kubernetes k8s常用问题排查方法
目录
- Pod 的那些状态
- 镜像拉取失败
- 启动后容器崩溃
- 容器被驱逐
- 总结
Pod 的那些状态
使用 K8s 部署我们的服务之后,为了观察 Pod 是否成功,我们都会使用下面这个命令查询 Pod 的状态。
kubectl get pods NAME READY STATUS RESTARTS AGE my-app-5d7d978fb9-2fj5m 0/1 ContainerCreating 0 10s my-app-5d7d978fb9-dbt89 0/1 ContainerCreating 0 10s
这里的 STATUS 代表了 Pod 的状态,可能会遇到的状态有下面几个:
- ContainerCreating:代表容器正在创建,这是一个中间状态,随着容器创建成功会切换,但是也有可能一直卡在这里,具体问题下面会分析。
- ImagePullBackOff:容器镜像拉取失败,具体原因需要结合 describe 命令再去查看。
- CrashLoopBackOff:容器崩溃,一般容器崩溃,Deployment 会重新创建一个 Pod,维持副本数量,但是大概率新创建的Pod 还是会崩溃,它不会无限尝试,崩溃超过设置次数就不会再尝试重建Pod,此时Pod的状态就维持在了 CrashLoopBackOff。
- Evicted: 因为节点资源不足(CPU/Mem/Storage都有可能),Pod 被驱逐会显示 Evicted 状态,K8s 会按照策略选择认为可驱逐的Pod从节点上 Kill 掉。
- Running 这个代表 Pod 正常运行。
下面我们来看一下 Pod 的几个错误状态的原因,以及怎么排查解决它们。
镜像拉取失败
镜像拉取失败后 Pod 的状态字段表示为 ImagePullBackOff,这个发生的情况还是很多的,原因除了我们不小心写错镜像名字之外,还有就是常用软件的一些官方镜像都在国外,比如在docker.io 或者 quay.io 的镜像仓库上,有的时候访问速度会很慢。
下面我们自己故意制造一个镜像名字写错的场景,看怎么使用 kubectl 命令进行排查。比如我在 K8s 教程里一直用的 Deployment 定义:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-go-app
spec:
replicas: 2
selector:
matchLabels:
app: go-app
template:
metadata:
labels:
app: go-app
spec:
containers:
- name: go-app-container
image: kevinyan001/kube-go-app:v0.3
resources:
limits:
memory: "200Mi"
cpu: "50m"
ports:
- containerPort: 3000
volumeMounts:
- name: app-storage
mountPath: /tmp
volumes:
- name: app-storage
emptyDir: {}
我们把镜像的名字故意改错,改成 v0.5,这个镜像是我自己打的,确实还没有 0.5 版本。执行kubectl apply 后,来观察一下 Pod 的状态。
➜ kubectl apply -f deployment.yaml deployment.apps/my-go-app configured ➜ kubectl get pods NAME READY STATUS RESTARTS AGE my-go-app-5d7d978fb9-2fj5m 1/1 Running 0 3h58m my-go-app-5d7d978fb9-dbt89 1/1 Running 0 3h58m my-go-app-6b77dbbcc5-jpgbw 0/1 ContainerCreating 0 7s ➜ kubectl get pods NAME READY STATUS RESTARTS AGE my-go-app-5d7d978fb9-2fj5m 1/1 Running 0 3h58m my-go-app-5d7d978fb9-dbt89 1/1 Running 0 3h58m my-go-app-6b77dbbcc5-jpgbw 0/1 ErrImagePull 0 14s .....// 停顿1分钟,再查看Pod 的状态 ➜ kubectl get pods NAME READY STATUS RESTARTS AGE my-go-app-5d7d978fb9-2fj5m 1/1 Running 0 4h1m my-go-app-5d7d978fb9-dbt89 1/1 Running 0 4h1m my-go-app-6b77dbbcc5-jpgbw 0/1 ImagePullBackOff 0 3m11s
上面我们更新了 deployment 之后,观察到 Pod 的状态变化过程是:
ContainerCreating ===> ErrImagePull ===> ImagePullBackOff
首先 deployment 更新 Pod 时是滚动更新,要先把新 Pod 创建出来后能对旧版本 Pod 完成替换。接下来由于镜像拉取错误会反馈一个中间状态 ErrImagePull,此时会再次尝试拉取,如果确定镜像拉取不下来后,最后反馈一个失败的终态 ImagePullBackOff。
怎么排查是什么导致的拉取失败呢?通过 kubectl describe pod {pod-name} 查看它的事件记录
➜ kubectl describe pod my-go-app-6b77dbbcc5-jpgbw
Name: my-go-app-6b77dbbcc5-jpgbw
Namespace: default
Priority: 0
...
