python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己《数据挖掘与分析》课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站。希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵。真的太忙了,太长时间没有写博客了,抱歉~
一.正则表达式
正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索、替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的“规则字符串”来对表达式进行过滤,从而获取或匹配我们想要的特定内容。它具有灵活、逻辑性和功能性非常的强,能迅速地通过表达式从字符串中找到所需信息的优点,但对于刚接触的人来说,比较晦涩难懂。
1.re模块
Python通过re模块提供对正则表达式的支持,使用正则表达式之前需要导入该库。
import re
import re其基本步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得一个匹配(Match)实例,再使用Match实例获得所需信息。常用的函数是findall,原型如下:
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
该函数表示搜索字符串string,以列表形式返回全部能匹配的子串。
其中参数re包括三个常见值:
(1)re.I(re.IGNORECASE):忽略大小写(括号内是完整写法)
(2)re.M(re.MULTILINE):允许多行模式
(3)re.S(re.DOTALL):支持点任意匹配模式
Pattern对象是一个编译好的正则表达式,通过Pattern提供的一系列方法可以对文本进行匹配查找。Pattern不能直接实例化,必须使用re.compile()进行构造。
2.complie方法
re正则表达式模块包括一些常用的操作函数,比如complie()函数。其原型如下:
compile(pattern[,flags] )
该函数根据包含正则表达式的字符串创建模式对象,返回一个pattern对象。参数flags是匹配模式,可以使用按位或“|”表示同时生效,也可以在正则表达式字符串中指定。Pattern对象是不能直接实例化的,只能通过compile方法得到。
简单举个实例,使用正则表达式获取字符串中的数字内容,如下所示:
>>> import re >>> string="A1.45,b5,6.45,8.82" >>> regex = re.compile(r"\d+\.?\d*") >>> print regex.findall(string) ['1.45', '5', '6.45', '8.82'] >>>
3.match方法
match方法是从字符串的pos下标处起开始匹配pattern,如果pattern结束时已经匹配,则返回一个Match对象;如果匹配过程中pattern无法匹配,或者匹配未结束就已到达endpos,则返回None。该方法原型如下:
match(string[, pos[, endpos]]) | re.match(pattern, string[, flags])
参数string表示字符串;pos表示下标,pos和endpos的默认值分别为0和len(string);参数flags用于编译pattern时指定匹配模式。
4.search方法
search方法用于查找字符串中可以匹配成功的子串。从字符串的pos下标处起尝试匹配pattern,如果pattern结束时仍可匹配,则返回一个Match对象;若无法匹配,则将pos加1后重新尝试匹配;直到pos=endpos时仍无法匹配则返回None。 函数原型如下:
search(string[, pos[, endpos]]) | re.search(pattern, string[, flags])
参数string表示字符串;pos表示下标,pos和endpos的默认值分别为0和len(string));参数flags用于编译pattern时指定匹配模式。
5.group和groups方法
group([group1, …])方法用于获得一个或多个分组截获的字符串,当它指定多个参数时将以元组形式返回。groups([default])方法以元组形式返回全部分组截获的字符串,相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
二.正则表达式抓取网络数据常见方法
在第三小节作者将介绍常用的正则表达式抓取网络数据的一些技巧,这些技巧都是作者自然语言处理和数据抓取实际编程中的总结,可能不是很系统,但是也能给读者提供一些抓取数据的思路以及解决实际的一些问题。
1.抓取标签间的内容
HTML语言是采用标签对的形式来编写网站的,包括起始标签和结束标签,比如<head></head>、<tr></tr>、<script><script>等。下面讲解抓取标签对之间的文本内容。
