ShardingJdbc读写分离的BUG踩坑解决
目录
- 前言
- 数据库介绍
- 1. 常规写完读
- 2. 在一个 service 里面调用另一个 service
- 3. 新开一个线程去调用 service2
- 4. service2 新开一个事务执行
前言
最近公司准备接入ShardingJdbc做读写分离了,老大让我们理一理有没有写完数据立马读的场景,因为主从同步是有延迟的,如果写完读取数据走到从库,而从库正好有延迟,没读取到数据,岂不是造成了生产事故。
今天我们来看看,ShardingJdbc作为一个成熟的框架是怎么处理写完数据立即读取的场景的。
数据库介绍
我本地使用了两个库来做实验,写库(ds_0_master)和读库(ds_0_salve),两个库并没有配置主从,但也不影响实验操作。
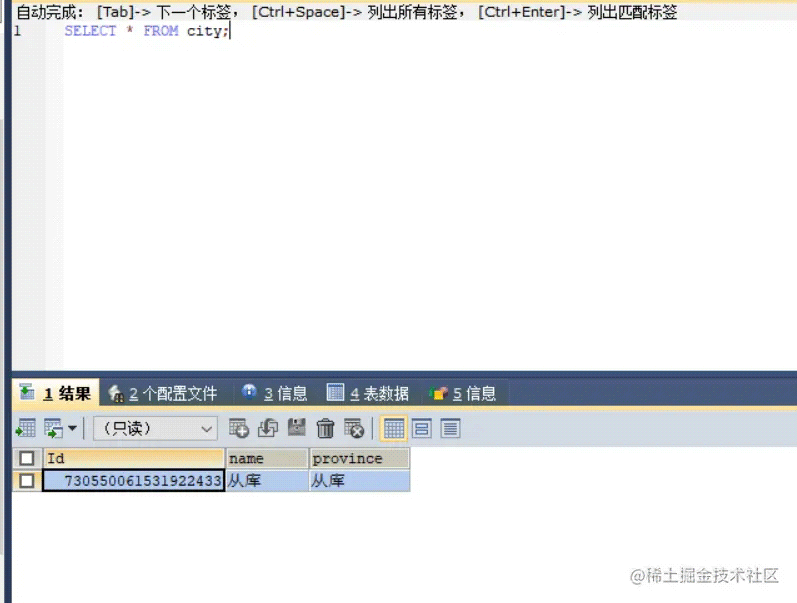
库里有一个city 表。主库的 city 表没有数据,而从库的 city 表就一条数据。数据内容如下:
我们讨论 4 种业务场景:
- 常规写完读
- 在一个 service 里面调用另一个 service2 进行读
- 在一个 service 里面新开一个线程去调用 service2
- 在一个 service 里面调用 service2,但 service2 是新开的事务
先直接上实验结果:
1. 常规写完读
@Service
public class CityService {
@Autowired
private CityRepository cityRepository;
@Autowired
private CityService2 cityService2;
@Transactional(rollbackFor = Exception.class)
public void test(){
City city=new City();
city.setName("眉山");
city.setProvince("四川");
cityRepository.save(city);
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.out.println("cityService:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
打印结果:
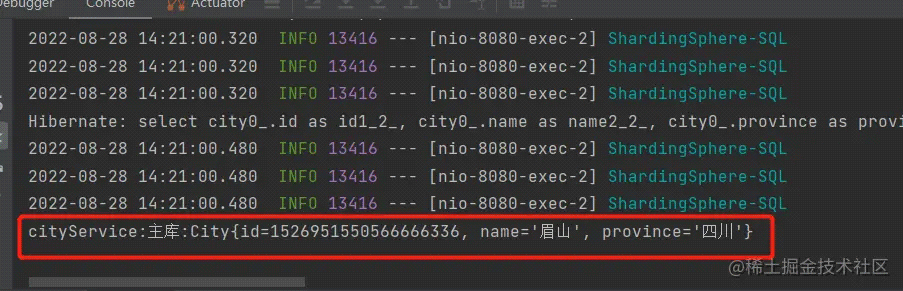
实验分析: 我们对 city 表进行插入后,紧接着对 city 表进行了查询,查出的内容是我们刚刚插入的内容。说明查询操作没有走读库,而是走了主库。
2. 在一个 service 里面调用另一个 service
代码如下:
@Transactional(rollbackFor = Exception.class)
public void test(){
City city=new City();
city.setName("眉山");
city.setProvince("四川");
cityRepository.save(city);
//调用其他service
cityService2.test();
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.out.println("cityService:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
service2 的代码:
public void test(){
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
打印结果:
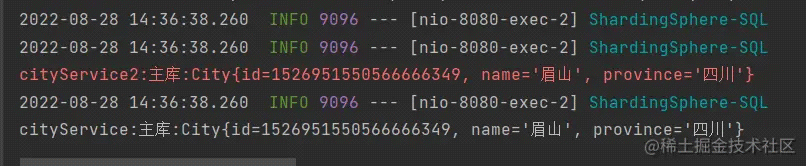