Controlled By: ReplicaSet/my-go-app-6b77dbbcc5
Containers:
go-app-container:
Container ID:
Image: kevinyan001/kube-go-app:v0.5
Image ID:
Port: 3000/TCP
Host Port: 0/TCP
State: Waiting
Reason: ErrImagePull
Ready: False
...
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 2m12s default-scheduler Successfully assigned default/my-go-app-6b77dbbcc5-jpgbw to docker-desktop
Normal Pulling 27s (x4 over 2m12s) kubelet Pulling image "kevinyan001/kube-go-app:v0.5"
Warning Failed 20s (x4 over 2m4s) kubelet Failed to pull image "kevinyan001/kube-go-app:v0.5": rpc error: code = Unknown desc = Error response from daemon: manifest for kevinyan001/kube-go-app:v0.5 not found: manifest unknown: manifest unknown
Warning Failed 20s (x4 over 2m4s) kubelet Error: ErrImagePull
Normal BackOff 4s (x5 over 2m4s) kubelet Back-off pulling image "kevinyan001/kube-go-app:v0.5"
Warning Failed 4s (x5 over 2m4s) kubelet Error: ImagePullBackOff
Pod 事件记录里,清楚记录了 Pod 从开始到最后经历的状态变化,以及是什么导致状态变化的,其中失败事件里清楚的给出了我们原因,就是镜像找不到。
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning Failed 20s (x4 over 2m4s) kubelet Failed to pull image "kevinyan001/kube-go-app:v0.5": rpc error: code = Unknown desc = Error response from daemon: manifest for kevinyan001/kube-go-app:v0.5 not found: manifest unknown: manifest unknown Warning Failed 20s (x4 over 2m4s) kubelet Error: ErrImagePull Normal BackOff 4s (x5 over 2m4s) kubelet Back-off pulling image "kevinyan001/kube-go-app:v0.5" Warning Failed 4s (x5 over 2m4s) kubelet Error: ImagePullBackOff
还有一种是网络原因,或者镜像仓库没有权限拒绝拉取请求,导致无法拉取成功。因为我这里网络环境、加速器之类的好不容易都配好了,就不给大家演示这两种情况了。
不过排查方式也是一样,使用kubectl describe 命令查看 Pod 的事件,并且使用 docker pull 尝试主动的拉取一下镜像试试,如果确实网络问题拉取不下来的,可以考虑翻墙,或者使用国内的加速节点。
配置加速器,可以考虑使用阿里云的免费加速器,配置文档在下面,需要注册阿里云账号才能使用加速器
https://help.aliyun.com/product/60716.html
启动后容器崩溃
再来看这种错误,这种一般是容器里运行的程序内部出问题导致的容器连续崩溃出现的问题。最后反馈到 Pod 状态上是 CrashLoopBackOff 状态。
演示容器运行中崩溃的情况有点难,不过好在我之前介绍 Go 服务自动采样的时候,做过一个镜像
以下内容引用我之前的文章:Go 服务进行自动采样性能分析的方案设计与实现
我做了个docker 镜像方便进行试验,镜像已经上传到了Docker Hub上,大家感兴趣的可以Down下来自己在电脑上快速试验一下。
通过以下命令即可快速体验。
docker run --name go-profile-demo -v /tmp:/tmp -p 10030:80 --rm -d kevinyan001/go-profiling
容器里Go服务提供的路由如下