(1) 抓取title标签间的内容
首先爬取网页的标题,采用的正则表达式为'<title>(.*?)</title>',爬取百度标题代码如下:
# coding=utf-8 import re import urllib url = "http://www.baidu.com/" content = urllib.urlopen(url).read() title = re.findall(r'<title>(.*?)</title>', content) print title[0] # 百度一下,你就知道
代码调用urllib库的urlopen()函数打开超链接,并借用正则表达式库中的findall()函数寻找title标签间的内容,由于findall()函数获取所有满足该正则表达式的文本,故输出第一个值title[0]即可。下面是获取标签的另一种方法。
pat = r'(?<=<title>).*?(?=</title>)' ex = re.compile(pat, re.M|re.S) obj = re.search(ex, content) title = obj.group() print title # 百度一下,你就知道
(2) 抓取超链接标签间的内容
在HTML中,<a href=URL></a>用于标识超链接,test03_08.py文件用于获取完整的超链接和超链接<a>和</a>之间的内容。
# coding=utf-8 import re import urllib url = "http://www.baidu.com/" content = urllib.urlopen(url).read() #获取完整超链接 res = r"<a.*?href=.*?<\/a>" urls = re.findall(res, content) for u in urls: print unicode(u,'utf-8') #获取超链接<a>和</a>之间内容 res = r'<a .*?>(.*?)</a>' texts = re.findall(res, content, re.S|re.M) for t in texts: print unicode(t,'utf-8')
输出结果部分内容如下所示,这里如果直接输出print u或print t可能会乱码,需要调用函数unicode(u,'utf-8')进行转码。
#获取完整超链接 <a href="http://news.baidu.com" rel="external nofollow" rel="external nofollow" name="tj_trnews" class="mnav">新闻</a> <a href="http://www.hao123.com" rel="external nofollow" rel="external nofollow" name="tj_trhao123" class="mnav">hao123</a> <a href="http://map.baidu.com" rel="external nofollow" rel="external nofollow" name="tj_trmap" class="mnav">地图</a> <a href="http://v.baidu.com" rel="external nofollow" rel="external nofollow" name="tj_trvideo" class="mnav">视频</a> ... #获取超链接<a>和</a>之间内容 新闻 hao123 地图 视频 ...
(3) 抓取tr\td标签间的内容
网页中常用的布局包括table布局或div布局,其中table表格布局中常见的标签包括tr、th和td,表格行为tr(table row),表格数据为td(table data),表格表头th(table heading)。那么如何抓取这些标签之间的内容呢?下面代码是获取它们之间内容。
假设存在HTML代码如下所示:
<html> <head><title>表格</title></head> <body> <table border=1> <tr><th>学号</th><th>姓名</th></tr> <tr><td>1001</td><td>杨秀璋</td></tr> <tr><td>1002</td><td>严娜</td></tr> </table> </body> </html>
则爬取对应值的Python代码如下:
# coding=utf-8
import re
import urllib
content = urllib.urlopen("test.html").read() #打开本地文件
#获取<tr></tr>间内容
res = r'<tr>(.*?)</tr>'
texts = re.findall(res, content, re.S|re.M)
for m in texts:
print m