实验分析:在 service 方法里调用了其他 service,其他 service 也会受到影响。service2 也是走的主库。
3. 新开一个线程去调用 service2
代码如下:
@Service
public class CityService {
@Autowired
private CityRepository cityRepository;
@Autowired
private CityService2 cityService2;
@Transactional(rollbackFor = Exception.class)
public void test(){
City city=new City();
city.setName("眉山");
city.setProvince("四川");
cityRepository.save(city);
new Thread(()->{cityService2.test();}).start();
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.out.println("cityService:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
@Service
public class CityService2 {
@Autowired
private CityRepository cityRepository;
public void test(){
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
}
打印结果:
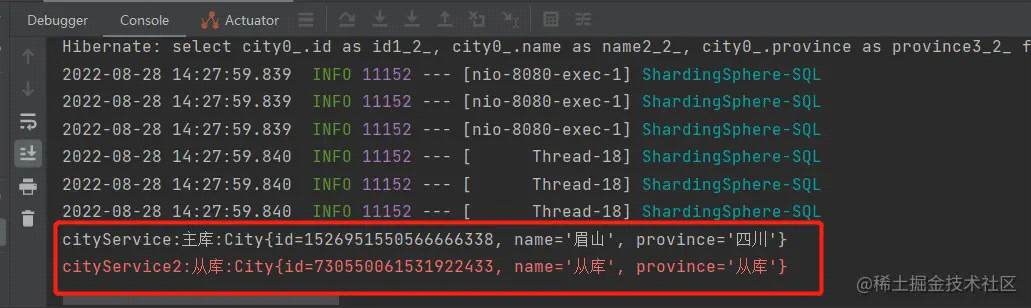
实验分析: 我们新开了线程对 city 表进行查询,此次查询读的是从库。新开的线程会走从库,我猜想是新开的线程它认为是没有写入/修改操作,所以走了从库。
我又改动了 service2,加了一段写入操作。代码如下:
public void test(){
City city=new City();
city.setName("成都");
city.setProvince("四川");
cityRepository.save(city);
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
再次执行,结果如下:
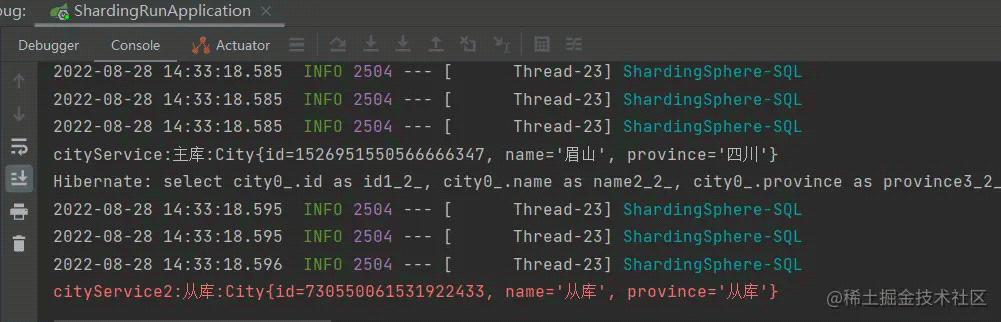
和预想的不一样,依旧是走的从库。
4. service2 新开一个事务执行
我们调整 service2 的事务传播行为级别。代码如下:
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void test(){
List<City> all = cityRepository.findAll();
all.forEach(x->{
System.err.println("cityService2:"+((x.getProvince().equals("四川"))?"主库":"从库")+":"+x);
});
}
REQUIRES_NEW 的含义是:
强制自己开启一个新的事务,如果一个事务已经存在,那么将这个事务挂起.如 ServiceA.methodA()调用 ServiceB.methodB(),methodB()上的传播级别是 PROPAGATION_REQUIRES_NEW 的话,那么如果 methodA 报错,不影响 methodB 的事务,如果 methodB 报错,那么 methodA 是可以选择是回滚或者提交的,就看你是否将 methodB 报的错误抛出还是 try catch 了.
