python open函数中newline参数实例详解
目录
- 问题的由来
- 具体实例
- 总结
问题的由来
我在读pythoncsv模块文档 看到了这样一句话
如果 csvfile 是文件对象,则打开它时应使用 newline=‘’。
其备注:如果没有指定 newline=‘’,则嵌入引号中的换行符将无法正确解析,并且在写入时,使用 \r\n 换行的平台会有多余的 \r 写入。由于 csv 模块会执行自己的(通用)换行符处理,因此指定 newline=‘’ 应该总是安全的。
我就在思考open函数中的newline参数的作用,因为自己之前在使用open函数时从来没有设置过newline参数,仅从上面官方给的备注理解newline参数可以帮助处理换行符解析的问题
并且查阅得知不同操作系统换行符并不一致:
Unix 的行结束约定 ‘\n’、Windows 的约定 ‘\r\n’ 以及旧版 Macintosh 的约定 ‘\r’
打破了我原本观念以为的换行符就是\n
python官方文档对newline参数解释:
newline 控制 universal newlines 模式如何生效(它仅适用于文本模式)。它可以是 None,‘’,‘\n’,‘\r’ 和 ‘\r\n’。它的工作原理:
从流中读取输入时,如果 newline 为 None,则启用通用换行模式。输入中的行可以以 ‘\n’,‘\r’ 或 ‘\r\n’ 结尾,这些行被翻译成 ‘\n’ 在返回呼叫者之前。如果它是 ‘’,则启用通用换行模式,但行结尾将返回给调用者未翻译。如果它具有任何其他合法值,则输入行仅由给定字符串终止,并且行结尾将返回给未调用的调用者。
将输出写入流时,如果 newline 为 None,则写入的任何 ‘\n’ 字符都将转换为系统默认行分隔符 os.linesep。如果 newline 是 ‘’ 或 ‘\n’,则不进行翻译。如果 newline 是任何其他合法值,则写入的任何 ‘\n’ 字符将被转换为给定的字符串。
从这也就理解了为什么原本使用open()写的时候用\n就可以表示换行以及读文本文件时行尾会返回\n
- 写入的时候没有指定newline参数会将\n翻译成系统默认的行分割符(\r\n)
- 读的时候没有指定newline参数会将行分割符(\r\n)翻译为\n
回到上文,那为什么在读写csv文件时就要设置newline=''呢?
pythoncsv官方文档解释了这一问题(这也就引入了第二种方法解决换行的问题,我在后面会介绍到)
Dialect.lineterminator
放在 writer 产生的行的结尾,默认为 ‘\r\n’。
注解 reader 经过硬编码,会识别 ‘\r’ 或 ‘\n’ 作为行尾,并忽略 lineterminator。未来可能会更改这一行为。
用白话说就是writerow()方法在写入一行数据时在行尾都会跟一个默认换行符(\r\n)(即csv是将’一行数据\r\n’写入内存,此时这一行数据还在内存中,还没有写入文件)之后执行代码真正在向文件写入时根据不同newline参数进行翻译
而在向txt文件使用write()方法写入内容时是我们手动添加换行符\n(内存中的数据就是我们写入的内容,并不会隐式添加其他内容)之后执行代码真正在向文件写入时根据newline参数进行翻译,这就是二者的区别
具体流程:
newline=‘’
writer.writerow(‘line’) 实际是向内存中写入’line\r\n’ --》 执行代码,写入文件,根据newline=‘’,将不进行翻译 --》文件最终写入’line\r\n’
newline=None(默认)
f.write(‘line\n’) 直接将’line\n’写入内存 --》 执行代码,写入文件,根据newline=None,将\n翻译为\r\n --》文件最终写入’line\r\n’
具体实例
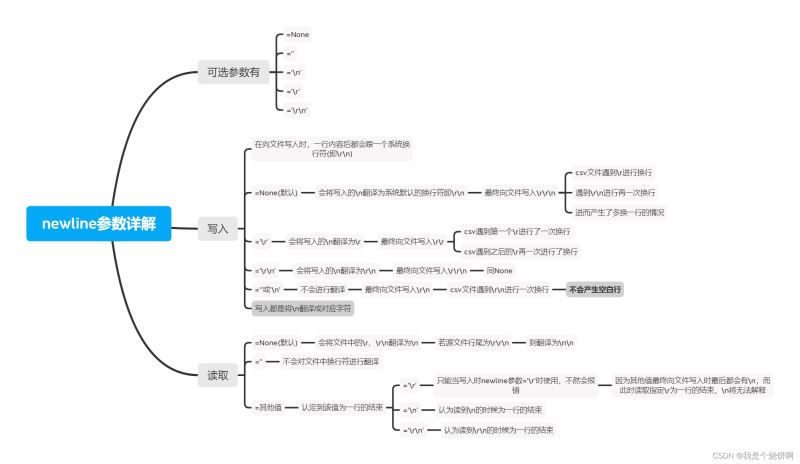