#获取<th></th>间内容
for m in texts:
res_th = r'<th>(.*?)</th>'
m_th = re.findall(res_th, m, re.S|re.M)
for t in m_th:
print t
#直接获取<td></td>间内容
res = r'<td>(.*?)</td><td>(.*?)</td>'
texts = re.findall(res, content, re.S|re.M)
for m in texts:
print m[0],m[1]
输出结果如下,首先获取tr之间的内容,然后再在tr之间内容中获取<th>和</th>之间值,即“学号”、“姓名”,最后讲述直接获取两个<td>之间的内容方法。
>>> <th>学号</th><th>姓名</th> <td>1001</td><td>杨秀璋</td> <td>1002</td><td>严娜</td> 学号 姓名 1001 杨秀璋 1002 严娜 >>>
2.抓取标签中的参数
(1) 抓取超链接标签的URL
HTML超链接的基本格式为“<a href=URL>链接内容</a>”,现在需要获取其中的URL链接地址,方法如下:
# coding=utf-8 import re content = ''' <a href="http://news.baidu.com" rel="external nofollow" rel="external nofollow" name="tj_trnews" class="mnav">新闻</a> <a href="http://www.hao123.com" rel="external nofollow" rel="external nofollow" name="tj_trhao123" class="mnav">hao123</a> <a href="http://map.baidu.com" rel="external nofollow" rel="external nofollow" name="tj_trmap" class="mnav">地图</a> <a href="http://v.baidu.com" rel="external nofollow" rel="external nofollow" name="tj_trvideo" class="mnav">视频</a> ''' res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')" urls = re.findall(res, content, re.I|re.S|re.M) for url in urls: print url
输出内容如下:
>>> http://news.baidu.com http://www.hao123.com http://map.baidu.com http://v.baidu.com >>>
(2) 抓取图片超链接标签的URL
HTML插入图片使用标签的基本格式为“<img src=图片地址 />”,则需要获取图片URL链接地址的方法如下:
content = '''<img alt="Python" src="http://www..csdn.net/eastmount.jpg" />'''
urls = re.findall('src="(.*?)"', content, re.I|re.S|re.M)
print urls
# ['http://www..csdn.net/eastmount.jpg']
其中图片对应的超链接为“http://www..csdn.net/eastmount.jpg”,这些资源通常存储在服务器端,最后一个“/”后面的字段即为资源的名称,该图片名称为“eastmount.jpg”。那么如何获取URL中最后一个参数呢?
(3) 获取URL中最后一个参数
通常在使用Python爬取图片过程中,会遇到图片对应的URL最后一个字段通常用于命名图片,如前面的“eastmount.jpg”,需要通过URL“/”后面的参数获取图片。
content = '''<img alt="Python" src="http://www..csdn.net/eastmount.jpg" />'''
urls = 'http://www..csdn.net/eastmount.jpg'
name = urls.split('/')[-1]
print name
# eastmount.jpg
该段代码表示采用字符“/”分割字符串,并且获取最后一个获取的值,即为图片名称。
3.字符串处理及替换
在使用正则表达式爬取网页文本时,通常需要调用find()函数找到指定的位置,再进行进一步爬取,比如获取class属性为“infobox”的表格table,再进行定位爬取。
start = content.find(r'<table class="infobox"') #起点位置 end = content.find(r'</table>') #重点点位置 infobox = text[start:end] print infobox
