SpringBoot简单使用SpringData的jdbc和durid
SpringData的jdbc和durid
创建一个项目,勾选以下选项

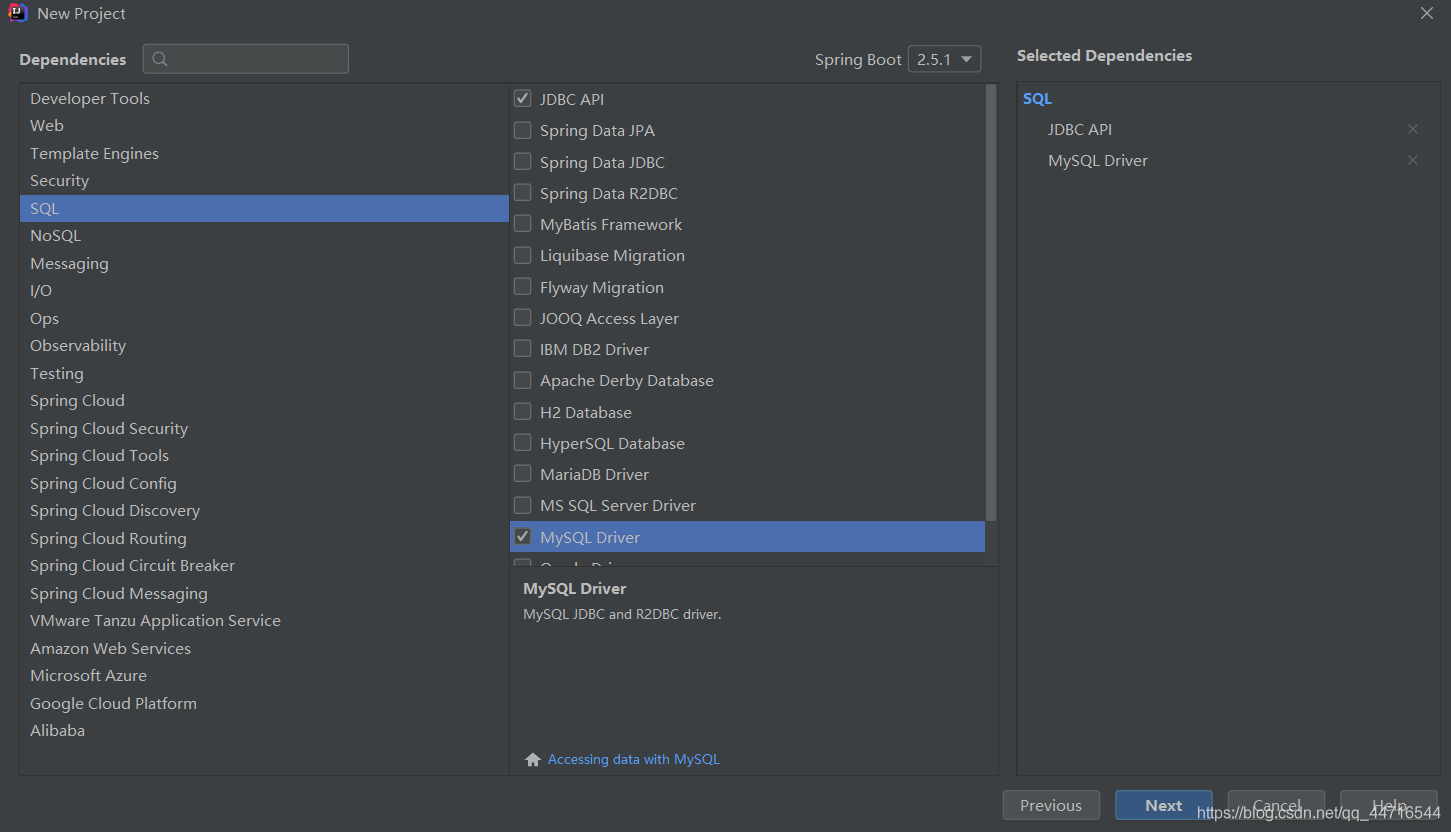
项目构建完成后pom.xml已导入(springboot默认导入数据库驱动为8.0,要使用低版本需要手动改版本)

