Python3.7 + Yolo3实现识别语音播报功能
一、利用Python调用系统win10的文字转语音
首先下载需要用到的库:pip install pyttsx3 -i https://mirrors.aliyun.com/pypi/simple/
接下来直接上代码:
import win32com.client as win
# SpVoice类是支持语音合成(TTS)的核心类。通过SpVoice对象调用TTS引擎,从而实现朗读功能
speak = win.Dispatch("SAPI.SpVoice")
# 完成将文本信息转换为语音并按照指定的参数进行朗读。
# 该方法有Text和Flags两个参数,分别指定要朗读的文本和朗读方式(同步或异步等)。
speak.Speak("come on")
speak.Speak("你好")
最后运行代码,就会听到系统传出来的声音,读出了 come on 和 你好。
二、开始使用Yolo识别,利用语音播报返回出来
开始之前我们先得解析出来Yolo3的代码,从而获取到被识别出来的物体标签。
首先我们找到一个coco_classes.txt,发现里面有很多的英文单词,这些就是准备识别匹配的标签了。
然后我们在找到yolo.py,发现的我们的coco_classes.txt被传入进来了
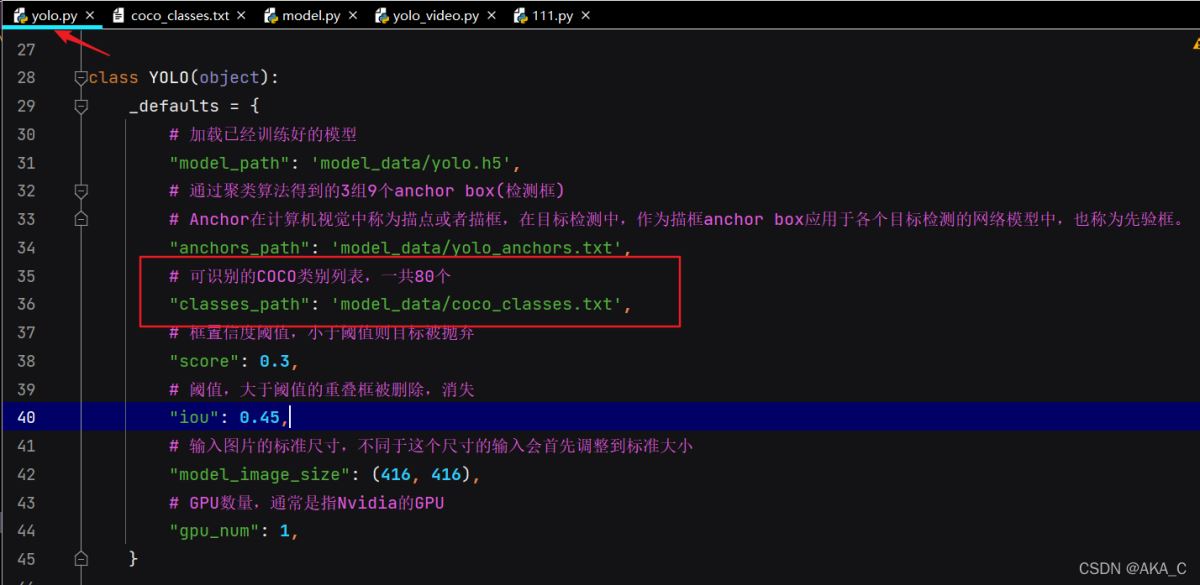
关键的来了,我们通过Ctrl + F 搜索一下classes_path这个Key,发现这几行代码

这里就是读取了存放标签的那个文本,进行了处理,并且返回了名字。
最后找到这一行代码,此处代码就是一开始进行识别的时候,我们的控制台打印出来的代码。

运行代码的时候发现,打印的这个label,就是识别出的物体的标签了。
这个时候我们就可以将我们的语音播报的代码添加进行,把label传入进去,就会发现识别出来的物体就会通过语音返回。

Time~
到此这篇关于Python3.7 + Yolo3识别 语音播报的文章就介绍到这了,更多相关Python识别语音内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于Python创建语音识别控制系统
下面附上参考文章,这篇文章是通过识别出来的文字来打开浏览器中的默认网站.python通过调用百度api实现语音识别 题目很简单,利用语音识别识别说出来的文字,根据文字的内容来控制图形移动,例如说向上,识别出文字后,画布上的图形就会向上移动.本文使用的是百度识别API(因为免费),自己做的流程图: 不多说,直接开始程序设计,首先登录百度云,创建应用 注意这里的API Key和Secret Key,要用自己的才能生效 百度语音识别有对应的文档,具体调用方法说的很清晰,如果想学习一下可以查看REST
-
python录音并调用百度语音识别接口的示例
#!/usr/bin/env python import requests import json import base64 import pyaudio import wave import os import psutil #首先配置必要的信息 def bat(voice_path): baidu_server = 'https://aip.baidubce.com/oauth/2.0/token?' grant_type = 'client_credentials' client_id
-
Python调用百度api实现语音识别详解
最近在学习python,做一些python练习题 github上几年前的练习题 有一题是这样的: 使用 Python 实现:对着电脑吼一声,自动打开浏览器中的默认网站. 例如,对着笔记本电脑吼一声"百度",浏览器自动打开百度首页. 然后开始search相应的功能需要的模块(windows10),理一下思路: 本地录音 上传录音,获得返回结果 组一个map,根据结果打开相应的网页 所需模块: PyAudio:录音接口 wave:打开录音文件并设置音频参数 requests:GET/POS