case1: w newline=‘’ r newline=‘’
import csv
with open("test.csv","w",encoding='utf-8',newline='') as csvfile:
writer=csv.writer(csvfile)
writer.writerow(["num","name","grade"])
writer.writerows([[1,'luke','96'],[2,'jack','85'],[3,'nick','84']])
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\n1,luke,96\r\n2,jack,85\r\n3,nick,84\r\n'
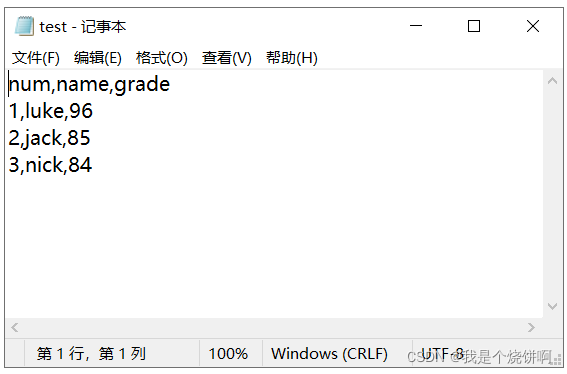
case2: w newline=‘\r’ r newline=‘’
import csv
with open("test.csv","w",encoding='utf-8',newline='\r') as csvfile:
writer=csv.writer(csvfile)
writer.writerow(["num","name","grade"])
writer.writerows([[1,'luke','96'],[2,'jack','85'],[3,'nick','84']])
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\r1,luke,96\r\r2,jack,85\r\r3,nick,84\r\r'
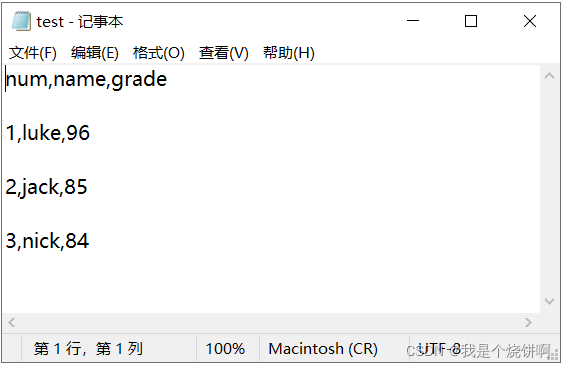
case3: w newline=‘\r\n’ r newline=‘’
import csv
with open("test.csv","w",encoding='utf-8',newline='\r\n') as csvfile:
writer=csv.writer(csvfile)
writer.writerow(["num","name","grade"])
writer.writerows([[1,'luke','96'],[2,'jack','85'],[3,'nick','84']])
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\r\n1,luke,96\r\r\n2,jack,85\r\r\n3,nick,84\r\r\n'
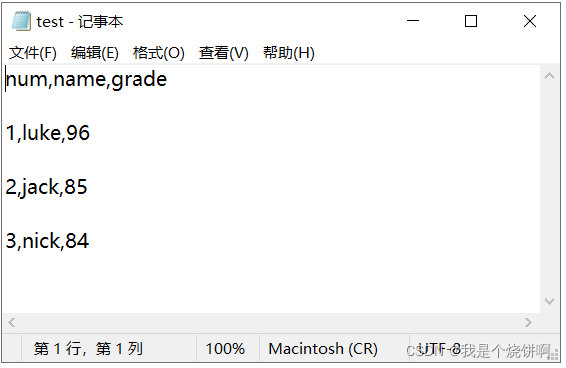
case4: w newline=None r newline=None
import csv
with open("test.csv","w",encoding='utf-8',newline=None) as csvfile:
writer=csv.writer(csvfile)
writer.writerow(["num","name","grade"])
writer.writerows([[1,'luke','96'],[2,'jack','85'],[3,'nick','84']])
with open("test.csv","r",encoding='utf-8',newline=None) as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\n\n1,luke,96\n\n2,jack,85\n\n3,nick,84\n\n'
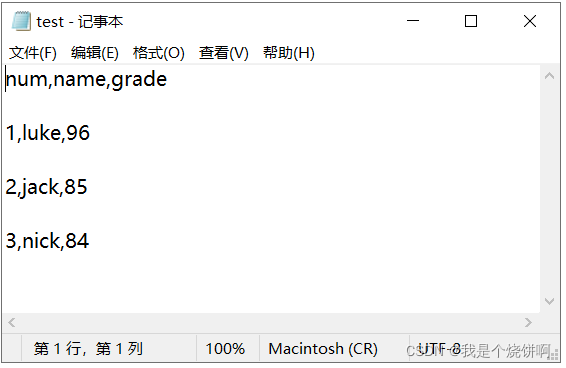
case5: 文件写入为\r\r\n 文件读取 newline=‘\r’
