Python爬虫基础之初次使用scrapy爬虫实例
项目需求
在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句。
创建项目
在开始爬取之前,必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令:
(base) λ scrapy startproject quotes
New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1ates\project ', created in:
D:\XXX
You can start your first spider with :
cd quotes
scrapy genspider example example. com
首先切换到新建的爬虫项目目录下,也就是/quotes目录下。然后执行创建爬虫文件的命令:
D:\XXX(master) (base) λ cd quotes\ D:\XXX\quotes (master) (base) λ scrapy genspider quotes quotes.com cannot create a spider with the same name as your project D :\XXX\quotes (master) (base) λ scrapy genspider quote quotes.com created spider 'quote' using template 'basic' in module:quotes.spiders.quote
该命令将会创建包含下列内容的quotes目录:

robots.txt
robots协议也叫robots.txt(统一小写)是一种存放于网站根目录下的ASCII编码的文本文件,它通常告诉网络搜索引擎的网络蜘蛛,此网站中的哪些内容是不应被搜索引擎的爬虫获取的,哪些是可以被爬虫获取的。
robots协议并不是一个规范,而只是约定俗成的。
#filename : settings.py #obey robots.txt rules ROBOTSTXT__OBEY = False
分析页面
编写爬虫程序之前,首先需要对待爬取的页面进行分析,主流的浏览器中都带有分析页面的工具或插件,这里我们选用Chrome浏览器的开发者工具(Tools→Developer tools)分析页面。
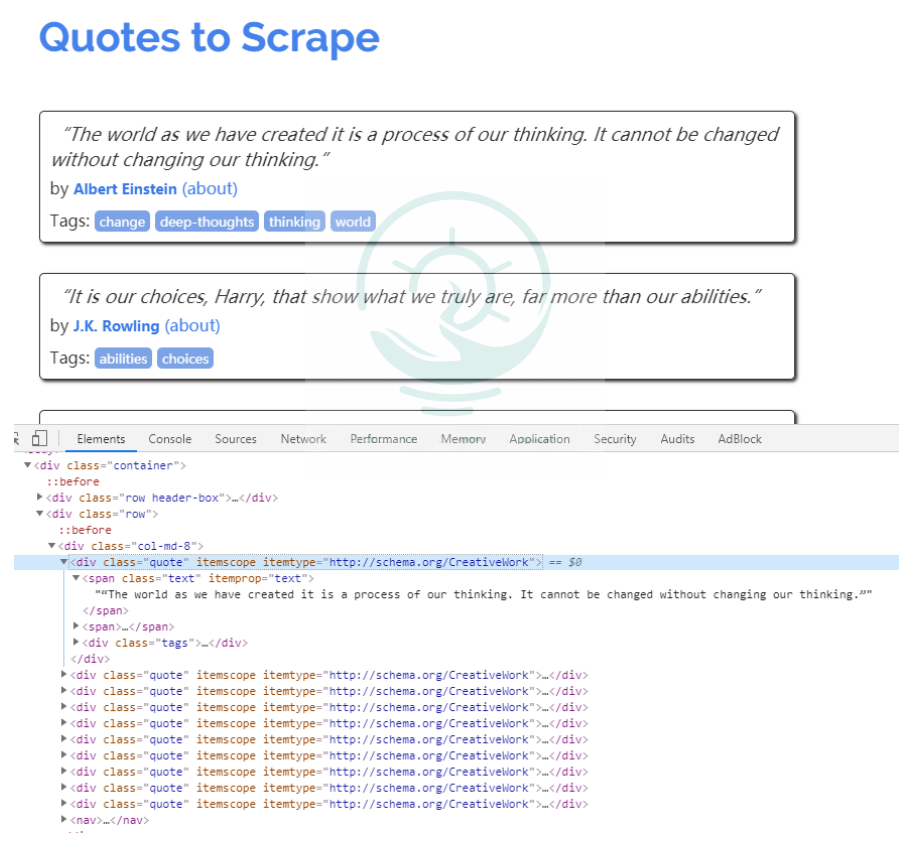
数据信息
在Chrome浏览器中打开页面http://lquotes.toscrape.com,然后选择"Elements",查看其HTML代码。
可以看到每一个标签都包裹在
编写spider
分析完页面后,接下来编写爬虫。在Scrapy中编写一个爬虫, 在scrapy.Spider中编写代码Spider是用户编写用于从单个网站(或者-些网站)爬取数据的类。
其包含了-个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容,提取生成item的方法。
为了创建一个Spider, 您必须继承scrapy.Spider类,且定义以下三个属性:
- name:用于区别Spider。该名字必须是唯一-的, 您不可以为不同的Spider设定相同的名字。
- start _urls:包含了Spider在启动时进行爬取的ur列表。因此, 第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。
- parse():是spider的一一个方法。被调用时,每个初始URL完成下载后生成的Response对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL 的Request对象。
import scrapy
class QuoteSpi der(scrapy . Spider):
name ='quote'
allowed_ domains = [' quotes. com ']
start_ urls = ['http://quotes . toscrape . com/']
def parse(self, response) :
pass
下面对quote的实现做简单说明。
- scrapy.spider :爬虫基类,每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及您自己编写的spider)。
- name是爬虫的名字,是在genspider的时候指定的。
- allowed_domains是爬虫能抓取的域名,爬虫只能在这个域名下抓取网页,可以不写。
- start_ur1s是Scrapy抓取的网站,是可迭代类型,当然如果有多个网页,列表中写入多个网址即可,常用列表推导式的形式。
- parse称为回调函数,该方法中的response就是start_urls 网址发出请求后得到的响应。当然也可以指定其他函数来接收响应。一个页面解析函数通常需要完成以下两个任务:
1.提取页面中的数据(re、XPath、CSS选择器)
2.提取页面中的链接,并产生对链接页面的下载请求。
页面解析函数通常被实现成一个生成器函数,每一项从页面中提取的数据以及每一个对链接页面的下载请求都由yield语句提交给Scrapy引擎。