打印结果:
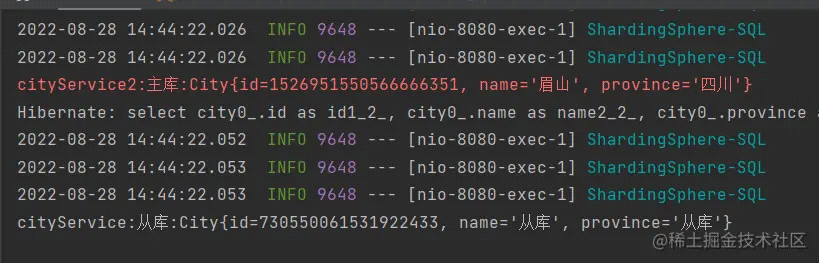
实验分析: 这个结果确实是没想到,service2 新开了个事务走的是主库,而 service 里面的同一个事务里的写后读,反而走了从库。
实验总结:
| 场景 | service | service2 |
|---|---|---|
| 同一个 service 里写完读 | 主库 | 主库 |
| service 里写完调用另一个 servcie 进行读操作 | 主库 | 主库 |
| service 里写完新开线程调用另一个 servcie 进行读操作 | 主库 | 从库 |
| service 里写完新开一个事务调用另一个 servcie 进行读操作 | 从库 | 主库 |
常规的写完读操作和写完在另一个 service 里进行读操作,都能够走到主库,保证了常规业务的正确性,也满足了我们一般的使用场景了。而新开线程进行读操作的情况其实比较少,如果非要使用,我们可以用强制指定主库的方式进行处理。
最后一种情况,service中调用另一个service2(新开事务),原本 service 里同一个事务的写完读操作走到了从库,一不注意容易引起实际业务bug,需要使用者谨慎使用。大家觉得这是不是ShardingJdbc的一个BUG呢?
以上就是ShardingJdbc读写分离的BUG踩坑解决的详细内容,更多关于ShardingJdbc读写分离BUG的资料请关注我们其它相关文章!
相关推荐
-

SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
Sharding-JDBC自动实现MySQL读写分离的示例代码
目录 一.ShardingSphere和Sharding-JDBC概述 1.1.ShardingSphere简介 1.2.Sharding-JDBC简介 1.3.Sharding-JDBC作用 1.4.ShardingSphere规划线路图 1.5.ShardingSphere三种产品的区别 二.数据库中间件 2.1.数据库中间件简介 2.2.Sharding-JDBC和MyCat区别 三.Sharding-JDBC+MyBatisPlus实现读写分离 3.0.项目代码结构和建表SQL语句 3.
-
Sharding JDBC读写分离实现原理及实例
一.核心功能和不支持项 核心功能 提供一主多从的读写分离配置,可独立使用,也可配合分库分表使用. 独立使用读写分离支持SQL透传. 同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性. 基于Hint的强制主库路由. 不支持项 主库和从库的数据同步(所以需要另外实现主从同步,如使用Mysql的binlog实现). 主库和从库的数据同步延迟导致的数据不一致. 主库双写或多写. 跨主库和从库之间的事务的数据不一致.主从模型中,事务中读写均用主库. #涉及到的库及表
-
Java ShardingJDBC实战演练
目录 一.背景 二.优化事项 三.具体实战 四.遇到的问题 五.项目源码地址 一.背景 最近在公司手头上的项目单表达到了五千万的规模,而且日增长量每天就有10w左右,一个月就有大概300w的数据,这样一直下去过几个月以后表的数据很容易就上亿了,这样不利于管理以及在大表的情况下,对于表的DDL效率也会相对下降,和几个同事商量了下,于是乎开始做分表的技术优化. 二.优化事项 (1)首先先确定使用场景,当前表的使用场景更多的是根据一个具体的标识值去查询,范围查询的场景频率相对低下,在这这种情况下考虑想
-
SpringBoot使用Sharding-JDBC实现数据分片和读写分离的方法
目录 一.Sharding-JDBC简介 二.具体的实现方式 1.maven引用 2.数据库准备 3.Spring配置 4.精准分片算法和范围分片算法的Java代码 5.测试 一.Sharding-JDBC简介 Sharding-JDBC是Sharding-Sphere的一个产品,它有三个产品,分别是Sharding-JDBC.Sharding-Proxy和Sharding-Sidecar,这三个产品提供了标准化的数据分片.读写分离.柔性事务和数据治理功能.我们这里用的是Sharding-JDB
-
springboot整合shardingjdbc实现分库分表最简单demo
一.概览 1.1 简介 ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务. 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC. 支持任何第三方的数据库连接池,如:DBCP,
-
ShardingJdbc读写分离的BUG踩坑解决
目录 前言 数据库介绍 1. 常规写完读 2. 在一个 service 里面调用另一个 service 3. 新开一个线程去调用 service2 4. service2 新开一个事务执行 前言 最近公司准备接入ShardingJdbc做读写分离了,老大让我们理一理有没有写完数据立马读的场景,因为主从同步是有延迟的,如果写完读取数据走到从库,而从库正好有延迟,没读取到数据,岂不是造成了生产事故. 今天我们来看看,ShardingJdbc作为一个成熟的框架是怎么处理写完数据立即读取的场景的. 数据