同时爬取过程中可能会爬取到无关变量,此时需要对无关内容进行过滤,这里推荐使用replace函数和正则表达式进行处理。比如,爬取内容如下:
# coding=utf-8 import re content = ''' <tr><td>1001</td><td>杨秀璋<br /></td></tr> <tr><td>1002</td><td>颜 娜</td></tr> <tr><td>1003</td><td><B>Python</B></td></tr> ''' res = r'<td>(.*?)</td><td>(.*?)</td>' texts = re.findall(res, content, re.S|re.M) for m in texts: print m[0],m[1]
输出如下所示:
>>> 1001 杨秀璋<br /> 1002 颜 娜 1003 <B>Python</B> >>>
此时需要过滤多余字符串,如换行(<br />)、空格( )、加粗(<B></B>)。
过滤代码如下:
# coding=utf-8
import re
content = '''
<tr><td>1001</td><td>杨秀璋<br /></td></tr>
<tr><td>1002</td><td>颜 娜</td></tr>
<tr><td>1003</td><td><B>Python</B></td></tr>
'''
res = r'<td>(.*?)</td><td>(.*?)</td>'
texts = re.findall(res, content, re.S|re.M)
for m in texts:
value0 = m[0].replace('<br />', '').replace(' ', '')
value1 = m[1].replace('<br />', '').replace(' ', '')
if '<B>' in value1:
m_value = re.findall(r'<B>(.*?)</B>', value1, re.S|re.M)
print value0, m_value[0]
else:
print value0, value1
采用replace将字符串“<br />”或“' ”替换成空白,实现过滤,而加粗(<B></B>)需要使用正则表达式过滤,输出结果如下:
>>> 1001 杨秀璋 1002 颜娜 1003 Python >>>
三.实战爬取个人博客实例
在讲述了正则表达式、常用网络数据爬取模块、正则表达式爬取数据常见方法等内容之后,我们将讲述一个简单的正则表达式爬取网站的实例。这里作者用正则表达式爬取作者的个人博客网站的简单示例,获取所需内容。
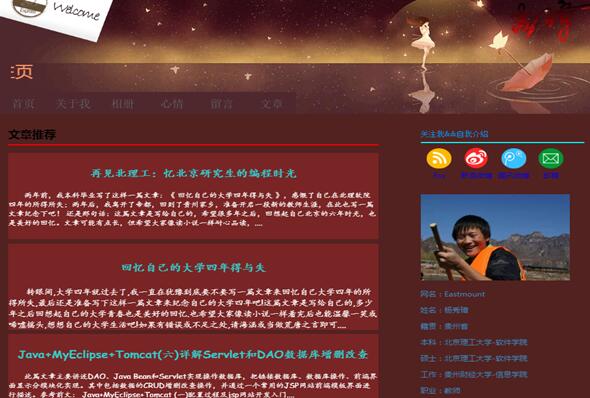
作者的个人网址“http://www.eastmountyxz.com/”打开如下图所示。
假设现在需要爬取的内容如下:
1.博客网址的标题(title)内容。
2.爬取所有图片的超链接,比如爬取<img src=”xxx.jpg” />中的“xxx.jpg”。
3.分别爬取博客首页中的四篇文章的标题、超链接及摘要内容,比如标题为“再见北理工:忆北京研究生的编程时光”。
1.分析过程
第一步 浏览器源码定位
首先通过浏览器定位这些元素源代码,发现它们之间的规律,这称为DOM树文档节点树分析,找到所需爬取节点对应的属性和属性值,如图3.6所示。
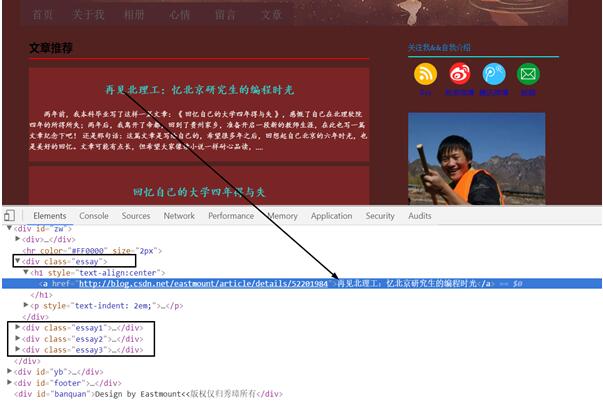
标题“再见北理工:忆北京研究生的编程时光”位于<div class=”essay”></div>节点下,它包括一个<h1></h1>记录标题,一个<p></p>记录摘要信息,即:
<div class="essay"> <h1 style="text-align:center"> <a href="http://blog.csdn.net/eastmount/.../52201984" rel="external nofollow" > 再见北理工:忆北京研究生的编程时光 </a> </h1> <p style="text-indent: 2em;"> 两年前,我本科毕业写了这样一篇文章:《 回忆自己的大学四年得与失 》,感慨了自己在北理软院四年的所得所失;两年后,我离开了帝都,回到了贵州家乡,准备开启一段新的教师生涯,在此也写一篇文章纪念下吧! 还是那句话:这篇文章是写给自己的,希望很多年之后,回想起自己北京的六年时光,也是美好的回忆。文章可能有点长,但希望大家像读小说一样耐心品读,.... </p> </div>
其余三篇文章同样为<div class=”essay1”></div>、
<div class=”essay2”></div>和<div class=”essay3”></div>。
第二步 正则表达式爬取标题
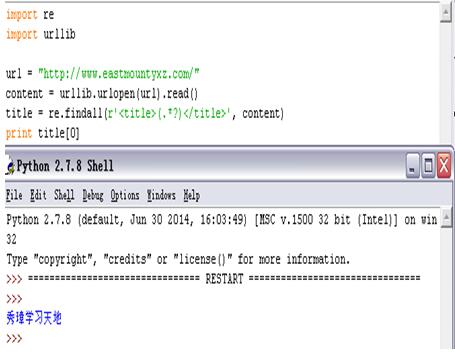