所以我们把上面的 deployment Pod 模版里的镜像换成这个 kevinyan001/go-profiling,再通过提供的路由手动制造 OOM,来故意制造容器崩溃的情况。
修改Pod 使用的容器镜像
#执行 kubectl apply -f deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-go-app
spec:
replicas: 2
selector:
matchLabels:
app: go-app
template:
metadata:
labels:
app: go-app
spec:
containers:
- name: go-app-container
image: kevinyan001/go-profiling:latest
resources:
limits:
memory: "200Mi"
cpu: "50m"
创建个 SVC 让Pod能接受外部流量
#执行 kubectl apply -f service.yaml
apiVersion: v1
kind: Service
metadata:
name: app-service
spec:
type: NodePort
selector:
app: go-app
ports:
- name: http
protocol: TCP
nodePort: 30080
port: 80
targetPort: 80
程序中提供的路由如下:
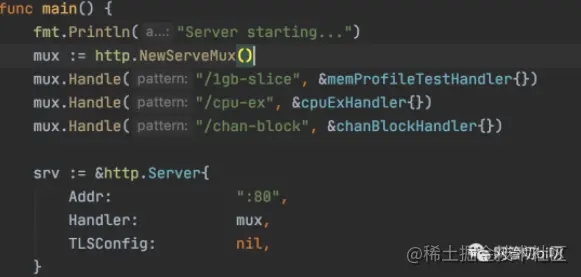
访问 http://127.0.0.1:30080/1gb-slice 让容器内存溢出,因为 Deployment 会重启崩溃的 Pod,所以这里非常考验手速:) 估计狂点一分钟,Deployment 就放弃治疗休息会儿再重启 Pod,这时 Pod 的状态成功变成了:
➜ kubectl get pods NAME READY STATUS RESTARTS AGE my-go-app-598f697676-f5jfp 0/1 CrashLoopBackOff 2 (18s ago) 5m37s my-go-app-598f697676-tps7n 0/1 CrashLoopBackOff 2 (23s ago) 5m35s
这个时候我们使用 kubectl describe pod 看崩溃 Pod 的详细信息,会看到容器内程序返回的错误码
➜ kubectl describe pod my-go-app-598f697676-tps7n
Name: my-go-app-598f697676-tps7n
Namespace: default
Port: 3000/TCP
Host Port: 0/TCP
State: Running
Started: Sun, 20 Mar 2022 16:09:29 +0800
Last State: Terminated
Reason: Error
Exit Code: 137
Started: Sun, 20 Mar 2022 16:08:56 +0800
Finished: Sun, 20 Mar 2022 16:09:05 +0800
不过要深入排查 Pod 内容器的问题,需要另一个命令 kubectl logs {pod-name} 的协助。
kubectl logs my-go-app-598f697676-tps7n
如果恰巧这个 Pod 被重启了,查不出来任何东西,可以通过增加 — previous 参数选项,查看之前容器的日志。
kubectl logs my-go-app-598f697676-tps7n --previous
容器被驱逐
首先声明,这个问题研发解决不了,但是你发挥一下自己YY的能力:当群里报警、运维@你赶紧看的时候,你来个反杀,告诉他资源不够了赶紧扩容,是不是能装到^_^…
扯远了,现在回正题。集群里资源紧张的时候,K8s 会优先驱逐优先级低的 Pod,被驱逐的 Pod 的状态会是 Evicted,这个情况没办法在本地模拟,贴一个在公司K8s集群遇到这种情况的截图。
kubectl get pod 查看Pod状态
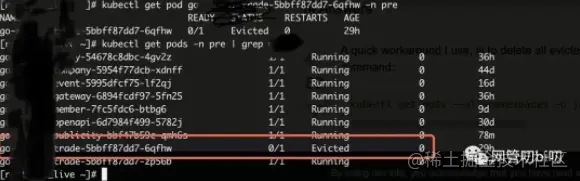
上图可以看到有一个Pod 的状态变成了 Evicted。
再来用describe 看下详细信息
kubectl describe pod 查看Pod 的详细信息和事件记录
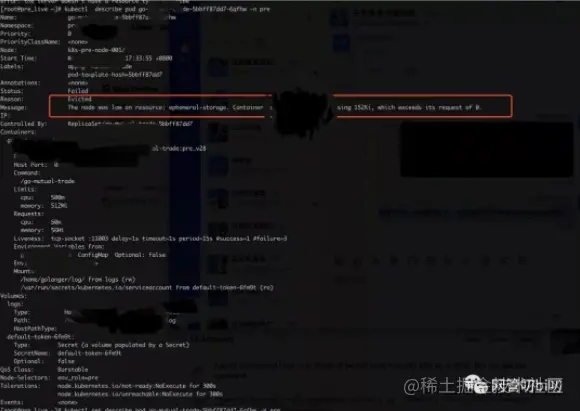
不好意思,历史久远,上面的图太模糊了,图中的Message 一栏里有给出如下信息:
Status: Faild Reason: Evicted Message: The node wan low on resource: xxx-storage. Container xxx using xxxKi, which exceeds its request of ....