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\r\n1,luke,96\r\r\n2,jack,85\r\r\n3,nick,84\r\r\n'
import csv
with open("test.csv","r",encoding='utf-8',newline='\r') as csvfile:
content = csv.reader(csvfile)
for i in content:
print(i)
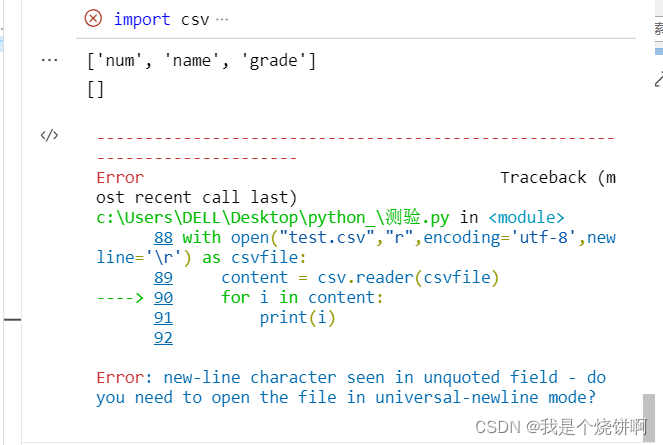
为什么会报错:
csv.reader是如何读取\r\r\n的:读取时遇到\r认为一行结束了,再一次遇到\r同样认为一行结束(因而返回了空串列表),遇到\n无法解释–》报错
case6:文件写入为\r\r\n 文件读取 newline=‘\n’
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\r\n1,luke,96\r\r\n2,jack,85\r\r\n3,nick,84\r\r\n'
import csv
with open("test.csv","r",encoding='utf-8',newline='\n') as csvfile:
content = csv.reader(csvfile)
for i in content:
print(i)

case7:文件写入为\r\r\n 文件读取newline=‘\r\n’
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\r\n1,luke,96\r\r\n2,jack,85\r\r\n3,nick,84\r\r\n'
import csv
with open("test.csv","r",encoding='utf-8',newline='\r\n') as csvfile:
content = csv.reader(csvfile)
for i in content:
print(i)
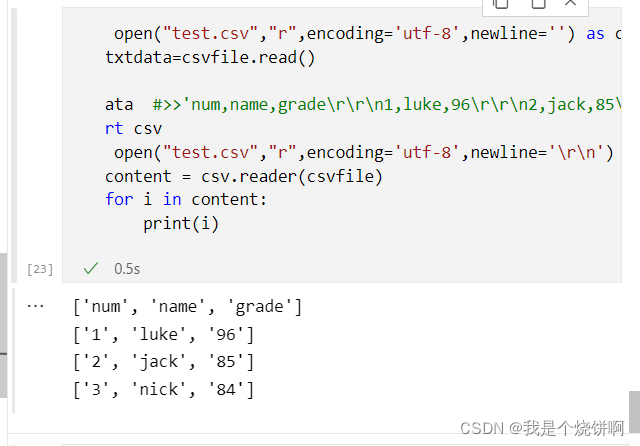
case8:文件写入为\r\r 文件读取 newline=‘\r’
with open("test.csv","r",encoding='utf-8',newline='') as csvfile:
txtdata=csvfile.read()
txtdata #>>'num,name,grade\r\r1,luke,96\r\r2,jack,85\r\r3,nick,84\r\r'
import csv
with open("test.csv","r",encoding='utf-8',newline='\r') as csvfile:
content = csv.reader(csvfile)
for i in content:
print(i)

第二种方法:通过设置csv.writer方法中的lineterminator参数
上面提到lineterminator参数控制writer写入每一行后跟的隐式结束符,默认为’\r\n’,因此我们需要要设置lineterminator=‘\n’,读取时也不需要设置newline参数即可获得想要的效果
import csv
with open("test.csv","w",encoding='utf-8') as csvfile:
writer=csv.writer(csvfile,lineterminator='\n')
writer.writerow(["num","name","grade"])
writer.writerows([[1,'luke','96'],[2,'jack','85'],[3,'nick','84']])
with open("test.csv","r",encoding='utf-8') as csvfile:
lst=csv.reader(csvfile)
csvfile.seek(0)
txtdata = csvfile.read()
csvfile.seek(0)
for i in lst:
print(i)
txtdata #>>'num,name,grade\n1,luke,96\n2,jack,85\n3,nick,84\n'

总结
到此这篇关于python open函数中newline参数实例详解的文章就介绍到这了,更多相关python open函数newline参数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中open函数的基本用法示例
前言 本文主要介绍的是关于python中open函数用法的相关资料,用法如下: name = open('errname.txt','w')<br>name.readline()<br>name.close() 1.看下第一行的代码 用来访问磁盘中存放的文件,可以进行读写等操作,例如上例中 'w',这里便是对errname.txt这个文件进行读操作 例如: w:以写方式打开 a:以追加方式打开 r+:以读写模式打开 w+:以读写模式打开 rb:以二进制读模式打开 wb:以二进制写模
-

探究python中open函数的使用
最近,开始学习python的开发,遇到了一点文件操作的问题,探究一下open函数的使用. 一.open()的函数原型 open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True) 从官方文档中我们可以看到open函数有很多的参数,我们常用的是file,mode和encoding,对于其它的几个参数,平时不常用,也简单介绍一下. buffering的可取值有0,1, >1三个,0
-
python open函数中newline参数实例详解
目录 问题的由来 具体实例 总结 问题的由来 我在读pythoncsv模块文档 看到了这样一句话 如果 csvfile 是文件对象,则打开它时应使用 newline=‘’.其备注:如果没有指定 newline=‘’,则嵌入引号中的换行符将无法正确解析,并且在写入时,使用 \r\n 换行的平台会有多余的 \r 写入.由于 csv 模块会执行自己的(通用)换行符处理,因此指定 newline=‘’ 应该总是安全的. 我就在思考open函数中的newline参数的作用,因为自己之前在使用open函数时
-
使用 Python 读取电子表格中的数据实例详解
Python 是最流行.功能最强大的编程语言之一.由于它是自由开源的,因此每个人都可以使用.大多数 Fedora 系统都已安装了该语言.Python 可用于多种任务,其中包括处理逗号分隔值(CSV)数据.CSV文件一开始往往是以表格或电子表格的形式出现.本文介绍了如何在 Python 3 中处理 CSV 数据. CSV 数据正如其名.CSV 文件按行放置数据,数值之间用逗号分隔.每行由相同的字段定义.简短的 CSV 文件通常易于阅读和理解.但是较长的数据文件或具有更多字段的数据文件可能很难用肉眼
-
React.memo函数中的参数示例详解
目录 React.memo?这是个啥? React.memo的第一个参数 父组件 子组件 React.memo优化 React.memo的第二个参数 父组件 子组件 React.memo优化 父组件 子组件 小结 React.memo?这是个啥? 按照官方文档的解释: 如果你的函数组件在给定相同 props 的情况下渲染相同的结果,那么你可以通过将其包装在 React.memo 中调用,以此通过记忆组件渲染结果的方式来提高组件的性能表现.这意味着在这种情况下,React 将跳过渲染组件的操作并直
-
Python定义函数功能与用法实例详解
