深入了解Rust中泛型的使用
目录
- 楔子
- 函数中的泛型
- 结构体中的泛型
- 枚举中的泛型
- 方法中的泛型
楔子
所有的编程语言都致力于将重复的任务简单化,并为此提供各种各样的工具。在 Rust 中,泛型(generics)就是这样一种工具,它是具体类型或其它属性的抽象替代。在编写代码时,我们可以直接描述泛型的行为,以及与其它泛型产生的联系,而无须知晓它在编译和运行代码时采用的具体类型。
总结一下泛型就是,提高代码的复用能力,处理重复代码。泛型是具体类型或者其它属性的抽象代替,编写的泛型代码不是最终的代码,而是一些模板,里面有一些占位符,编译器在编译的时候会将占位符替换为具体的类型。
函数中的泛型
函数中定义泛型的时候,我们需要将泛型定义在函数的签名中:
// 这种定义方式是错误的,因为 T 不在作用域中
// 我们要将其放在签名里面
fn func(arg: T) -> T {
arg
}
// 这样做是正确的
fn func<T>(arg: T) -> T {
arg
}
里面的 T 就是一个泛型,它可以代表任意的类型,然后在编译的时候会将其替换成具体的类型,这个过程叫做单态化。
另外这个 T 就是一个占位符,你换成别的也可以,只是我们一般写作 T。
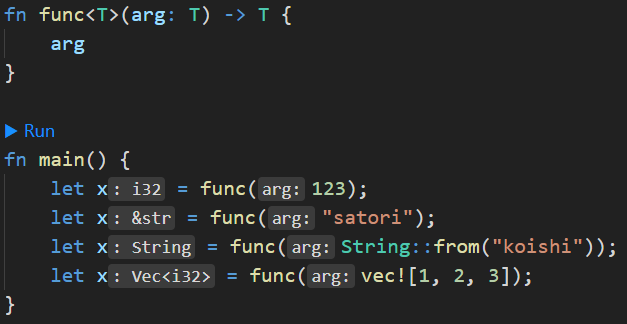
这里我们连续声明了多个变量 x,这在 Rust 里面是没有问题的,因为 Rust 有一个变量隐藏机制。然后再来看一下变量 x 的类型,虽然泛型 T 可以代表任意类型,但 Rust 在编译的时候会执行单态化,确定泛型的具体类型。
比如传一个 123,那么 T 就会被标记为 i32,因此返回的也是 i32,至于其它类型同理。还是那句话,T 只是一个占位符,至于它到底代表什么类型,取决于我们调用时传递的值是什么类型。
比如传递一个 &str,那么函数就会被 Rust 替换成如下:
fn func(arg: &str) -> &str {
arg
}
以上过程被称为单态化,Rust 在编译期间会将泛型 T 替换成具体的类型。因此如果想使用泛型,那么函数签名中的泛型一定要出现在函数参数中,然后根据调用方传递的值的类型,来确定泛型。
总结一下:泛型一定要在函数的签名中,也就是在函数后面通过 <> 进行指定,否则的话泛型是无法使用的。此外,泛型还要出现在参数中,这是毫无疑问的,不然定义泛型干啥。
当然啦,泛型不止可以定义一个,定义任意个都是可以的。
// 如果有多个泛型,那么在 <> 里面通过逗号分隔
// 然后要保证函数签名 <> 里面声明的泛型,
// 都要在函数参数中出现,也就是要将定义的泛型全用上
fn func<A, B, C>(
arg1: A, arg2: B, arg3: C
) -> (C, A) {
(arg3, arg1)
}
fn main() {
// 函数 func 定义了三个泛型,然后返回的类型是 (C, A)
// 这里传递三个参数,显然当调用时,Rust 会确定泛型代表的类型
// A 是 i32,B 是 f64,C 是 &str
let x = func(123, 3.14, "你好");
// 泛型可以接收任何类型,那么当调用时
// A 是 Vec<i32>,B 是 [i32;2],C 是 (i32, i32)
let y = func(vec![1, 2], [1, 2], (3, 4));
}
这里我们定义了三个泛型,然后返回的类型是 (C, A)。而 Rust 会根据参数的类型,来确定泛型,所以变量 x 是 (&str, i32) 类型,变量 y 是 ((i32, i32), Vec<i32>) 类型。
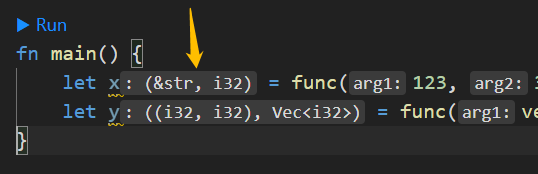
事实上 IDE 也已经推断出来了,总的来说泛型应该不难理解。
结构体中的泛型
如果一个结构体成员的类型不确定,那么也可以定义为泛型。
struct Point<T> {
x: T,
y: T
}
和函数一样,泛型一定要写在 <> 当中作为签名出现,然后才可以使用,相当于告诉 Rust 都定义了哪些泛型。然后签名中的泛型,一定要全部使用,会根据函数调用时给参数传的值、或者实例化结构体时给成员传的值,来确定泛型代表哪一种类型。
如果签名中的泛型没有全部使用,那么 Rust 就无法执行单态化,于是报错。所以泛型一定要全部使用,再说了,不使用的话,定义它干嘛。
struct Point<T> {
x: T,
y: T
}
fn main() {
let p1 = Point{x: 11, y: 22};
let p2 = Point{x: 11.1, y: 22.2};
}
T 只是一个占位符,具体什么类型要由我们传递的内容决定,可以是 i32,可以是 f64。但由于成员 x 和 y 的类型都是 T,所以它们的类型一定是一样的,要是 i32 则都是 i32,要是 f64 则都是 f64。
如果希望类型不同,那么只需要两个泛型即可。
struct Point<T, U> {
x: T,
y: U
}
fn main() {
// x 和 y 的类型可以相同,也可以不同
// 因为它们都可以接收任意类型
let p1 = Point{x: 11, y: 22};
