C++ 实现高性能HTTP客户端
目录
- 一、什么是Http Client
- 二、请求的过程
- 1. 创建Http任务
- 2. 填写header并发出
- 3. 处理返回结果
- 三、高性能的基本保证
- 1. 异步调度模式
- 2. 连接复用
- 3. 解锁其他功能
一、什么是Http Client
Http协议,是全互联网共同的语言,而Http Client,可以说是我们需要从互联网世界获取数据的最基本方法,它本质上是一个URL到一个网页的转换过程。而有了基本的Http客户端功能,再搭配上我们想要的规则和策略,上至内容检索下至数据分析都可以实现了。
继上一次介绍用Workflow可以10行C++代码实现高性能HTTP服务,今天继续给大家用C++实现一个高性能的Http客户端也同样很简单!
// [http_client.cc]
#include "stdio.h"
#include "workflow/HttpMessage.h"
#include "workflow/WFTaskFactory.h"
int main (int argc, char *argv[])
{
const char *url = "https://github.com/sogou/workflow";
WFHttpTask *task = WFTaskFactory::create_http_task (url, 2, 3,
[](WFHttpTask * task) {
fprintf(stderr, "%s %s %s\r\n",
task->get_resp()->get_http_version(),
task->get_resp()->get_status_code(),
task->get_resp()->get_reason_phrase());
});
task->start();
getchar(); // press "Enter" to end.
return 0;
}
只要安装好了Workflow,以上代码即可以通过以下命令编译出一个简单的http_client:
g++ -o http_client http_client.cc --std=c++11 -lworkflow -lssl -lcrypto -lpthread
根据Http协议,我们执行这个可执行程序 ./http_client,就会得到以下内容:
HTTP/1.1 200 OK
同理,我们还可以通过其他api来获得返回的其他Http header和Http body,一切内容都在这个 WFHttpTask 中。而因为Workflow是个异步调度框架,因此这个任务发出之后,不会阻塞当前线程,外加内部自带的连接复用,从根本上保证了我们的Http Client的高性能。
接下来给大家详细讲解一下原理~
二、请求的过程
1. 创建Http任务
上述demo可以看到,请求是通过发起一个Workflow的Http异步任务来实现的,创建任务的接口如下:
WFHttpTask *create_http_task(const std::string& url,
int redirect_max, int retry_max,
http_callback_t callback);
第一个参数就是我们要请求的URL。对应的,在一开始的示例中,我们的重定向次数redirect_max是2次,而重试次数retry_max是3次。第四个参数是一个回调函数,示例中我们用了一个lambda,由于Workflow的任务都是异步的,因此我们处理结果这件事情是被动通知我们的,结果回来就会调起这个回调函数,格式如下:
using http_callback_t = std::function<void (WFHttpTask *)>;
2. 填写header并发出
我们的网络交互无非是请求-回复,对应到Http Client上,在我们创建好了task之后,我们有一些时机是处理请求的,在Http协议里,就是在header里填好协议相关的事情,比如我们可以通过Connection来指定希望得到建立Http的长连接,以节省下次建立连接的耗时,那么我们可以把Connection设置为Keep-Alive。示例如下:
protocol::HttpRequest *req = task->get_req();
req->add_header_pair("Connection", "Keep-Alive");
task->start();
最后我们会把设置好请求的任务,通过 task->start(); 发出。最开始的 http_client.cc 示例中,有一个 getchar(); 语句,是因为我们的异步任务发出后是非阻塞的,当前线程不暂时停住就会退出,而我们希望等到回调函数回来,因此我们可以用多种暂停的方式。
3. 处理返回结果
一个返回结果,根据Http协议,会包含三部分:消息行、消息头header、消息正文body。如果我们想要获取body,可以这样:
const void *body; size_t body_len; task->get_resp()->get_parsed_body(&body, &body_len);
三、高性能的基本保证
我们使用C++来写Http Client,最香的就是可以利用其高性能。Workflow对高并发是如何保证的呢?其实就两点:
纯异步;
连接复用;
前者是对线程资源的重复利用、后者是对连接资源的重复利用,这些框架层级都为用户管理好了,充分减少开发者的心智负担。
1. 异步调度模式
同步和异步的模式直接决定了我们的Http Client可以有多大的并发度。为什么呢?通过下图可以先看看同步框架发起三个Http任务,线程模型是怎样的:

网络延迟往往非常大,如果我们在同步等待任务回来的话,线程就会一直被占用。这时候我们需要看看异步框架是如何实现的:

如图所示,只要任务发出之后,线程即可做其他事情,我们传入了一个回调函数做异步通知,因此等任务的网络回复收完之后,再让线程执行这个回调函数即可拿到Http请求的结果,期间多个任务并发出去的时候,线程是可以复用的,轻松达到几十万的QPS并发度。
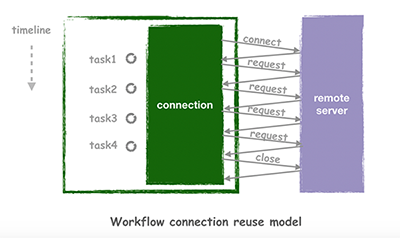
2. 连接复用
我们刚才有提到,只要我们建立了长连接,即可提高效率。为什么呢?因为框架对连接有复用。我们先来看看如果一个请求就建立一个连接,会是什么样的情况:

很显然,占用大量的连接是对系统资源的浪费,而且每次都要做connect以及close是非常耗时的,除了TCP常见的握手以外,许多应用层协议建立连接的过程也会相对复杂。但使用Workflow就不会有这样的烦恼,Workflow会在任务发出的时候自动查找当前可以复用的连接,如果没有才会自动创建,完全不需要开发者关心连接如何复用的细节:
3. 解锁其他功能
当然,除了以上的高性能以外,一个高性能的Http Client往往还有许多其他的需求,这里可以结合实际情况与大家分享:
- 1.结合workflow的串并联任务流,实现超大规模并行抓取;
- 2.按顺序或者按指定速度请求某个站点的内容,避免请求过猛被封禁;
- 3.Http Client遇到redirect可以自动帮我做跳转,一步到位请求到最终结果;
- 4.希望通过proxy代理访问
HTTP与HTTPS资源;
以上这些需求,要求框架对于Http任务的编排有超高的灵活性,以及对实际需求(比如redirect、ssl代理等功能)有非常接地气的支持,这些Workflow都已经实现。
项目地址
https://github.com/sogou/workflow
到此这篇关于C++ 实现高性能HTTP客户端的文章就介绍到这了,更多相关C++ 实现HTTP客户端内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C++ seekg函数用法案例详解
C++ seekg函数用法详解 很多时候用户可能会这样操作,打开一个文件,处理其中的所有数据,然后将文件倒回到开头,再次对它进行处理,但是这可能有点不同.例如,用户可能会要求程序在数据库中搜索某种类型的所有记录,当这些记录被找到时,用户又可能希望在数据库中搜索其他类型的所有记录. 文件流类提供了许多不同的成员函数,可以用来在文件中移动.其中的一个方法如下: seekg(offset, place); 这个输入流类的成员函数的名字 seekg 由两部分组成.首先是 seek(寻找)到文件中的某个地
-
C++11新特性之变长参数模板详解
目录 C++11 变长参数模板 变长函数参数包 如何解参数包 sizeof()获得函数参数个数 递归模板函数 变参模板展开 结论 C++11 变长参数模板 在C++11之前,无论是类模板 还是函数模板,都只能按其指定的样子,接受一组固定数量的模板参数: 这已经大大提升了代码的复用! 在C++11之后,加入了新的表示方 法,允许任意个数.任意类别的模板参数,同时也不需要在定义时将参数的个数固定.更加像"黑魔法"了. template<typename... Ts> class
-
C++ LARGE_INTEGER解析与使用案例详解
这里解释前面碰到的LARGE_INTEGER结构.与可能的误解不同,64位数据并非要在64位操作系统下才能使用.在VC中,64位数据的类型为__int64.定义写法如下: __int64 file_offset 上面之所以定义的变量名为file_offset,是因为文件中的偏移量是一种常见的要使用64位数据的情况.同时,文件的大小也是如此(回忆上一小节中定义的文件大小).32位数据无符号整型只能表示到4GB.而众所周知,现在超过4GB的文件绝对不罕见了.但是实际上__int64这
-
C++关于类结构体大小和构造顺序,析构顺序的测试详解
目录 总结 #include <iostream> using namespace std; /** 1. c++的类中成员若不加修饰符的话,默认是private 2. 调用构造函数时,先递归调用最顶级的父类构造函数,再依次到子类的构造函数. 3. 调用析构函数时相反,先调用最底层的子类析构函数,再依次到父类的构造函数. 4. 空类的sizeof(A)大小为1,多个空类继承后的子类大小也是1 */ class A{ public: A() { cout<<"A const
-

C++实现神经网络框架SimpleNN的详细过程
目录 Features Dependencies Platform To Do Usage SimpleNN is a simple neural network framework written in C++.It can help to learn how neural networks work. 源码地址:https://github.com/Kindn/SimpleNN Features Construct neural networks. Configure optimizer a
-
C++ 实现高性能HTTP客户端
目录 一.什么是Http Client 二.请求的过程 1. 创建Http任务 2. 填写header并发出 3. 处理返回结果 三.高性能的基本保证 1. 异步调度模式 2. 连接复用 3. 解锁其他功能 一.什么是Http Client Http协议,是全互联网共同的语言,而Http Client,可以说是我们需要从互联网世界获取数据的最基本方法,它本质上是一个URL到一个网页的转换过程.而有了基本的Http客户端功能,再搭配上我们想要的规则和策略,上至内容检索下至数据分析都可以实现了. 继