本文实例讲述了Python定义函数功能与用法.分享给大家供大家参考,具体如下: 1.函数的意义 一般数学上的函数是,一个或者几个自变量,通过某种计算方式,得出一个因变量. y = f(x) 在Python中,为了使操作更加简洁,就引入了函数这个概念. Python中的函数,可以把一大串要反复使用的代码"定义"(封装)成一个函数,给予这个函数一个标识符作为函数名,设置自变量和因变量.然后要使用这一大串代码的时候,就调用这个我们自己创造的函数,输入自变量,然后会返回给我们因变量. 2.函数
-
python orm 框架中sqlalchemy用法实例详解
本文实例讲述了python orm 框架中sqlalchemy用法.分享给大家供大家参考,具体如下: 一.ORM简介 1. ORM(Object-Relational Mapping,对象关系映射):作用是在关系型数据库和业务实体对象之间做一个映射. 2. ORM优点: 向开发者屏蔽了数据库的细节,使开发者无需与SQL语句打交道,提高了开发效率; 便于数据库的迁移,由于每种数据库的SQL语法有差别,基于Sql的数据访问层在更换数据库时通过需要花费时间调试SQL时间,而ORM提供了独立于SQL的接
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
python3中sorted函数里cmp参数改变详解
今天在刷leetcode的时候,对于179题返回最大数,用python2中的sorted(cmp)会很方便,但是在python3中这一参数被取消了,经过查找,发现应该借助functools中的cmp_to_key函数,直接贴代码 import functools def cmp(a,b): if a > b : return -1 elif a < b : return 1 else: return 0 nums = [1,2,3,4,5,6] sorted_nums = sorted(num
-
python中time包实例详解
在python中基础的时间运用,离不开time函数的支持.这些函数为了方便调用集中放在一个地方,叫做time包.有的人会仔细追寻time包的来源,会发现它和C语言有密不可分的关系.下面我们简单介绍time包的概念,然后就包中的一些函数进行列举,并附上对应的使用方法. 1.概念 time包基于C语言的库函数(library functions).Python的解释器通常是用C编写的,Python的一些函数也会直接调用C语言的库函数. 2.time包中的函数 time.clock()返回程序运行的整
-
对Python多线程读写文件加锁的实例详解
Python的多线程在io方面比单线程还是有优势,但是在多线程开发时,少不了对文件的读写操作.在管理多个线程对同一文件的读写操作时,就少不了文件锁了. 使用fcntl 在linux下,python的标准库有现成的文件锁,来自于fcntl模块.这个模块提供了unix系统fcntl()和ioctl()的接口. 对于文件锁的操作,主要需要使用 fcntl.flock(fd, operation)这个函数. 其中,参数 fd 表示文件描述符:参数 operation 指定要进行的锁操作,该参数的取值有如
-
Tensorflow 使用pb文件保存(恢复)模型计算图和参数实例详解
一.保存: graph_util.convert_variables_to_constants 可以把当前session的计算图串行化成一个字节流(二进制),这个函数包含三个参数:参数1:当前活动的session,它含有各变量 参数2:GraphDef 对象,它描述了计算网络 参数3:Graph图中需要输出的节点的名称的列表 返回值:精简版的GraphDef 对象,包含了原始输入GraphDef和session的网络和变量信息,它的成员函数SerializeToString()可以把这些信息串行