编写yaml配置文件连接数据库;

spring:
datasource:
username: root
password: 123
url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.jdbc.Driver
#springBoot数据库驱动默认为mysql8.0版本,使用8.0以下版本的数据库需要在pom.xml手动更改数据库驱动版本
因为SpringBoot已经默认进行了自动配置;去测试类测试一下
@Test
void contextLoads() throws SQLException {
//查看一下默认的数据源 :class com.zaxxer.hikari.HikariDataSource
System.out.println(dataSource.getClass());
//获得数据库连接
Connection connection=dataSource.getConnection();
System.out.println(connection);
//xxxx Template:SpringBoot 已经配置好模板bean,拿来即用 CRUD
//关闭
connection.close();
}
查看控制台,输出为:
class com.zaxxer.hikari.HikariDataSource
说明没有问题
HikariDataSource 号称 Java WEB 当前速度最快的数据源,相比于传统的 C3P0 、DBCP、Tomcat jdbc 等连接池更加优秀;
可以使用 spring.datasource.type 指定自定义的数据源类型,值为 要使用的连接池实现的完全限定名。
- 有了数据库连接,就可以 CRUD 操作数据库了。使用对象 JdbcTemplate进行操作。
- 即使不使用第三方第数据库操作框架,如 MyBatis等,Spring 本身也对原生的JDBC 做了轻量级的封装,即JdbcTemplate。
- 数据库操作的所有 CRUD 方法都在 JdbcTemplate 中。
JdbcTemplate主要提供以下几类方法:
- execute方法:可以用于执行任何SQL语句,一般用于执行DDL语句;
- update方法及batchUpdate方法:update方法用于执行新增、修改、删除等语句;batchUpdate方法用于执行批处理相关语句;
- query方法及queryForXXX方法:用于执行查询相关语句;
- call方法:用于执行存储过程、函数相关语句。
然后进行编写测试类,进行crud
创建一个控制类,JDBCController.java

import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
import java.util.Map;
@RestController
public class JDBCController {
@Autowired
JdbcTemplate jdbcTemplate;
//查询数据库的所有信息
//没有实体类,数据库中的东西,怎么获取?map
@GetMapping("userList")
public List<Map<String,Object>> userList(){
String sql="select*from user";
List<Map<String,Object>> mapList=jdbcTemplate.queryForList(sql);
return mapList;
}
//添加一个用户
@GetMapping("/addUser")
public String addUser(){
String sql="insert into mybatis.user(name,pwd) values('笑','123456')";
int n= jdbcTemplate.update(sql);
return String.valueOf(n);
}
//更改一个用户
@GetMapping("/updateUser/{id}")
public String updateUser(@PathVariable("id") int id){
String sql="update mybatis.user set name=?,pwd=? where id="+id;
//封装
Object[] objects=new Object[2];
objects[0] ="小明2";
objects[1] ="456";
int n= jdbcTemplate.update(sql,objects);
return String.valueOf(n);
}
//删除一个用户
@GetMapping("/deleteUser/{id}")
public String deleteUser(@PathVariable("id") int id){
String sql="delete from mybatis.user where id=?";
int n= jdbcTemplate.update(sql,id);
return String.valueOf(n);
}
}
创建一个数据库:mybatis
然后创建数据表:
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(25) CHARACTER SET gbk COLLATE gbk_chinese_ci NULL DEFAULT NULL, `pwd` varchar(25) CHARACTER SET gbk COLLATE gbk_chinese_ci NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 18 CHARACTER SET = gbk COLLATE = gbk_chinese_ci ROW_FORMAT = Compact; -- ---------------------------- -- Records of user -- ---------------------------- INSERT INTO `user` VALUES (3, '小黑', '789'); INSERT INTO `user` VALUES (4, '可可2', '151'); INSERT INTO `user` VALUES (5, '阿毛', '4566977'); INSERT INTO `user` VALUES (6, '小明', 'cafa1414f'); INSERT INTO `user` VALUES (7, '嘻嘻3', '101112'); INSERT INTO `user` VALUES (8, '很爱很爱你', '101112'); INSERT INTO `user` VALUES (9, '小霞', '159'); INSERT INTO `user` VALUES (10, '嘻嘻5', '101112'); INSERT INTO `user` VALUES (11, '陈', 'dad45'); INSERT INTO `user` VALUES (12, '陈2', 'd2ad45'); INSERT INTO `user` VALUES (13, '小明', '123456'); INSERT INTO `user` VALUES (14, '小明2', '456'); INSERT INTO `user` VALUES (17, '阿毛', '4566977'); SET FOREIGN_KEY_CHECKS = 1;
然后启动服务,在浏览器打开:http://localhost:8080/userList

