Matlab操作HDF5文件示例
目录
- HDF5文件
- 使用Matlab操作HDF5文件
- 使用Matlab创建HDF5文件
- 使用Matlab写入HDF5
- 使用Matlab查看HDF5文件信息
- 使用Matlab读取HDF5中的数据集
HDF5文件
在使用Matlab对数据进行预处理时,遇到了内存不足的问题,因为数据量太大,在处理完成以前内存已经爆满。如果使用Matlab的.m文件对文件进行存储的话,则需要将数据分割成多个文件,对后续的处理造成了不便。HDF5文件则是一种灵活的文件存储格式,有一个最大的好处就是在Matlab的处理过程中可以对它进行扩展写入,也就是说不是所有数据处理完以后一次写入,而是边处理边写入,极大的降低了对系统内存的要求。
HDF5文件类似与一个文件系统,使用这个文件本身就可以对数据集(dataset)进行管理。例如下图所示,HDF5文件中的数据集皆存储根目录/,在根目录下存在多个group,这样一些group类似与文件系统的文件夹,在它们可以存储别的group,也可以存储数据集。
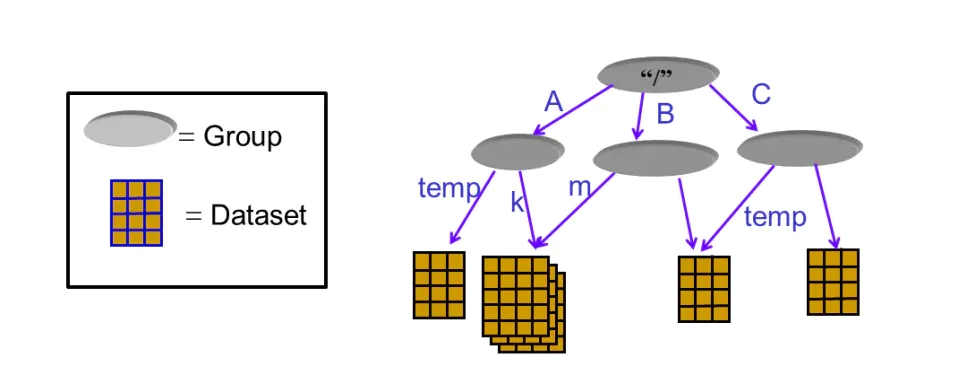
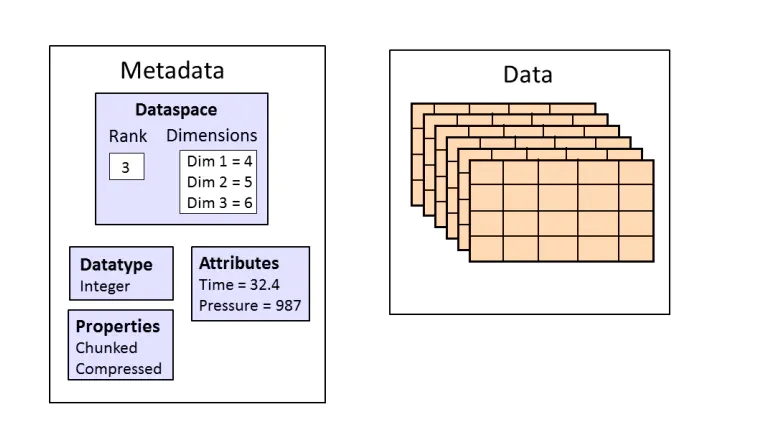
对于每一个dataset 而言,除了数据本身之外,这个数据集还会有很多的属性 attribute,。在hdf5中,还同时支持存储数据集对应的属性信息,所有的属性信息的集合就叫做metadata;
使用Matlab操作HDF5文件
使用Matlab创建HDF5文件
使用Matlab创建HDF5文件的函数是h5create,使用如下:
h5create(filename,datasetname,[30, 30 , 3, inf],'Datatype','single','ChunkSize',[30,30,3,1000])
filename为h5文件的文件名(不知道什么问题,在我的电脑上使用时,这个函数无法指定路径)。
datasetname则为数据集的名字,数据集名称必须以/开头,比如/G。
[30,30,3,inf]位数据集的大小,比如我的数据集为30x30大小的彩色图像,并且我希望数量能够扩展,那么就可以指定最后以为度为inf,以表示数量不限。
Datatype为数据类型
ChunkSize为数据存储的最小分块,为了让数据能够具有扩展性,所以为新来的数据分配一定的空间大小,对于一个非常大的数据,这个值设置大一点比较好,这样分块就会少一点。比如我的数据集中,30x30大小的彩色图像大概有10万个左右,那么1000个存储在一起较为合适,则chunksize设置为:[30,30,3,1000]。
使用Matlab写入HDF5
在创建了hdf5文件和数据集以后,则可以对数据集进行写操作以扩展里面的数据。使用Matlab写入HDF5文件的函数是h5write,使用如下:
h5write(fileName,datasetName,data,start,count);
fileName: hdf5文件名
datasetName:数据集名称,比如/Gdata:需要写入的数据,数据的维度应该与创建时一致,比如,设置的数据集大小为[30,30,3,inf],那么这里的data的前三个维度就应该是[30, 30, 3],而最后一个维度则是自由的
start:数据存储的起点,如果是第一次存,则应该为[1, 1, 1, 1](注意数据维度的一致性),如果这次存了10000个样本,也就是[30,30,3,10000],那么第二次存储的时候起点就应该为[1,1,1,10001]
count存储数据的个数,同样要根据维度来(其实就是数据的维度),这里为[30,30,3,10000]
使用Matlab查看HDF5文件信息
Matlab中可以使用h5info函数来读取HDF5文件的信息:
fileInfo = h5info(fileName);
然后通过解析fileInfo结构,则可以得到HDF5文件中的数据集名称、数据集大小等等必要信息。
使用Matlab读取HDF5中的数据集
Matlab中可以使用h5read函数来读取HDF5文件:
data = h5read(filename,datasetname,start,count)
filename:HDF5文件文件名
datasetname:数据集名称
start:从数据集中取数据的其实位置
count:取的数据数量
还是以上面的30x30的彩色图像为例,如果每次需要取1000个,那么第一次取时,start应该设置为[1, 1, 1, 1] ,count设置为:[30, 30 ,3 1000]。第二次取值时,start则应该设置为[1, 1, 1, 1001],count则设置为:[30, 30, 3, 1000]。
以上就是Matlab操作HDF5文件示例的详细内容,更多关于Matlab操作HDF5文件的资料请关注我们其它相关文章!
相关推荐
-
Python存储读取HDF5文件代码解析
HDF5 简介 HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件.HDF 最早由美国国家超级计算应用中心 NCSA 开发,目前在非盈利组织 HDF 小组维护下继续发展.当前流行的版本是 HDF5.HDF5 拥有一系列的优异特性,使其特别适合进行大量科学数据的存储和操作,如它支持非常多的数据类型,灵活,通用,跨平台,可扩展,高效的 I/O 性能,支持几乎无限量(高达 EB)的单文件存储等,详见其官方介绍:https://suppo
-

python可视化hdf5文件的操作
对于一些复杂的hdf5文件,通过可视化的方法可以比较容易的了解文件的内部结构,下面介绍基于python的一个hdf5文件的安装使用方法 1 安装vitables工具包 命令 pip install vitables 2 安装完成后在终端中使用命令 vitables 文件名.hdf5 最终实现hdf5文件的可视化,方便直观就像一层层打开文件夹一样 补充:python对于HDF5的操作 看代码吧~ import h5py #导入工具包 import numpy as np #HDF5的写入: img
-
如何用pandas处理hdf5文件
什么是HDF5 HDF5:Hierarchical Data Format Version 5,对于存储大规模.具有相同类型的数据,HDF5是一种非常不错的存储格式,文件后缀名为h5.这种格式的文件的存储和读取速度非常快,并且我们可以把HDF5文件看成是一个"目录",它是分层次的,我们来看看如何操作. 创建和读取HDF5文件 import pandas as pd import numpy as np hdf5 = pd.HDFStore("hello.h5", m
-
python3 hdf5文件 遍历代码
看代码吧~ import h5py import numpy as np f = h5py.File('train/e1_1.hdf5') key = "" for k in f.keys(): key = k d = f[key] print(d) a = np.ones(d.shape) d.read_direct(a) print(a) f.close() 补充:HDF5 文件及Python模块之h5py HDF5文件 什么是HDF5文件呢? 先引用一波维基百科的介绍,『层级数据
-
R语言rhdf5读写hdf5并展示文件组织结构和索引数据
前言 h5只是一种简单的数据组织格式[层级数据存储格式(HierarchicalDataFormat:HDF)],该格式被设计用以存储和组织大量数据. 在一些单细胞文献中,作者通常会将分析的数据上传到GEO数据库保存为.h5格式文件,而不是我们常见的工程文件(rds文件,表格数据等),所以为了解析利用这些数据需要对hdf5格式的组织结构有一定的了解. (注:在Seurat包中有现成的函数Seurat::Read10X_h5()可以用来提取表达矩阵,但似乎此外无法从h5文件中提取更多的信息). G
-
Python操作HDF5文件示例
