Apache Hadoop版本详解
由于Hadoop版本混乱多变,因此,Hadoop的版本选择问题一直令很多初级用户苦恼。本文总结了ApacheHadoop和Cloudera Hadoop的版本衍化过程,并给出了选择Hadoop版本的一些建议。
1.Apache HadoopApache版本衍化
截至目前(2012年12月23日),ApacheHadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop2.0。第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其中,0.20.x最后演化成1.0.x,变成了稳定版,而0.21.x和0.22.x则NameNodeHA等新的重大特性。第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNodeHA和Wire-compatibility两个重大特性。
经过上面的大体解释,大家可能明白了Hadoop以重大特性区分各个版本的,总结起来,用于区分Hadoop版本的特性有以下几个:
(1)Append支持文件追加功能,如果想使用HBase,需要这个特性。
(2)RAID在保证数据可靠的前提下,通过引入校验码较少数据块数目。详细链接:
https://issues.apache.org/jira/browse/HDFS/component/12313080
(3)Symlink支持HDFS文件链接,具体可参考:https://issues.apache.org/jira/browse/HDFS-245
(4)SecurityHadoop安全,具体可参考:https://issues.apache.org/jira/browse/HADOOP-4487
(5)NameNodeHA具体可参考:https://issues.apache.org/jira/browse/HDFS-1064
(6)HDFSFederation和YARN
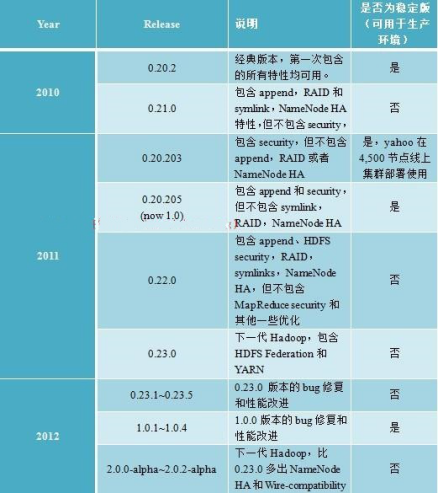
需要注意的是,Hadoop2.0主要由Yahoo独立出来的hortonworks公司主持开发。
Apache版本下载
(1)各版本说明:http://hadoop.apache.org/releases.html。
(2)下载稳定版:找到一个镜像,下载stable文件夹下的版本。
(3)Hadoop最全版本:http://svn.apache.org/repos/asf/hadoop/common/branches/,可直接导到eclipse中。
2.Cloudera HadoopCDH版本衍化
Apache当前的版本管理是比较混乱的,各种版本层出不穷,让很多初学者不知所措,相比之下,Cloudera公司的Hadoop版本管理的要很多。
我们知道,Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本,其中比较出名的一是Cloudera公司的发行版,我们将该版本称为CDH(ClouderaDistributionHadoop)。截至目前为止,CDH共有4个版本,其中,前两个已经不再更新,最近的两个,分别是CDH3(在Apache Hadoop0.20.2版本基础上演化而来的)和CDH4在Apache Hadoop2.0.0版本基础上演化而来的),分别对应Apache的Hadoop 1.0和Hadoop2.0,它们每隔一段时间便会更新一次。
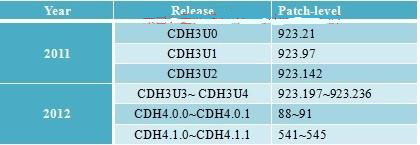
Cloudera以patch level划分小版本,比如patch level为923.142表示在原生态Apache Hadoop0.20.2基础上添加了1065个patch(这些patch是各个公司或者个人贡献的,在Hadoopjira上均有记录),其中923个是最后一个beta版本添加的patch,而142个是稳定版发行后新添加的patch。由此可见,patchlevel越高,功能越完备且解决的bug越多。
Cloudera版本层次更加清晰,且它提供了适用于各种操作系统的Hadoop安装包,可直接使用apt-get或者yum命令进行安装,更加省事。
CDH版本下载
(1)版本含义介绍:
https://ccp.cloudera.com/display/DOC/CDH+Version+and+Packaging+Information
(2)各版本特性查看:
https://ccp.cloudera.com/display/DOC/CDH+Packaging+Information+for+Previous+Releases
(3)各版本下载:
CDH3:http://archive.cloudera.com/cdh/3/
CDH4:http://archive.cloudera.com/cdh4/cdh/4/
注意,Hadoop压缩包在这两个链接中的最上层目录中,不在某个文件夹里,很多人进到链接还找不到安装包!