网站的标题通常位于<head><title>...</title></head>之间,爬取博客网站的标题“秀璋学习天地”的方法是通过正则表达式“<title>(.*?)</title>”实现,代码如下,首先通过urlopen()函数访问博客网址,然后定义正则表达式爬取。如下图所示:
第三步 正则表达式爬取所有图片地址
由于HTML插入图片标签格式为“<img src=图片地址 />”,则使用正则表达式获取图片URL链接地址的方法如下,获取以“src=”开头,以双引号结尾的内容即可。
import re import urllib url = "http://www.eastmountyxz.com/" content = urllib.urlopen(url).read() urls = re.findall(r'src="(.*?)"', content) for url in urls: print url
输出共显示了6张图片,但每张图片省略了博客地址“http://www.eastmountyxz.com/”,增加相关地址则可以通过浏览器访问,如“http://www.eastmountyxz.com/images/11.gif”。
第四步 正则表达式爬取博客内容
前面第一步讲述了如何定位四篇文章的标题,第一篇文章位于<div class=”essay”>和</div>标签之间,第二篇位于<div class=”essay1”>和</div>,依次类推。但是该HTML代码存在一个错误:class属性通常表示一类标签,它们的值都应该是相同的,所以这四篇文章的class属性都应该是“essay”,而name或id可以用来标识其唯一值。
这里使用find()函数定位<div class=”essay”>开头,</div>结尾,获取它们之间的值。比如获取第一篇文章的标题和超链接代码如下:
import re import urllib url = "http://www.eastmountyxz.com/" content = urllib.urlopen(url).read() start = content.find(r'<div class="essay">') end = content.find(r'<div class="essay1">') print content[start:end]
该部分代码分为三步骤:
(1) 调用urllib库的urlopen()函数打开博客地址,并读取内容赋值给content变量。
(2) 调用find()函数查找特定的内容,比如class属性为“essay”的div标签,依次定位获取开始和结束的位置。
(3) 进行下一步分析,获取源码中的超链接和标题等内容。
定位这段内容之后,再通过正则表达式获取具体内容,代码如下:
import re
import urllib
url = "http://www.eastmountyxz.com/"
content = urllib.urlopen(url).read()
start = content.find(r'<div class="essay">')
end = content.find(r'<div class="essay1">')
page = content[start:end]
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
t1 = re.findall(res, page) #超链接
print t1[0]
t2 = re.findall(r'<a .*?>(.*?)</a>', page) #标题
print t2[0]
t3 = re.findall('<p style=.*?>(.*?)</p>', page, re.M|re.S) #摘要(
print t3[0]
调用正则表达式分别获取内容,由于爬取的段落(P)存在换行内容,所以需要加入re.M和re.S支持换行查找,最后输出结果如下:
>>> http://blog.csdn.net/eastmount/article/details/52201984 再见北理工:忆北京研究生的编程时光 两年前,我本科毕业写了这样一篇文章:《 回忆自己的大学四年得与失 》,感慨了自己在北理软院四年的所得所失;两年后,我离开了帝都,回到了贵州家乡,准备开启一段新的教师生涯,在此也写一篇文章纪念下吧! 还是那句话:这篇文章是写给自己的,希望很多年之后,回想起自己北京的六年时光,也是美好的回忆。文章可能有点长,但希望大家像读小说一样耐心品读,.... >>>
2.代码实现
完整代码参考test03_10.py文件,代码如下所示。
#coding:utf-8
import re
import urllib
url = "http://www.eastmountyxz.com/"
content = urllib.urlopen(url).read()
#爬取标题
title = re.findall(r'<title>(.*?)</title>', content)
print title[0]
#爬取图片地址
