是:
# C3 为 52,52,256
# C4 为 26,26,512
# C5 为 13,13,1024
#---------------------------------------------------#
feats, filters_outs = Efficient[phi](inputs = inputs)
feat1 = feats[2]
feat2 = feats[4]
feat3 = feats[6]
#---------------------------------------------------#
# 第一个特征层
# y1=(batch_size,13,13,3,85)
#---------------------------------------------------#
# 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512 -> 13,13,1024 -> 13,13,512
x = make_five_conv(feat3, int(filters_outs[2]))
P5 = make_yolo_head(x, int(filters_outs[2]), len(anchors_mask[0]) * (num_classes+5))
# 13,13,512 -> 13,13,256 -> 26,26,256
x = compose(DarknetConv2D_BN_Leaky(int(filters_outs[1]), (1,1)), UpSampling2D(2))(x)
# 26,26,256 + 26,26,512 -> 26,26,768
x = Concatenate()([x, feat2])
#---------------------------------------------------#
# 第二个特征层
# y2=(batch_size,26,26,3,85)
#---------------------------------------------------#
# 26,26,768 -> 26,26,256 -> 26,26,512 -> 26,26,256 -> 26,26,512 -> 26,26,256
x = make_five_conv(x, int(filters_outs[1]))
P4 = make_yolo_head(x, int(filters_outs[1]), len(anchors_mask[1]) * (num_classes+5))
# 26,26,256 -> 26,26,128 -> 52,52,128
x = compose(DarknetConv2D_BN_Leaky(int(filters_outs[0]), (1,1)), UpSampling2D(2))(x)
# 52,52,128 + 52,52,256 -> 52,52,384
x = Concatenate()([x, feat1])
#---------------------------------------------------#
# 第三个特征层
# y3=(batch_size,52,52,3,85)
#---------------------------------------------------#
# 52,52,384 -> 52,52,128 -> 52,52,256 -> 52,52,128 -> 52,52,256 -> 52,52,128
x = make_five_conv(x, int(filters_outs[0]))
P3 = make_yolo_head(x, int(filters_outs[0]), len(anchors_mask[2]) * (num_classes+5))
return Model(inputs, [P5, P4, P3])
以上就是Keras利用efficientnet系列模型搭建yolov3目标检测平台的详细内容,更多关于efficientnet搭建yolov3目标检测的资料请关注我们其它相关文章!
相关推荐
-
python神经网络Keras构建CNN网络训练
目录 Keras中构建CNN的重要函数 1.Conv2D 2.MaxPooling2D 3.Flatten 全部代码 利用Keras构建完普通BP神经网络后,还要会构建CNN Keras中构建CNN的重要函数 1.Conv2D Conv2D用于在CNN中构建卷积层,在使用它之前需要在库函数处import它. from keras.layers import Conv2D 在实际使用时,需要用到几个参数. Conv2D( nb_filter = 32, nb_row = 5, nb_col = 5
-
python神经网络使用Keras构建RNN训练
目录 Keras中构建RNN的重要函数 1.SimpleRNN 2.model.train_on_batch Keras中构建RNN的重要函数 1.SimpleRNN SimpleRNN用于在Keras中构建普通的简单RNN层,在使用前需要import. from keras.layers import SimpleRNN 在实际使用时,需要用到几个参数. model.add( SimpleRNN( batch_input_shape = (BATCH_SIZE,TIME_STEPS,INPUT
-
python神经网络使用Keras进行模型的保存与读取
目录 学习前言 Keras中保存与读取的重要函数 1.model.save 2.load_model 全部代码 学习前言 开始做项目的话,有些时候会用到别人训练好的模型,这个时候要学会load噢. Keras中保存与读取的重要函数 1.model.save model.save用于保存模型,在保存模型前,首先要利用pip install安装h5py的模块,这个模块在Keras的模型保存与读取中常常被使用,用于定义保存格式. pip install h5py 完成安装后,可以通过如下函数保存模型.