-
Python迅速掌握语音识别之知识储备篇
目录 概述 RNN 计算 RNN 存在的问题 LSTM GRU Seq2seq Attention 模型 Teacher Forcing 机制 概述 从今天开始我们将开启一个新的深度学习章节, 为大家来讲述一下深度学习在语音识别 (Speech Recognition) 的应用. 语音识别技术可以将语音转换为计算机可读的输入, 让计算机明白我们要表达什么, 实现真正的人机交互. 希望通过本专栏的学习, 大家能够对语音识别这一领域有一个基本的了解. RNN RNN (Recurrent Neura
-
Python结合百度语音识别实现实时翻译软件的实现
一.所需库安装 pip install PyAudio pip install SpeechRecognition pip install baidu-aip pip install Wave pip install Wheel pip install Pyinstaller 二.百度官网申请服务 三.源代码分享 import pyaudio import wave from aip import AipSpeech import time # 用Pyaudio库录制音频 # out_file:
-
python语音识别的转换方法
使用pyttsx的python包,你可以将文本转换为语音. 安装命令 pip install pyttsx3 -i https://pypi.tuna.tsinghua.edu.cn/simple 运行一个简单的语音 '大家好'. import pyttsx3 as pyttsx engine = pyttsx.init() #初始化 engine.say('大家好') engine.runAndWait() 另一种文本转语音方法. from win32com.client import Dis
-
Python3.7 + Yolo3实现识别语音播报功能
一.利用Python调用系统win10的文字转语音 首先下载需要用到的库:pip install pyttsx3 -i https://mirrors.aliyun.com/pypi/simple/ 接下来直接上代码: import win32com.client as win # SpVoice类是支持语音合成(TTS)的核心类.通过SpVoice对象调用TTS引擎,从而实现朗读功能 speak = win.Dispatch("SAPI.SpVoice") # 完成将文本信息转换为语
-
C#实现语音播报功能
本文实例为大家分享了C#实现语音播报功能的具体代码,供大家参考,具体内容如下 环境: window10vs2019 16.5.5.netframework4.5 一.关于语音播报 语音播报的功能属于操作系统自带的.win7和win10都自带,部分win7阉割版系统没有这项功能会导致运行报错: 检索 COM 类工厂中 CLSID 为 {D9F6EE60-58C9-458B-88E1-2F908FD7F87C} 的组件失败,原因是出现以下错误: 80040154 没有注册类 (异常来自 HRESUL
-
vue中添加语音播报功能的实现
1:首先把我们的静态资源文件加入到前端工程项目当中 我这里mp3文件就是要播报的语言文件 2: 页面中加入标签 <!-- src 后面的链接是我保存在static文件下的一段报警声 --> <audio v-show="false" id="audioSuccessIn" src="/static/successIn.mp3"/> <audio v-show="false" id="au
-
java文字转语音播报功能的实现方法
前言 本文主要给大家分享了关于java文字转语音播报的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 方法如下 一.pom.xml引入jar包依赖 <!-- https://mvnrepository.com/artifact/com.jacob/jacob 文字转语音 --> <dependency> <groupId>com.hynnet</groupId> <artifactId>jacob</artifac