总结
一般来说,大多数常见的部署失败都可以使用这些命令进行排查和调试:
kubectl get pods
kubectl describe pod <podname>
kubectl logs <podname>
kubectl logs <podname> --previous
当然,有的时候想看 Pod 的配置信息,还可以使用
kubectl get pod <podname> -o=yaml
验证一下Pod的配置是不是跟我们提交上去的一样,以及一些其他的额外信息。
get 和 describe 这两个命令除了能看 Pod 的状态和信息记录外,也能看其他资源的状态和信息。
kubectl get pod|svc|deploy|sts|configmap <xxx-name> kubectl describe pod|svc|deploy|sts|configmap <xxx-name>
这些就留给大家后面自己体验吧。为了方便大家在本地试验,在公众号「网管叨bi叨」回复【k8s】能找到今天用的各种YAML的模版,感兴趣的可以动手实践起来。
以上就是kubernetes k8s常用问题排查方法的详细内容,更多关于kubernetes k8s问题排查方法的资料请关注我们其它相关文章!
相关推荐
-
kubernetes(k8s)安装metrics-server实现资源使用情况监控方式详解
1. Metrics Server 与 kubenetes版本 Metrics Server Metrics API group/version Supported Kubernetes version0.6x metrics.k8s.io/v1beta1 *1.19+0.5x metrics.k8s.io/v1beta1 *1.8+0.4x metrics.k8s.io/v1beta1 *1.8+0.3x metrics.k8s.io/v1
-

K8ssandra入门教程之Linux上部署K8ssandra到Kubernetes的过程
目录 1 什么是K8ssandra 2 安装K8ssandra 2.1 安装Kubenetes 2.2 安装helm3 2.3 用Helm安装K8ssandra 2.4 增加节点 3 查看监控 4 总结 1 什么是K8ssandra Cassandra是一款非常优秀的开源的分布式NoSQL数据库,被许多优秀的大公司采用,具有高可用.弹性扩展.性能好等特点. 正应Cassandra的优势,我们经常需要在云上服务使用,则需要部署Cassandra到K8s上,这就有了K8ssandra.K8ssand
-
Kubernetes(k8s)基础介绍
之前我一直想学习Kubernetes,因为它听起来很有意思(如果你是希腊人,你会觉得这个名字很有问题),但我从来没有机会,因为我没有任何东西需要运行在集群中.而最近,我的工作中开始逐步涉及Kubernetes相关的事情,所以这次我抓住机会,开始查资料,但后来我发现目前所有的资料(包括官方教程)都过于冗长,结构也不合理,这让我一开始有点沮丧. 经过几天的研究,我开始逐步理解Kubernetes的核心理念,并且把他部署到了生产环境中.因为我的简历现在说自己是个"Kubernetes专家",
-
云原生技术kubernetes(K8S)简介
目录 01 kubernetes是什么? 02 kubernetes和Compost+Swarm之间的区别 03 一点总结 今天我们看看kubernetes技术的介绍,最近在极客时间上看张磊老师的深入kubernetes技术,讲的非常好,有兴趣的同学可以去收听一下,对于理解kubernetes技术非常有帮助,这里我会按照自己的进度,分享一下学习的笔记. 今天站的角度比较高,概念性质的东西会多一点. 01 kubernetes是什么? 曾经我认为这个问题很好回答,直到不断的去理解kubernete
-
kubernetes k8s常用问题排查方法
目录 Pod 的那些状态 镜像拉取失败 启动后容器崩溃 容器被驱逐 总结 Pod 的那些状态 使用 K8s 部署我们的服务之后,为了观察 Pod 是否成功,我们都会使用下面这个命令查询 Pod 的状态. kubectl get pods NAME READY STATUS RESTARTS AGE my-app-5d7d978fb9-2fj5m 0/1 ContainerCreating 0 10s my-app-5d7d978fb9-dbt89 0/1 ContainerCreating 0
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇
Kubernetes(通常称为"K8S")是Google开源的容器集群管理系统.其设计目标是在主机集群之间提供一个能够自动化部署.可拓展.应用容器可运营的平台.Kubernetes通常结合docker容器工具工作,并且整合多个运行着docker容器的主机集群,Kubernetes不仅仅支持Docker,还支持Rocket,这是另一种容器技术.Kubernetes是一个用于容器集群的自动化部署.扩容以及运维的开源平台. 本文系列: Kubernetes(K8S)容器集群管理环境完整部署详
-
k8s部署ingress-nginx的方法步骤
目录 前言 一.部署配置Ingress 二.使用https 前言 k8s集群服务部署好之后,需要对外提域名访问,这时候就需要ingress-nginx了,今天来给大家分享一下 一.部署配置Ingress 1.获取配置文件 #文件已下载到本地 https://github.com/kubernetes/ingress-nginx/tree/nginx-0.20.0/deploy 2.准备镜像 unzip ingress-nginx-nginx-0.20.0.zip cd ingress-nginx
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇
本文系列: Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇 在前一篇文章中详细介绍了Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇,这里继续记录下Kubernetes集群插件等部署过程: 十一.Kubernetes集群插件 插件是Kubernetes集群的附件组件,丰富和完善了集群的功能,这里分别介绍的插件有cor
-
Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇
本文系列: Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-中篇 Kubernetes(K8S)容器集群管理环境完整部署详细教程-下篇 接着Kubernetes(K8S)容器集群管理环境完整部署详细教程-上篇继续往下部署: 八.部署master节点 master节点的kube-apiserver.kube-scheduler 和 kube-controller-manager 均以多实例模式运行:kube-sc
-
Kubernetes(K8S)入门基础内容介绍
Introduction basic of kubernetes 我们要学习 Kubernetes,就有首先了解 Kubernetes 的技术范围.基础理论知识库等,要学习 Kubernetes,肯定要有入门过程,在这个过程中,学习要从易到难,先从基础学习. 那么 Kubernetes 的入门基础内容(表示学习一门技术前先了解这门技术)包括哪些? 根据 Linux 开源基金会的认证考试,可以确认要了解 Kubernetes ,需要达成以下学习目标: Discuss Kubernetes. Lea
-
Kubernetes(K8S)基础知识
目录 Kubernetes 是什么 Kubernetes 集群的组成 Kubernetes 结构 组件 Master 节点 kube-apiserver etcd kube-scheduler kube-controller-manager Kubernetes 是什么 在 2008 年,LXC(Linux containers) 发布第一个版本,这是最初的容器版本:2013 年,Docker 推出了第一个版本:而 Google 则在 2014 年推出了 LMCTFY. 为了解决大集群(Clus
-
kubernetes k8s CRD学习笔记
目录 CustomResourceDefinition简介: 目前扩展Kubernetes API的常用方式有3种: 配置规范 示例1: 创建自定义CRD 示例2: etcd Operator 部署 (该项目已不在维护) CustomResourceDefinition简介: 在 Kubernetes 中一切都可视为资源,Kubernetes 1.7 之后增加了对 CRD 自定义资源二次开发能力来扩展 Kubernetes API,通过 CRD 我们可以向 Kubernetes API 中增加新
-
Kubernetes(k8s 1.23))安装与卸载详细教程
目录 请注意k8s在1.24版本不支持docker容器,本文使用kubeadm进行搭建 1.查看系统版本信息以及修改配置信息 2. 安装docker 3.安装kubeadm kubelet kubectl 4.卸载k8s 镜像下载.域名解析.时间同步请点击 阿里云开源镜像站 请注意k8s在1.24版本不支持docker容器,本文使用kubeadm进行搭建 1.查看系统版本信息以及修改配置信息 1.1 安装k8s时,临时关闭swap ,如果不关闭在执行kubeadm部分命令会报错 swapoff