3.如何选择Hadoop版本
当前Hadoop版本比较混乱,让很多用户不知所措。实际上,当前Hadoop只有两个版本:Hadoop1.0和Hadoop 2.0,其中,Hadoop1.0由一个分布式文件系统HDFS和一个离线计算框架MapReduce组成,而Hadoop2.0则包含一个支持NameNode横向扩展的HDFS,一个资源管理系统YARN和一个运行在YARN上的离线计算框架MapReduce。相比于Hadoop1.0,Hadoop 2.0功能更加强大,且具有更好的扩展性、性能,并支持多种计算框架。
当我们决定是否采用某个软件用于开源环境时,通常需要考虑以下几个因素:
(1)是否为开源软件,即是否免费。
(2)是否有稳定版,这个一般软件官方网站会给出说明。
(3)是否经实践验证,这个可通过检查是否有一些大点的公司已经在生产环境中使用知道。
(4)是否有强大的社区支持,当出现一个问题时,能够通过社区、论坛等网络资源快速获取解决方法。
考虑到以上几个因素,我们分析一下开源软件Hadoop。对于Hadoop2.0而言,目前尚不稳定,无法用于生产环境,因此,如果当前你正准备使用Hadoop,那么只能从Hadoop1.0中选择一个版本,而目截至目前(2012年12月23日),Apache和Cloudera最新的稳定版分别是Hadoop1.0.4和CDH3U4,因此,你可以从中任选一个使用。
总结
以上所述是小编给大家介绍的Apache Hadoop版本详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Java执行hadoop的基本操作实例代码
Java执行hadoop的基本操作实例代码 向HDFS上传本地文件 public static void uploadInputFile(String localFile) throws IOException{ Configuration conf = new Configuration(); String hdfsPath = "hdfs://localhost:9000/"; String hdfsInput = "hdfs://localhost:9000/user/
-

详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
Hadoop多Job并行处理的实例详解
Hadoop多Job并行处理的实例详解 有关Hadoop多Job任务并行处理,经过测试,配置如下: 首先做如下配置: 1.修改mapred-site.xml添加调度器配置: <property> <name>mapred.jobtracker.taskScheduler</name> <value>org.apache.hadoop.mapred.FairScheduler</value> </property> 2.添加jar文件地
-
hadoop格式化HDFS出现错误解决办法
hadoop格式化HDFS出现错误解决办法 报错信息: host:java.net.UnknownHostException: centos-wang: centos-wang: unknown error 在执行hadoop namenode -format命令时,出现未知的主机名. 问题原因: 出现这种问题的原因是Hadoop在格式化HDFS的时候,通过hostname命令获取到的主机名与/etc/hosts文件中进行映射的时候,没有找到. 解决方案: 1.修改/etc/hosts内容 2.
-
Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
hadoop是什么语言
Hadoop是什么?Hadoop是一个开发和运行处理大规模数据的软件平台,是Appach的一个用java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算. Hadoop框架中最核心设计就是:HDFS和MapReduce.HDFS提供了海量数据的存储,MapReduce提供了对数据的计算. 数据在Hadoop中处理的流程可以简单的按照下图来理解:数据通过Haddop的集群处理后得到结果. HDFS:Hadoop Distributed File System,Hadoop
-
hadoop重新格式化HDFS步骤解析
了解Hadoop的同学都知道,Hadoop有两个核心的组成部分,一个是HDFS,另一个则是MapReduce,HDFS作为Hadoop的数据存储方案,MapReduce则提供计算服务:同时,HDFS作为一种分布式文件系统,它的安装也是需要相应的格式化操作的,如果安装失败或者我们需要重新安装的时候,那我们就需要对HDFS重新进行格式化,这篇文章就和大家一起讨论下如何进行HDFS的重新格式化. 重新格式化hdfs系统的方法: 1.打开hdfs-site.xml 我们打开Hadoop的hdfs-sit
-
Apache Hadoop版本详解
由于Hadoop版本混乱多变,因此,Hadoop的版本选择问题一直令很多初级用户苦恼.本文总结了ApacheHadoop和Cloudera Hadoop的版本衍化过程,并给出了选择Hadoop版本的一些建议. 1.Apache HadoopApache版本衍化 截至目前(2012年12月23日),ApacheHadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop2.0.第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.