目录 引言 创建文件和数据集 写数据集 读数据集 引言 在Matlab操作HDF5文件中已经详细介绍了HDF5文件已经利用Matlab对其进行操作的方法.这篇文章总结一下如何在Python下使用HDF5文件.我们仍然按照Matlab操作HDF5文件的顺序进行,分别是创建HDF5文件,写入数据,读取数据. Python下的HDF5文件依赖h5py工具包 创建文件和数据集 使用`h5py.File()方法创建hdf5文件 h5file = h5py.File(filename,'w') 然后在此基础
-
Matlab操作HDF5文件示例
目录 HDF5文件 使用Matlab操作HDF5文件 使用Matlab创建HDF5文件 使用Matlab写入HDF5 使用Matlab查看HDF5文件信息 使用Matlab读取HDF5中的数据集 HDF5文件 在使用Matlab对数据进行预处理时,遇到了内存不足的问题,因为数据量太大,在处理完成以前内存已经爆满.如果使用Matlab的.m文件对文件进行存储的话,则需要将数据分割成多个文件,对后续的处理造成了不便.HDF5文件则是一种灵活的文件存储格式,有一个最大的好处就是在Matlab的处理过程
-
java使用pdfbox操作pdf文件示例
还有一个用于创建PDF文件的项目----iText. PDFBox下面有两个子项目:FontBox是一个处理PDF字体的java类库:JempBox是一个处理XMP元数据的java类库. 一个简单示例: 要引入pdfbox-app-1.6.0.jar这个包. 复制代码 代码如下: package pdf; import java.io.File;import java.net.MalformedURLException; import org.apache.pdfbox.pdmodel.PDDo
-
c#操作xml文件示例
1. 新增XML文件 复制代码 代码如下: XMLToolV2 _xmlHelper = new XMLToolV2(@"C:\20140311blogs.xml");//xml保存路径或者读取路径 _xmlHelper.Create("Person", "utf-8");//跟节点名称:person;encode:utf-8 XmlElement _person = _xmlHelper.CreateElec("Name",
-
asp.net操作ini文件示例
复制代码 代码如下: using System;using System.Data;using System.Configuration;using System.Web;using System.Web.Security;using System.Web.UI;using System.Web.UI.WebControls;using System.Web.UI.WebControls.WebParts;using System.Web.UI.HtmlControls; using Syste
-
python操作xml文件示例
复制代码 代码如下: def get_seed_data(filename):dom = minidom.parse(filename)root = dom.documentElementsystem_nodes = root.getElementsByTagName("system")k = 0seed_list = []for system_node in system_nodes: #print system_node.nodeName+' id='+system_node
-
python操作toml文件的示例代码
# -*- coding: utf-8 -*- # @Time : 2019-11-18 09:31 # @Author : cxa # @File : toml_demo.py # @Software: PyCharm import toml import os BASE_DIR = os.path.dirname(os.path.abspath(__file__)) class FileOperation: def __init__(self): self.dic = dict() self