其它更改,删除,添加操作也是如此,
Druid 是阿里巴巴开源平台上一个数据库连接池实现,结合了 C3P0、DBCP 等 DB 池的优点,同时加入了日志监控. Druid 可以很好的监控 DB 池连接和 SQL 的执行情况,天生就是针对监控而生的 DB 连接池.
然后更改application.yml
spring:
datasource:
username: root
password: 123
url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.jdbc.Driver
#springBoot数据库驱动默认为mysql8.0版本,使用8.0以下版本的数据库需要在pom.xml手动更改数据库驱动版本
#切换为阿里巴巴druid源
type: com.alibaba.druid.pool.DruidDataSource
# 自定义数据源
#Spring Boot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入
#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority
#则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4j
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
然后在pom.xml导入依赖
<!-- https://mvnrepository.com/artifact/com.alibaba/druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.5</version>
</dependency>
<!--log4j-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.16</version>
</dependency>
再次在测试类测试
发现数据源已更改为阿里的:class com.alibaba.druid.pool.DruidDataSource
Druid 数据源具有监控的功能,并提供了一个 web 界面方便用户查看,类似安装 路由器 时,人家也提供了一个默认的 web 页面。
所以第一步需要设置 Druid 的后台管理页面,比如 登录账号、密码 等;配置后台管理
新建一个配置类:DruidConfig

import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource(){
return new DruidDataSource();
}
//后台监控:web.xml,ServletRegistrationBean
//因为SpringBoot 内置了servlet容器,所以没有web.xml,替代方法
//访问:http://localhost:8080/druid
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean bean= new ServletRegistrationBean<>(new StatViewServlet(),"/druid/*");
//后台需要有人登录,账号密码配置
HashMap<Object,Object> initParameters=new HashMap<>();
initParameters.put("loginUsername","admin");//登录key 是固定的loginUserUsername loginPassword
initParameters.put("loginPassword","123456");
//允许谁可以访问
initParameters.put("allow","");
//禁止谁能访问 initParameters.put("allow","121.0.0.1");
bean.setInitParameters(initParameters);//设置初始化参数
return bean;
}
//filter
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean bean=new FilterRegistrationBean();
bean.setFilter(new WebStatFilter());
//可以过滤哪些请求呢?
Map<String,String> initParameters=new HashMap<>();
//这些东西不进行统计
initParameters.put("exclusions","*.js,*.css,/druid/*");
bean.setInitParameters(initParameters);
return bean;
}
}
然后启动项目
浏览器打开:
http://localhost:8080/druid,进入登陆页面,填写登陆账号,密码
进入到监控页面

到此这篇关于SpringBoot简单使用SpringData的jdbc和durid的文章就介绍到这了,更多相关SpringData的jdbc和durid内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
SpringData Repository Bean方法定义规范代码实例
本节主要介绍Repository Bean中方法定义规范. 1.方法不是随便声明,需要符合一定的规范. 2.按照Spring Data的规范,查询方法以find|read|get开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性需要首字母大写. 3.Spring Data支持的关键字如下: 4.支持属性的级联查询,若当前类有符合条件的属性,则优先使用,而不使用级联属性.若想使用级联属性,则属性之间用"_"连接. package com.ntjr.springdata
-