-
详解Android 语音播报实现方案(无SDK)
本文介绍了详解Android 语音播报实现方案(无SDK),分享给大家,具体如下: 功能描述 类似支付宝收款时候的语音播报功能:当别人扫描你的收款码,你收到钱之后,就会听到"支付宝到账12.55元"的语音播报. 要解决的问题 1.播放单个语音文件 2.播放完单个语音文件之后立即播放下一条,这样才能连续 3.当多个完整的语音序列都需要播报时的处理(比如支付宝短时间内收到多条收款推送) 实现思路 1.播放单个文件选择MediaPlayer 首先创建一个MediaPlayer实例 Media
-
Android编程实现短信收发及语音播报提示功能示例
本文实例讲述了Android编程实现短信收发及语音播报提示功能.分享给大家供大家参考,具体如下: 发送短信功能界面 /** * 发送短信Demo * * @description: * @author ldm * @date 2016-4-22 上午9:07:53 */ public class SmsActivity extends Activity implements OnClickListener { public static final String SMS_RECIPIENT_EX
-
Python3调用百度AI识别图片中的文字功能示例【测试可用】
本文实例讲述了Python3调用百度AI识别图片中的文字功能.分享给大家供大家参考,具体如下: 首先pip install命令安装baidu-aip模块,如下图所示(这里使用pip3 install baidu-aip命令): 编辑Python代码时注意,需要首先引入AipOcr和re两个模块,即: from aip import AipOcr import re 示例代码如下: from aip import AipOcr import re APP_ID='***' API_KEY='***
-
iOS开发微信收款到账语音提醒功能思路详解
一.背景 为了解决小商户老板们在频繁交易中不方便核对.确认到账的痛点,产品MM提出了新版本需要支持收款到账语音提醒功能.这篇文章总结了开发过程中遇到的坑和一些小技巧. 二.技术方案 后台唤醒App 收款到账语音提醒需要收款方在收到款后,播放一段TTS合成语音播报金额,微信在前台时可以通过模板消息将需要播报的金额带下来,再请求TTS数据并播放,但是app在挂起或者被kill掉的情况下要如何请求语音数据并播放呢? iOS提供了两种方式唤醒处于挂起或已经被kill掉的app.分别是Silent Not
-
Android 基于百度语音的语音交互功能(推荐)
项目里面用到了语音唤醒功能,前面一直在用讯飞的语音识别,本来打算也是直接用讯飞的语音唤醒,但是讯飞的语音唤醒要收费,试用版只有35天有效期.只好改用百度语音,百度语音所有功能免费,功能也比较简单实用,包括语音识别,语音合成和语音唤醒,正好可以组成一套完整的语音交互功能. 效果图: 首先是语音唤醒功能,说出关键词即可叫语音识别,唤醒成功会有语音提示,这里采用了百度语音的合成功能.然后百度语音识别会根据wifi情况自动切换在线或者离线识别,但是离线识别只能识别已经导入的关键词,而且离线第一次识别需要
-
iOS自带文本转语音技术(TTS)的实现即语音播报的实践
文本转语音技术, 也叫TTS, 是Text To Speech的缩写. iOS如果想做有声书等功能的时候, 会用到这门技术. 一,使用iOS自带TTS需要注意的几点: 1.iOS7之后才有该功能 2.需要 AVFoundation 库 3.AVSpeechSynthesizer: 语音合成器, 可以假想成一个可以说话的人, 是最主要的接口 4.AVSpeechSynthesisVoice: 可以假想成人的声音 5.AVSpeechUtterance: 可以假想成要说的一段话 二,代码示例, 播放