-
使用Go HTTP客户端打造高性能服务
目录 问题一:默认的 HTTP Client 问题二:默认的 Http Transport 总结 HTTP(超文本传输协议)是一种用于客户端和服务器之间传输数据的通信协议.如果想要访问服务器资源,HTTP 请求是必不可少的.Go 语言里,net/http 包附带了默认配置,我们可以适当调整便可以获得高性能. 大多数语言都有提供各自的 HTTP 客户端,文章接下来部分我们将动手实践如何使用 Go 语言发起 HTTP 请求,并讨论其中有可能遇到的问题. 在做 Go 项目时,我就意识到 HTTP 客户
-
高性能WEB开发 nginx HTTP服务器篇
第一篇:HTTP服务器 因tomcat处理静态资源的速度比较慢,所以首先想到的就是把所有静态资源(JS,CSS,image,swf) 提到单独的服务器,用更加快速的HTTP服务器,这里选择了nginx了,nginx相比apache,更加轻量级, 配置更加简单,而且nginx不仅仅是高性能的HTTP服务器,还是高性能的反向代理服务器. 目前很多大型网站都使用了nginx,新浪.网易.QQ等都使用了nginx,说明nginx的稳定性和性能还是非常不错的. 1. nginx 安装(linux) htt
-
实例讲解分布式缓存软件Memcached的Java客户端使用
Memcached介绍 下面就来介绍一下Memcached. 1.什么是Memcached Memcached是一个开源的高性能,分布式的内存对象缓存系统,通过键值队的形式来对数据进行存取,Memcached是简单而强大,它的简单设计促进快速部署,易于开发,解决了大数据缓存面临的许多问题. 官方网址是:http://memcached.org/,目前已经有很多知名的互联网应用使用到了Memcached,比如Wikipedia.Flickr.Youtube.Wordpress等等. 2.下载Win
-
基于Oracle的高性能动态SQL程序开发
正在看的ORACLE教程是:基于Oracle的高性能动态SQL程序开发. 摘要:对动态SQL的程序开发进行了总结,并结合笔者实际开发经验给出若干开发技巧. 关键词:动态SQL,PL/SQL,高性能 1. 静态SQLSQL与动态SQL Oracle编译PL/SQL程序块分为两个种:其一为前期联编(early binding),即SQL语句在程序编译期间就已经确定,大多数的编译情况属于这种类型:另外一种是后期联编(late binding),即SQL语句只有在运行阶段才能建立,例如当查询条件为用户输
-
前端程序员必须知道的高性能Javascript知识
想必大家都知道,JavaScrip是全栈开发语言,浏览器,手机,服务器端都可以看到JS的身影. 本文会分享一些高效的JavaScript的最佳实践,提高大家对JS的底层和实现原理的理解. 数据存储 计算机学科中有一个经典问题是通过改变数据存储的位置来获得最佳的读写性能,在JavaScript中,数据存储的位置会对代码性能产生重大影响. – 能使用{}创建对象就不要使用new Object,能使用[]创建数组就不要使用new Array.JS中字面量的访问速度要高于对象. – 变量在作用域链中的位
-
你不知道的高性能JAVASCRIPT
本文会分享一些高效的JavaScript的最佳实践,提高大家对JS的底层和实现原理的理解. 数据存储 计算机学科中有一个经典问题是通过改变数据存储的位置来获得最佳的读写性能,在JavaScript中,数据存储的位置会对代码性能产生重大影响. – 能使用{}创建对象就不要使用new Object,能使用[]创建数组就不要使用new Array.JS中字面量的访问速度要高于对象. – 变量在作用域链中的位置越深,访问所需实践越长.对于这种变量,可以通过缓存使用局部变量保存起来,减少对作用域链访问次数
-
编写高性能JavaScript(译)
译者按:本人第一次翻译外文,言语难免有些晦涩,但尽量表达了作者的原意,未经过多的润色,欢迎批评指正.另本文篇幅较长.信息量大,可能难以消化,欢迎留言探讨细节问题.本文主要关注V8的性能优化,部分内容并不适用于所有JS引擎.最后,转载请注明出处: ) ========================译文分割线=========================== 很多JavaScript引擎,如Google的V8引擎(被Chrome和Node所用),是专门为需要快速执行的大型JavaScript应
-
详解Spring MVC的异步模式(高性能的关键)
什么是异步模式 要知道什么是异步模式,就先要知道什么是同步模式,先看最典型的同步模式: 浏览器发起请求,Web服务器开一个线程处理,处理完把处理结果返回浏览器.好像没什么好说的了,绝大多数Web服务器都如此般处理.现在想想如果处理的过程中需要调用后端的一个业务逻辑服务器,会是怎样呢? 调就调吧,上图所示,请求处理线程会在Call了之后等待Return,自身处于阻塞状态.这也是绝大多数Web服务器的做法,一般来说这样做也够了,为啥?一来"长时间处理服务"调用通常不多,二来请求数其实也不多
-
java fastdfs客户端使用实例代码
本文研究的主要是java fastdfs客户端使用实例的相关内容,具体实现如下. 什么是FastDFS? FastDFS是用c语言编写的一款开源的分布式文件系统.FastDFS为互联网量身定制,充分考虑了冗余备份.负载均衡.线性扩容等机制,并注重高可用.高性能等指标,使用FastDFS很容易搭建一套高性能的文件服务器集群提供文件上传.下载等服务. FastDFS架构 FastDFS架构包括 Tracker server和Storage server.客户端请求Tracker server进行文件