-
python神经网络学习使用Keras进行简单分类
目录 学习前言 Keras中分类的重要函数 1.np_utils.to_categorical 2.Activation 3.metrics=[‘accuracy’] 全部代码 学习前言 上一步讲了如何构建回归算法,这一次将怎么进行简单分类. Keras中分类的重要函数 1.np_utils.to_categorical np_utils.to_categorical用于将标签转化为形如(nb_samples, nb_classes)的二值序列. 假设num_classes = 10. 如将[1
-

Keras搭建分类网络平台VGG16 MobileNet ResNet50
目录 分类网络的常见形式 分类网络介绍 1.VGG16网络介绍 2.MobilenetV1网络介绍 3.ResNet50网络介绍 分类网络的训练 1.LOSS介绍 2.利用分类网络进行训练 才发现做了这么多的博客和视频,居然从来没有系统地做过分类网络,做一个科学的分类网络,对身体好. 源码下载 https://github.com/bubbliiiing/classification-keras 分类网络的常见形式 常见的分类网络都可以分为两部分,一部分是特征提取部分,另一部分是分类部分. 特征
-
python神经网络学习使用Keras进行回归运算
目录 学习前言 什么是Keras Keras中基础的重要函数 1.Sequential 2.Dense 3.model.compile 全部代码 学习前言 看了好多Github,用于保存模型的库都是Keras,我觉得还是好好学习一下的好 什么是Keras Keras是一个由Python编写的开源人工神经网络库,可以作Tensorflow.Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计.调试.评估.应用和可视化. Keras相当于比Tensorflow和The
-
Keras搭建Efficientdet目标检测平台的实现思路
学习前言 一起来看看Efficientdet的keras实现吧,顺便训练一下自己的数据. 什么是Efficientdet目标检测算法 最近,谷歌大脑 Mingxing Tan.Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet,结合 EfficientNet(同样来自该团队)和新提出的 BiFPN,实现新的 SOTA 结果. 源码下载 https://github.com/bubbliiiing/efficientdet-keras 喜欢的可以点个star噢
-
Keras神经网络efficientnet模型搭建yolov3目标检测平台
目录 什么是EfficientNet模型 源码下载 EfficientNet模型的实现思路 1.EfficientNet模型的特点 2.EfficientNet网络的结构 EfficientNet的代码构建 1.模型代码的构建 2.Yolov3上的应用 什么是EfficientNet模型 2019年,谷歌新出EfficientNet,在其它网络的基础上,大幅度的缩小了参数的同时提高了预测准确度,简直太强了,我这样的强者也要跟着做下去 EfficientNet,网络如其名,这个网络非常的有效率,怎
-
python神经网络Keras搭建RFBnet目标检测平台
目录 什么是RFBnet目标检测算法 RFBnet实现思路 一.预测部分 1.主干网络介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.真实框的处理 2.利用处理完的真实框与对应图片的预测结果计算loss 训练自己的RFB模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 什么是RFBnet目标检测算法 RFBnet是SSD的一种加强版,主要是利用了膨胀卷积这一方法增大了感受野,相比于普通的ssd,RFBnet也是一种加强吧 RF
-
Keras搭建M2Det目标检测平台示例
目录 什么是M2det目标检测算法 M2det实现思路 一.预测部分 1.主干网络介绍 2.FFM1特征初步融合 3.细化U型模块TUM 4.FFM2特征加强融合 5.注意力机制模块SFAM 6.从特征获取预测结果 7.预测结果的解码 8.在原图上进行绘制 二.训练部分 1.真实框的处理 2.利用处理完的真实框与对应图片的预测结果计算loss 训练自己的M2Det模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 什么是M2det目标检测算法 一起来看看M2det的ke
-
Python Flask搭建yolov3目标检测系统详解流程
[人工智能项目]Python Flask搭建yolov3目标检测系统 后端代码 from flask import Flask, request, jsonify from PIL import Image import numpy as np import base64 import io import os from backend.tf_inference import load_model, inference os.environ['CUDA_VISIBLE_DEVICES'] = '
-
Pytorch搭建YoloV4目标检测平台实现源码
目录 什么是YOLOV4 YOLOV4结构解析 1.主干特征提取网络Backbone 2.特征金字塔 3.YoloHead利用获得到的特征进行预测 4.预测结果的解码 5.在原图上进行绘制 YOLOV4的训练 1.YOLOV4的改进训练技巧 a).Mosaic数据增强 b).Label Smoothing平滑 c).CIOU d).学习率余弦退火衰减 2.loss组成 a).计算loss所需参数 b).y_pre是什么 c).y_true是什么. d).loss的计算过程 训练自己的YoloV4
-
Pytorch搭建yolo3目标检测平台实现源码
目录 yolo3实现思路 一.预测部分 1.主题网络darknet53介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.计算loss所需参数 2.pred是什么 3.target是什么. 4.loss的计算过程 训练自己的YoloV3模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 yolo3实现思路 一起来看看yolo3的Pytorch实现吧,顺便训练一下自己的数据. 源码下载 一.预测部分 1.主题网络darknet53介绍
-
Pytorch搭建YoloV5目标检测平台实现过程
目录 学习前言 源码下载 YoloV5改进的部分(不完全) YoloV5实现思路 一.整体结构解析 二.网络结构解析 2.构建FPN特征金字塔进行加强特征提取 三.预测结果的解码 1.获得预测框与得分 2.得分筛选与非极大抑制 四.训练部分 1.计算loss所需内容 2.正样本的匹配过程 a.匹配先验框 b.匹配特征点 3.计算Loss 训练自己的YoloV5模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 学习前言 这个很久都没有学,最终还是决定看看,复现的是Yol
-
opencv调用yolov3模型深度学习目标检测实例详解
目录 引言 建立相关目录 代码详解 附源代码 引言 opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解 对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn. 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码 建立相关目录 在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下
-
Keras目标检测mtcnn facenet搭建人脸识别平台
目录 什么是mtcnn和facenet 1.mtcnn 2.facenet 实现流程 一.数据库的初始化 二.实时图片的处理 1.人脸的截取与对齐 2.利用facenet对矫正后的人脸进行编码 3.将实时图片中的人脸特征与数据库中的进行比对 4.实时处理图片整体代码 全部代码: 什么是mtcnn和facenet 1.mtcnn MTCNN,英文全称是Multi-task convolutional neural network,中文全称是多任务卷积神经网络,该神经网络将人脸区域检测与人脸关键点检