let p2 = Point{x: 11.1, y: 22.2};
let p3 = Point{x: "11.1", y: String::from("satori")};
let p3 = Point{x: vec![1, 2, 3], y: (1, 2, 3)};
}
还是那句话,泛型可以接收任意类型,想传啥都行,具体根据我们传递的值来确定。
枚举中的泛型
枚举也是支持泛型的,比如之前使用的 Option<T> 就是一种泛型,它的结构如下:
enum Option<T> {
Some(T),
None
}
里面的 T 可以代表任意类型,然后我们再来自定义一个枚举。
// 签名中的泛型参数必须都要使用
// 比如函数签名的泛型,要全部体现在参数中
// 枚举和结构体签名的泛型,要全部体现在成员中
enum MyOption<A, B, C> {
// 这里 A、B、C 都是我们随便定义的,可以代指任意类型
// 具体是哪种类型,则看我们传递了什么
Some1(A),
Some2(B),
Some3(C),
}
fn main() {
// 泛型不影响效率,是因为 Rust 要进行单态化
// 所以泛型究竟代表哪一种类型要提前确定好
// 这里必须要显式指定 x 的类型。枚举和结构体不同
// 结构体每个成员都要赋值,所以 Rust 能够基于赋的值推断出所有的泛型
// 但枚举的话,每次只会用到里面的一个成员
// 如果还有其它泛型,那么 Rust 就无法推断了
// 比如这里只能推断出泛型 C 代表的类型,而 A 和 B 就无法推断了
// 因此每个泛型代表什么类型,需要我们手动指定好
let x: MyOption<i32, f64, u8> = MyOption::Some3(123);
match x {
MyOption::Some1(v) => println!("我是 i32"),
MyOption::Some2(v) => println!("我是 f64"),
MyOption::Some3(v) => println!("我是 u8"),
}
// 泛型可以代表任意类型,指定啥都是可以的
let y: MyOption<u8, i32, String> =
MyOption::Some3(String::from("xxx"));
match y {
MyOption::Some1(v) => println!("我是 u8"),
MyOption::Some2(v) => println!("我是 i32"),
MyOption::Some3(v) => println!("我是 String"),
}
/*
我是 u8
我是 String
*/
}
如果觉得上面的例子不好理解的话,那么再举个简单的例子:
enum MyOption<T> {
MySome1(T),
MySome2(i32),
MySome3(T),
MyNone
}
fn main() {
// 这里我们没有指定 x 的类型
// 这是因为 MyOption 只有一个泛型
// 通过给 MySome1 传递的值,可以推断出 T 的类型
let x = MyOption::MySome1(123);
// 同样的道理,Rust 可以自动推断,得出 T 是 &str
let x = MyOption::MySome3("123");
// 但此处就无法自动推断了,因为赋值的是 MySome2 成员
// 此时 Rust 获取不到任何有关 T 的信息,无法执行推断
// 因此我们需要手动指定类型,但仔细观察一下声明
// 首先,如果没有泛型的话,那么直接 let x: MyOption = ... 即可
// 但里面有泛型,所以此时除了类型之外,还要连同泛型一起指定
// 也就是 MyOption<f64>
let x: MyOption<f64> = MyOption::MySome2(123);
// 当然泛型可以代表任意类型,此时的 T 则是一个 Vec<i32> 类型
let x: MyOption<Vec<i32>> = MyOption::MySome2(123);
}
所以一定要注意:在声明变量的时候,如果 Rust 不能根据我们赋的值推断出泛型代表的类型,那么我们必须要手动声明类型,来告诉 Rust 泛型的相关信息,这样才可以执行单态化。
对于结构体也是同样的道理:
struct Girl1 {
field: i32,
}
struct Girl2<T> {
field: T,
}
fn main() {
// 下面两个语句类似,只是第二次声明 g1 的时候多指定了类型
let g1 = Girl1 { field: 123 };
let g1: Girl1 = Girl1 { field: 123 };
// 下面两条语句也是类似的,第二次声明 g2 的时候多指定了类型
// 但此时的类型有些不一样,Girl2 的结尾多了一个 <i32>
// 原因很简单,因为 Girl2 里面有泛型
// 所以在显式指定类型的时候,还要将泛型代表的类型一块指定,否则报错
let g2 = Girl2 { field: 123 };
let g2: Girl2<i32> = Girl2 { field: 123 };
}