-
Python API 操作Hadoop hdfs详解
http://pyhdfs.readthedocs.io/en/latest/ 1:安装 由于是windows环境(linux其实也一样),只要有pip或者setup_install安装起来都是很方便的 >pip install hdfs 2:Client--创建集群连接 > from hdfs import * > client = Client("http://s100:50070") 其他参数说明: classhdfs.client.Client(url, ro
-
package.json管理依赖包版本详解
目录 npm版本号定义 package.json怎么识别依赖版本 不要太相信npm包的版本号 dependencies.devDependencies与peerDependencies dependencies devDependencies peerDependencies 参考 npm版本号定义 版本格式:X.Y.Z[-string]其含义为: X:主版本号 Y:次版本号 Z:修正版本号 string: 先行版本号或版本编译信息 举个例子: 6.3.2-alpha的含义为: 主版本号6,有6
-
如何为Spark Application指定不同的JDK版本详解
前言 随着企业内部业务系统越来越多,基于JVM的服务,通常情况线上环境可能会有多套JDK跑不同的服务.大家都知道基于高版本的Java规范编写的服务跑在低版本的JVM上会出现:java.lang.UnsupportedClassVersionError的异常. Spark 2.2开始移除了对Java 7的支持,大多数情况下,我们的Spark Application是和Hadoop系统公用的JDK,如果Hadoop依赖的JDK版本是7,那我们基于JDK 8编写的Application跑在上面就会出问
-
golang如何实现mapreduce单进程版本详解
前言 MapReduce作为hadoop的编程框架,是工程师最常接触的部分,也是除去了网络环境和集群配 置之外对整个Job执行效率影响很大的部分,所以很有必要深入了解整个过程.元旦放假的第一天,在家没事干,用golang实现了一下mapreduce的单进程版本,github地址.处理对大文件统计最高频的10个单词,因为功能比较简单,所以设计没有解耦合. 本文先对mapreduce大体概念进行介绍,然后结合代码介绍一下,如果接下来几天有空,我会实现一下分布式高可用的mapreduce版本.
-
apache日志文件详解和实用分析命令
一.日志分析 如果apache的安装时采用默认的配置,那么在/logs目录下就会生成两个文件,分别是access_log和error_log 1).access_log access_log为访问日志,记录所有对apache服务器进行请求的访问,它的位置和内容由CustomLog指令控制,LogFormat指令可以用来简化该日志的内容和格式 例如,我的其中一台服务器配置如下: 复制代码 代码如下: CustomLog "| /usr/sbin/rotatelogs /var/log/apache
-
apache .htaccess文件详解和配置技巧总结
一..htaccess的基本作用 .htaccess是一个纯文本文件,它里面存放着Apache服务器配置相关的指令. .htaccess主要的作用有:URL重写.自定义错误页面.MIME类型配置以及访问权限控制等.主要体现在伪静态的应用.图片防盗链.自定义404错误页面.阻止/允许特定IP/IP段.目录浏览与主页.禁止访问指定文件类型.文件密码保护等. .htaccess的用途范围主要针对当前目录. 二.启用.htaccess的配置启用.htaccess,需要修改http
-
百度语音识别(Baidu Voice) Android studio版本详解
百度语音识别(Baidu Voice) Android studio版本 已同步更新至个人blog:http://dxjia.cn/2016/02/29/baidu-voice-helper/ 最近在一个练手小项目里要用到语音识别,搜索了一下,比较容易集成的就算Baidu voice跟讯飞语音了,baidu提供了直接可以使用的显示控件,而讯飞需要自己实现,另外baidu提供每天5W次的调用频率,对于我来说足够使用啦.所以就选择使用Baidu Voice(控件会有baidu logo和关键字,所以
-
sql 版本详解 让你认识跟sql2000的区别
SQL2005 Express 没了「企业管理器」和「查询分析器」 SQL2005 分五个版本,如下所列: 1.Enterprise(企业版) 2.Development(开发版) 3.Workgroup,(工作群版) 4.Standard,(标准版) 5.Express.(嗯,姑且就叫它简易版吧) 这几个版本,我们究竟应该使用哪一版呢?这是许多初学 SQL2005 的人最常问的问题. 简单的比较一 下 Enterprise, Development 和 Express 等三个版本:以功能言,E
-
利用rpm安装mysql 5.6版本详解
前言 其实之前使用yum安装MySQL确实很方便,但是默认安装的myql5.0版本的,不支持utf8mb4(utf8mb4扩展到一个字符最多能有4节,所以能支持更多的字符集,比如支持emoji表情)编码格式,所以要升级数据库,yum库升级貌似有点费劲,果断卸载了,使用rpm直接安装 卸载的时候遇到一些问题,要卸载干净请参考之前写的一篇文章:http://www.jb51.net/article/97516.htm 言归正传,如何安装呢,其实很简单: 安装过程 一.先到官网地址下载两个包. 下载地