解析数据
import scrapy
def parse(se1f,response) :
quotes = response.css('.quote ')
for quote in quotes:
text = quote.css( '.text: :text ' ).extract_first()
auth = quote.css( '.author : :text ' ).extract_first()
tages = quote.css('.tags a: :text' ).extract()
yield dict(text=text,auth=auth,tages=tages)
重点:
- response.css(直接使用css语法即可提取响应中的数据。
- start_ur1s 中可以写多个网址,以列表格式分割开即可。
- extract()是提取css对象中的数据,提取出来以后是列表,否则是个对象。并且对于
- extract_first()是提取第一个
运行爬虫
在/quotes目录下运行scrapycrawlquotes即可运行爬虫项目。
运行爬虫之后发生了什么?
Scrapy为Spider的start_urls属性中的每个URL创建了scrapy.Request对象,并将parse方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成scrapy.http.Response对象并送回给spider parse()方法进行处理。
完成代码后,运行爬虫爬取数据,在shell中执行scrapy crawl <SPIDER_NAME>命令运行爬虫'quote',并将爬取的数据存储到csv文件中:
(base) λ scrapy craw1 quote -o quotes.csv 2021-06-19 20:48:44 [scrapy.utils.log] INF0: Scrapy 1.8.0 started (bot: quotes)
等待爬虫运行结束后,就会在当前目录下生成一个quotes.csv的文件,里面的数据已csv格式存放。
-o支持保存为多种格式。保存方式也非常简单,只要给上文件的后缀名就可以了。(csv、json、pickle等)
到此这篇关于Python爬虫基础之初次使用scrapy爬虫实例的文章就介绍到这了,更多相关Python scrapy框架内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
python scrapy项目下spiders内多个爬虫同时运行的实现
一般创建了scrapy文件夹后,可能需要写多个爬虫,如果想让它们同时运行而不是顺次运行的话,得怎么做? a.在spiders目录的同级目录下创建一个commands目录,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只修改run()方法即可! import os from scrapy.commands import ScrapyCommand from scrapy.utils.conf import arglist
-
python Scrapy爬虫框架的使用
导读:如何使用scrapy框架实现爬虫的4步曲?什么是CrawSpider模板?如何设置下载中间件?如何实现Scrapyd远程部署和监控?想要了解更多,下面让我们来看一下如何具体实现吧! Scrapy安装(mac) pip install scrapy 注意:不要使用commandlinetools自带的python进行安装,不然可能报架构错误:用brew下载的python进行安装. Scrapy实现爬虫 新建爬虫 scrapy startproject demoSpider,demoSpide
-
在python3.9下如何安装scrapy的方法
本文主要介绍了在python3.9下如何安装scrapy的方法,分享给大家,具体如下: 安装命令: pip install scrapy -i https://pypi.douban.com/simple 如果安装失败的话像下图这样(解决方法如下): 出现原因:我在python3.7版本里安装没有出现这样的情况,但是在3.9版本中出现了这样的错误.在这里scrapy会自动将一些常用的配置包给我们安装上,但是twisted这个包安装的时候会报错. 解决方法: 1.面对这个问题,其实我们无法通过用p
-
python爬虫scrapy基本使用超详细教程
一.介绍 官方文档:中文2.3版本 下面这张图大家应该很熟悉,很多有关scrapy框架的介绍中都会出现这张图,感兴趣的再去查询相关资料,当然学会使用scrapy才是最主要的. 二.基本使用 2.1 环境安装 1.linux和mac操作系统: pip install scrapy 2.windows系统: 先安装wheel:pip install wheel 下载twisted:下载地址 安装twisted:pip install Twisted‑17.1.0‑cp36‑cp36m‑win_amd
-
Python爬虫框架-scrapy的使用