springdata jpa单表操作crud的实例代码详解
1. 项目搭建 使用boot整合,导入springdata jap, mysql 驱动,lombok,web. 1.1 配置 # boot add jpa, oh~ crud in single table server: port: 8888 spring: # datasource datasource: username: root password: 123456 driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://
-
解决springdataJPA对原生sql支持的问题
springdataJPA对原生sql支持问题 在项目中用到的是springdataJPA连接数据库进行操作,但是JPA中的hql语句不能够满足业务要求,因而需要用到原生sql 但是有一个问题: @Query(value = "SELECT ppd.* FROM zt_productionplandetails AS ppd \n" + " \tLEFT JOIN zt_salesplan sp ON sp.id=ppd.salesPlan_id \n" + &qu
-
解析SpringBoot整合SpringDataRedis的过程
Spring-Data-Redis项目(简称SDR)对Redis的Key-Value数据存储操作提供了更高层次的抽象,类似于Spring Framework对JDBC支持一样. 项目主页: http://projects.spring.io/spring-data-redis/ 项目文档: http://docs.spring.io/spring-data/redis/docs/1.5.0.RELEASE/reference/html/ 本文给大家介绍SpringBoot整合SpringData
-
详解SpringBoot是如何整合SpringDataRedis的?
一.创建项目添加依赖 创建SpringBoot项目,并添加如下依赖: <dependencies> <!-- springBoot 的启动器 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- Spri
-
SpringBoot简单使用SpringData的jdbc和durid
SpringData的jdbc和durid 创建一个项目,勾选以下选项 项目构建完成后pom.xml已导入(springboot默认导入数据库驱动为8.0,要使用低版本需要手动改版本) 编写yaml配置文件连接数据库: spring: datasource: username: root password: 123 url: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8 driver-cla
-
springboot+webmagic实现java爬虫jdbc及mysql的方法
前段时间需要爬取网页上的信息,自己对于爬虫没有任何了解,就了解了一下webmagic,写了个简单的爬虫. 一.首先介绍一下webmagic: webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取.页面下载.内容抽取.持久化),支持多线程抓取,分布式抓取,并支持自动重试.自定义UA/cookie等功能. 实现理念: Maven依赖: <dependency> <groupId>us.codecraft</groupId> <artifactId
-
使用SpringBoot简单了解Druid的监控系统的配置方法
Druid 介绍 说起 Druid,大家首先想到的是阿里的 Druid 数据库连接池 Apache Druid 具有以下特点: 亚秒级 OLAP 查询,包括多维过滤.Ad-hoc 的属性分组.快速聚合数据等等. 实时的数据消费,真正做到数据摄入实时.查询结果实时. 高效的多租户能力,最高可以做到几千用户同时在线查询. 扩展性强,支持 PB 级数据.千亿级事件快速处理,支持每秒数千查询并发. 极高的高可用保障,支持滚动升级. Druid监控系统作用 查看慢SQL [ 可进行对 SQL 优化 ] 是
-
springboot简单接入websocket的操作方法
序 最近一个项目又重启了,之前支付了要手动点击已付款,所以这次想把这个不友好体验干掉.另外以后的扫码登录什么的都需要这个服务支持.之前扫码登录这块用的mqtt,时间上是直接把mqtt的连接信息返回给前端.前端连接mqtt服务,消费信息.这次不想这样弄了,准备接入websocket. 一.环境说明 我这里是springBoot2.4.5 + springCloud2020.1.2,这里先从springBoot对接开始,逐步再增加深度,不过可能时间不够,就简单接入能满足现在业务场景就stop.没办法
-
springboot简单实现单点登录的示例代码
什么是单点登录就不用再说了,今天通过自定义sessionId来实现它,想了解的可以参考https://www.xuxueli.com/xxl-sso/ 讲一下大概的实现思路吧:这里有一个认证中心,两个单独的服务.每个服务去请求的 时候都要经过一个过滤器,首先判断该请求地址中有没有sessionid,有的话则写入cookie ,如果请求地址中没有sessionid那么从cookie中去获取,如果cookie中获取到了则证明登录了,放行即可.否则跳转到认证中心,此时把请求地址当做参数带到认证中,认证
-
搭建简单的Spring-Data JPA项目
目录 一. JPA概述 二.jpa_demo step1:首先导入需要的依赖 step2:编写实体类和数据库表的映射配置[重点] step3:编写配置文件属性 step4:编写测试用例 一. JPA概述 JPA的全称是Java Persistence API, 即Java 持久化API,是SUN公司推出的一套基于ORM的规范,内部是由一系列的接口和抽象类构成. JPA通过JDK 5.0注解描述对象-关系表的映射关系,并将运行期的实体对象持久化到数据库中. 二.jpa_demo step1:首先导
-
SpringBoot简单实现文件上传
目录 1.创建SpringBoot项目 2.修改application.properties配置文件 3.编写控制器UserController类 4.编写前端页面index.html 5.效果展示 前言: 这里给大家介绍如何在SpringBoot项目中实现文件上传功能! 1.创建SpringBoot项目 打开IDEA,点击文件,选择新建项目,点击Spring Initializr,然后根据自己的需求设置项目名称,位置以及JDK.这里需要注意,服务器的URL最好设置为阿里云服务器,这样可以使得项
-
Springboot简单热部署实现步骤解析
最近开始学习使用springboot但springboot项目和之前的ssm等各种框架项目有所不同,本身集成了很多繁琐的东西,但 一些小功能还需自己配置.下面开始配置热部署. 首先当然是导入热部署的依赖. <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>tru
-
springBoot 与neo4j的简单整合示例
Neo4j简介 Neo4j是基于java语言实现的世界领先的图形数据库, 是一个高性能的图形存储,具有成熟和强大的数据库所需的所有功能,如友好的查询语言(Cypher)和ACID事务.对于许多应用程序,与关系数据库相比,Neo4j提供了数量级的性能优势.主要应用于图检索和关系计算.其优点在于: 节点没上线(3.0以后去掉了限制) 扩展性很好,支持集群和企业版 数据ETL有丰富的工具支持,自带GUI 良好的WebUI 更加详细的介绍参考:https://neo4j.com/docs/getting
-
springboot websocket简单入门示例
之前做的需求都是客户端请求服务器响应,新需求是服务器主动推送信息到客户端.百度之后有流.长轮询.websoket等方式进行.但是目前更加推崇且合理的显然是websocket. 从springboot官网翻译了一些资料,再加上百度简单实现了springboot使用websocekt与客户端的双工通信. 1.首先搭建一个简单的springboot环境 <!-- Inherit defaults from Spring Boot --> <parent> <groupId>o