urls = re.findall(r'src="(.*?)"', content)
for url in urls:
print url
#爬取内容
start = content.find(r'<div class="essay">')
end = content.find(r'<div class="essay1">')
page = content[start:end]
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
t1 = re.findall(res, page) #超链接
print t1[0]
t2 = re.findall(r'<a .*?>(.*?)</a>', page) #标题
print t2[0]
t3 = re.findall('<p style=.*?>(.*?)</p>', page, re.M|re.S) #摘要(
print t3[0]
print ''
start = content.find(r'<div class="essay1">')
end = content.find(r'<div class="essay2">')
page = content[start:end]
res = r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')"
t1 = re.findall(res, page) #超链接
print t1[0]
t2 = re.findall(r'<a .*?>(.*?)</a>', page) #标题
print t2[0]
t3 = re.findall('<p style=.*?>(.*?)</p>', page, re.M|re.S) #摘要(
print t3[0]
输出结果如图所示。

通过上面的代码,读者会发现使用正则表达式爬取网站还是比较繁琐,尤其是定位网页节点时,后面将讲述Python提供的常用第三方扩展包,利用这些包的函数进行定向爬取。
希望这篇文字对你有所帮助,尤其是刚接触爬虫的同学或是遇到类似问题的同学,更推荐大家使用BeautifulSoup、Selenium、Scrapy等库来爬取数据。
以上这篇python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python里使用正则的findall函数的实例详解
python里使用正则的findall函数的实例详解 在前面学习了正则的search()函数,这个函数可以找到一个匹配的字符串返回,但是想找到所有匹配的字符串返回,怎么办呢?其实得使用findall()函数.如下例子: #python 3. 6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re text = 'abbaaabbbbaaaaa' pattern = 'ab' for match in r
-
python里使用正则表达式的组嵌套实例详解
python里使用正则表达式的组嵌套实例详解 由于组本身是一个完整的正则表达式,所以可以将组嵌套在其他组中,以构建更复杂的表达式.下面的例子,就是进行组嵌套的例子: #python 3.6 #蔡军生 #http://blog.csdn.net/caimouse/article/details/51749579 # import re def test_patterns(text, patterns): """Given source text and a list of pa
-
详解python里使用正则表达式的分组命名方式
详解python里使用正则表达式的分组命名方式 分组匹配的模式,可以通过groups()来全部访问匹配的元组,也可以通过group()函数来按分组方式来访问,但是这里只能通过数字索引来访问,如果某一天产品经理需要修改需求,让你在它们之中添加一个分组,这样一来,就会导致匹配的数组的索引的变化,作为开发人员的你,必须得一行一行代码地修改.因此聪明的开发人员又想到一个好方法,把这些分组进行命名,只需要对名称进行访问分组,不通过索引来访问了,就可以避免这个问题.那么怎么样来命名呢?可以采用(?P<nam
-
python中如何使用正则表达式的集合字符示例
前言 本文主要给大家介绍了关于python使用正则表达式的集合字符的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 在正则表达式里,想匹配一些字符中的一个,也就是说给出一个字符的集合,只要出现这个集合里任意的字符,都是成立的.比如[ab],就是将匹配任意出现a或b的字符.比如a[ab]+,它是贪婪模式,将会匹配所有是a后面的a或b的字符串,如abbaabbba.如果要改为非贪婪模式,要在后面添加?,如下面的例子: 示例代码 #python 3.6 #蔡军生 #http
-
python利用正则表达式排除集合中字符的功能示例