Scrapy Scrapy是纯python实现的一个为了爬取网站数据.提取结构性数据而编写的应用框架. Scrapy使用了Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求 1.安装 sudo pip3 install scrapy 2.认识scrapy框架 2.1 scrapy架构图 Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递
-
Python爬虫基础之初次使用scrapy爬虫实例
项目需求 在专门供爬虫初学者训练爬虫技术的网站(http://quotes.toscrape.com)上爬取名言警句. 创建项目 在开始爬取之前,必须创建一个新的Scrapy项目.进入您打算存储代码的目录中,运行下列命令: (base) λ scrapy startproject quotes New scrapy project 'quotes ', using template directory 'd: \anaconda3\lib\site-packages\scrapy\temp1at
-
python web基础之加载静态文件实例
在web运行中很重要的一个功能就是加载静态文件,在django中可能已经给我们设置好了,我们只要直接把模板文件 放在templates就好了,但是你知道在基础中,像图片是怎么加载以及找到相应位置的吗? 下面我们来看看. 在上篇文章中我把,静态文件的路径单独出来在这里说说了,正好说说全局变量request的作用. 首先,我们写前端图片的路径: <img src="/static?file=1.gif"/> 看到这里,可能已经有人看出来了,对的,我们把图片路径看成url路径和参
-
Python爬虫基础讲解之scrapy框架
网络爬虫 网络爬虫是指在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人.大型的爬虫程序被广泛应用于搜索引擎.数据挖掘等领域,个人用户或企业也可以利用爬虫收集对自身有价值的数据. 一个网络爬虫程序的基本执行流程可以总结三个过程:请求数据,解析数据,保存数据 数据请求 请求的数据除了普通的HTML之外,还有json数据.字符串数据.图片.视频.音频等. 解析数据 当一个数据下载完成后,对数据中的内容进行分析,并提取出需要的数据,提取到的数据可以以多种形式保存起来,数据的格式有非常多
-
Python爬虫基础之简单说一下scrapy的框架结构
scrapy 框架结构 思考 scrapy 为什么是框架而不是库? scrapy是如何工作的? 项目结构 在开始爬取之前,必须创建一个新的Scrapy项目.进入您打算存储代码的目录中,运行下列命令: 注意:创建项目时,会在当前目录下新建爬虫项目的目录. 这些文件分别是: scrapy.cfg:项目的配置文件 quotes/:该项目的python模块.之后您将在此加入代码 quotes/items.py:项目中的item文件 quotes/middlewares.py:爬虫中间件.下载中间件(处理
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Python 利用scrapy爬虫通过短短50行代码下载整站短视频
近日,有朋友向我求助一件小事儿,他在一个短视频app上看到一个好玩儿的段子,想下载下来,可死活找不到下载的方法.这忙我得帮,少不得就抓包分析了一下这个app,找到了视频的下载链接,帮他解决了这个小问题. 因为这个事儿,勾起了我另一个念头,这不最近一直想把python爬虫方面的知识梳理梳理吗,干脆借机行事,正凑着短视频火热的势头,做一个短视频的爬虫好了,中间用到什么知识就理一理. 我喜欢把事情说得很直白,如果恰好有初入门的朋友想了解爬虫的技术,可以将就看看,或许对你的认识会有提升.如果有高手路过,
-
python爬虫基础知识点整理
首先爬虫是什么? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 根据我的经验,要学习Python爬虫,我们要学习的共有以下几点: Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy Python爬虫更高级的功能 1.Python基础学习 首先,我们要用Python写爬虫,肯定要了解Python的基础吧,万丈高楼平地起,
-
一文读懂python Scrapy爬虫框架
Scrapy是什么? 先看官网上的说明,http://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. S
-
Python之Scrapy爬虫框架安装及使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了 页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫. 本文档将
-
Python之Scrapy爬虫框架安装及简单使用详解
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 其最初是为了页面抓取(更确切来说,网络抓取)所设计的, 也可以应用在获取API所返回的数据(例如Amazon Associates Web Services) 或者通用的网络爬虫. 本文档将通过介绍Sc