-
Keras构建神经网络踩坑(解决model.predict预测值全为0.0的问题)
终于构建出了第一个神经网络,Keras真的很方便. 之前不知道Keras这么方便,在构建神经网络的过程中绕了很多弯路,最开始学的TensorFlow,后来才知道Keras. TensorFlow和Keras的关系,就像c语言和python的关系,所以Keras是真的好用. 搞不清楚数据的标准化和归一化的关系,想对原始数据做归一化,却误把数据做了标准化,导致用model.predict预测出来的值全是0.0,在网上搜了好久但是没搜到答案,后来自己又把程序读了一遍,突然灵光一现好像是数据归一化出了问
-
SpringBoot多数据源读写分离的自定义配置问题及解决方法
目录 针对device库我们先创建一个数据库连接配置类 在类中添加配置文件中的读写数据源 创建返回SqlSessionFactory的Bean 创建SqlSessionTemplate的Bean 创建DataSourceTransactionManager 事务管理器 最后 在开发中我们有可能会遇到一个项目需要配置多个数据源,或者需要读写分离的配置,在启动类上贴上@MapperScan注解指定扫描对应的mapper.xml文件肯迪那个是无法满足了.我们可以通过自定义配置数据库配置类来解决这个问题
-
iOS schem与Universal Link 调试时踩坑解决记录
目录 简介 AppDelegate和SceneDelegate 问题:在iOS13以上冷启动的时候不会走代理函数! 如果你用了Scheme方式: iOS13之前会走这个代理函数 iOS13之后会走 如果你用了Universal Link方式: iOS13之前会走这个代理函数 iOS13之后会走 总结 简介 scheme和Universal Link是在iOS中两种可以在网页中点击回跳到自己预定的APP的两种方式.至于这两种方式需要怎么配置,这里就不做详细的介绍了.网上的文章一搜一大堆.今天主要是
-
详解Spring Boot中整合Sharding-JDBC读写分离示例
在我<Spring Cloud微服务-全栈技术与案例解析>书中,第18章节分库分表解决方案里有对Sharding-JDBC的使用进行详细的讲解. 之前是通过XML方式来配置数据源,读写分离策略,分库分表策略等,之前有朋友也问过我,有没有Spring Boot的方式来配置,既然已经用Spring Boot还用XML来配置感觉有点不协调. 其实吧我个人觉得只要能用,方便看,看的懂就行了,mybatis的SQL不也是写在XML中嘛. 今天就给大家介绍下Spring Boot方式的使用,主要讲解读写分
-
Storybook 7.0 Beta Vue3踩坑解决记录
目录 故事背景 坑一: 坑二: 坑三: 总结 故事背景 基于 Vue + Vite + TS 结合 pnpm 的一个 monorepo 项目的组件库文档编写,起初个人是比较倾向于直接使用全家桶系列的 VitePress.无奈公司中其他库文档均使用 Storybook,并且已经升级到最新版本. 好吧,到这里就基本知道了自己要做什么了. 由于之前也没有接触过这个玩意儿,就去看着官网一步步操作去了.坑也就在这里了,谁知道版本上去了,文档却没有做出相应的调整.然后就有了后续一系列的问题.Storyboo
-
使用Pyinstaller的最新踩坑实战记录
前言 将py编译成可执行文件需要使用PyInstaller,之前给大家介绍了关于利用PyInstaller将python程序.py转为.exe的方法,在开始本文之前推荐大家可以先看下这篇文章,本文主要给大家介绍了Pyinstaller最新踩坑实战记录,现在网上关于pyinstaller的问题充斥着各种copy过来copy过去的答案,这大概就是各种无脑博客爬虫站最让人讨厌的地方. 而且这方面的问题,stackoverflow也是回答的千奇百怪. 强烈推荐官方文档 http://pythonhost
-
解决MySQL读写分离导致insert后select不到数据的问题
MySQL设置独写分离,在代码中按照如下写法,可能会出现问题 // 先录入 this.insert(obj); // 再查询 Object res = this.selectById(obj.getId()); res: null; 线上的一个坑,做了读写分离以后,有一个场景因为想方法复用,只传入一个ID就好,直接去库里查出一个对象再做后续处理,结果查不出来,事务隔离级别各种也都排查了,最后发现是读写分离的问题,所以换个思路去实现吧. 补充知识:MySQL INSERT插入条件判断:如果不存在则
-
No module named ‘win32gui‘ 的解决方法(踩坑之旅)
在此把踩过的坑记录下来,我失败的方式,你们可能成功,我成功的方法,你们可能失败.这些包啊库啊的,经验也就是这样了.也许换个时间再执行一次,莫名其妙的可能就成了.bug就是这么奇妙,跟人生一样.说不出来原因,也许有一天我能成为大佬,再回来补上吧. 问题:ModuleNotFoundError: No module named 'win32gui' round 1.pycharm中settings,失败 round 2.pycharm中的Terminal执行pip install pypiwin32