前言 我们在之前学习过通过集合枚举的功能,把所有需要出现的字符列出来,保存在集合里面,这样正则表达式就可以根据集合里的字符是否存在来判断是否匹配成功,如果在集合里,就匹配成功,否则不成功.现在有一个问题,就是要把集合里列出的字符都不能出现才匹配成功,这个需求怎么样实现呢?其实比较简单,只需要在集合前面添加一个字符^,就让正则表达式匹配时,发现有字符在集合里就匹配不成功.下面话不多说了,来一起看看详细的介绍吧. 例子如下: #python 3.6 #蔡军生 #http://blog.csdn.ne
-

python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
Python爬虫入门教程01之爬取豆瓣Top电影
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理 基本开发环境 Python 3.6 Pycharm 相关模块的使用 requests parsel csv 安装Python并添加到环境变量,pip安装需要的相关模块即可. 爬虫基本思路 一.明确需求 爬取豆瓣Top250排行电影信息 电影名字 导演.主演 年份.国家.类型 评分.评价人数 电影简介 二.发送请求 Python中的大量开源的模块使得编码变的特别简单,我们写爬虫第一个要了解的模
-
Python爬虫实战之虎牙视频爬取附源码
目录 知识点 开发环境 分析目标url 开始代码 最开始还是线导入所需模块 数据请求 获取视频标题以及url地址 获取视频id 保存数据 调用函数 运行代码,得到数据 知识点 爬虫基本流程 re正则表达式简单使用 requests json数据解析方法 视频数据保存 开发环境 Python 3.8 Pycharm 爬虫基本思路流程: (重点) [无论任何网站 任何数据内容 都是按照这个流程去分析] 1.确定需求 (爬取的内容是什么东西?) 都通过开发者工具进行抓包分析 分析视频播放url地址 是
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
Python爬虫实战之使用Scrapy爬取豆瓣图片
使用Scrapy爬取豆瓣某影星的所有个人图片 以莫妮卡·贝鲁奇为例 1.首先我们在命令行进入到我们要创建的目录,输入 scrapy startproject banciyuan 创建scrapy项目 创建的项目结构如下 2.为了方便使用pycharm执行scrapy项目,新建main.py from scrapy import cmdline cmdline.execute("scrapy crawl banciyuan".split()) 再edit configuration 然后
-
Python爬虫实战之用selenium爬取某旅游网站
一.selenium实战 这里我们只会用到很少的selenium语法,我这里就不补充别的用法了,以实战为目的 二.打开艺龙网 可以直接点击这里进入:艺龙网 这里是主页 三.精确目标 我们的目标是,鹤壁市,所以我们应该先点击搜索框,然后把北京删掉,替换成鹤壁市,那么怎么通过selenium实现呢? 打开pycharm,新建一个叫做艺龙网的py文件,先导包: from selenium import webdriver import time # 导包 driver = webdriver.Chro
-
如何使用python爬取csdn博客访问量
最近学习了python和爬虫,想写一个程序练练手,所以我就想到了大家都比较关心的自己的博客访问量,使用python来获取自己博客的访问量,这也是后边我将要进行的项目的一部分,后边我会对博客的访问量进行分析,以折线图和饼图等可视化的方式展示自己博客被访问的情况,使自己能更加清楚自己的哪些博客更受关注,博客专家请勿喷,因为我不是专家,我听他们说专家本身就有这个功能. 一.网址分析 进入自己的博客页面,网址为:http://blog.csdn.net/xingjiarong 网址还是非常清晰的就是cs
-
基于Python爬取51cto博客页面信息过程解析
介绍 提到爬虫,互联网的朋友应该都不陌生,现在使用Python爬取网站数据是非常常见的手段,好多朋友都是爬取豆瓣信息为案例,我不想重复,就使用了爬取51cto博客网站信息为案例,这里以我的博客页面为教程,编写的Python代码! 实验环境 1.安装Python 3.7 2.安装requests, bs4模块 实验步骤 1.安装Python3.7环境 2.安装requests,bs4 模块 打开cmd,输入:pip install requests -i https://pypi.tuna.tsi
-
python scrapy拆解查看Spider类爬取优设网极细讲解
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: import scrapy class UiSpider(scrapy.Spider): name = 'ui' allowed_domains = ['www.uisdc.com'] start_urls =