然后还有一点比较重要,就是在声明的时候,只需在 <> 里面指定泛型即可,什么意思呢?举个例子:
struct Girl<E, T, W> {
field1: String,
field2: T,
field3: W,
field4: E,
field5: i32,
}
fn main() {
// 这里可以不指定类型,因为 Rust 可以推断出来
// 不过这里我们就显式指定。而虽然 Girl 有 5 个成员
// 但泛型的数量是三个,因此声明变量的时候也要指定三个
// 由于定义结构体的时候,泛型顺序是 E T W
// 所以这里的 f64 就是 E,u8 就是 T,Vec<i32> 就是 W
let g: Girl<f64, u8, Vec<i32>> = Girl {
field1: String::from("hello"),
field2: 123u8,
field3: vec![1, 2, 3],
field4: 3.14,
field5: 666,
};
}
以上就是在枚举中使用泛型,并且针对泛型的用法稍微多啰嗦了一些。
方法中的泛型
我们也可以对方法实现泛型,举个例子:
struct Point<T, U> {
x: T,
y: U
}
// 针对 i32、f64 实现的方法
// 只有传递的 T、U 对应 i32、f64 才可以调用
impl Point<i32, f64> {
fn m1(&self) {
println!("我是 m1 方法")
}
}
fn main() {
let p1 = Point{x: 123, y: 3.14};
p1.m1(); // 我是 m1 方法
let p2 = Point{x: 3.14, y: 123};
//p2.m1();
//调用失败,因为 T 和 U 不是 i32、f64,而是 f64、i32
//所以 p2 无法调用 m1 方法
}
可能有人好奇了,声明方法的时候不考虑泛型可不可以,也就是 impl Point {}。答案是不可以,如果结构体中有泛型,那么声明方法的时候必须指定。但这就产生了一个问题,那就是只有指定类型的结构体才能调用方法。
比如上述代码,只有当 x 和 y 分别为 i32、f64 时,才可以调用方法,如果我希望所有的结构体实例都可以调用呢?
struct Point<T, U> {
x: T,
y: U
}
// 针对 K、f64 实现的方法,由于 K 是一个泛型
// 所以它可以代表任何类型(泛型只是一个符号)
// 因此不管 T 最终是什么类型,i32 也好、&str 也罢
// K 都可以接收,只要 U 是 f64 即可
// 然后注意:如果声明方法时结构体后面指定了泛型
// 那么必须将使用的泛型在 impl 后面声明
impl <K> Point<K, f64> {
fn m1(&self) {
println!("我是 m1 方法")
}
}
// 此时 K 和 S 都是泛型,那么此时对结构体就没有要求了
// 因为不管 T 和 W 代表什么,K 和 S 都能表示,因为它们都是泛型
impl <K, S> Point<K, S> {
fn m2(&self) {
println!("我是 m2 方法")
}
}
// 这里我们没有使用泛型,所以也就无需在 impl 后面声明
// 但很明显,此时结构体实例如果想调用 m3 方法
// 那么必须满足 T 是 u8,W 是 f64
impl Point<u8, f64> {
fn m3(&self) {
println!("我是 m3 方法")
}
}
fn main() {
// 显然 p1 可以同时调用 m1 和 m2 方法,但 m3 不行
// 因为 m3 要求 T 是一个 u8,而当前是 &str
let p1 = Point{x: "hello", y: 3.14};
p1.m1(); // 我是 m1 方法
p1.m2(); // 我是 m2 方法
// 显然 p2 可以同时调用 m1、m2、m3
// 另外这里的 x 可以直接写成 123,无需在结尾加上 u8
// 因为 Rust 看到我们调用了 m3 方法,会自动推断为 u8
let p2 = Point{x: 123u8, y: 3.14};
p2.m1(); // 我是 m1 方法
p2.m2(); // 我是 m2 方法
p2.m3(); // 我是 m3 方法
// 显然 p3 只能调用 m2 方法,因为 m2 对 T 和 W 没有要求
// 但是像 m3 就不能调用,因为它是为 <u8, f64> 实现的方法
// 只有当 T、W 为 u8、f64 时才可以调用
// 显然此时是不满足的,因为都是 &str,至于 m1 方法也是同理
// 所以 p3 只能调用 m2,这个方法是为 <K, S> 实现的
// 而 K 和 S 也是泛型,可以代表任意类型,因此没问题
let p3 = Point{x: "3.14", y: "123"};
p3.m2(); // 我是 m2 方法
}
然后注意:我们上面的泛型本质上针对的还是结构体,而我们定义方法的时候也可以指定泛型,其语法和在函数中定义泛型是一样的。
#[derive(Debug)]
struct Point<T, U> {
x: T,
y: U,
}
// 使用 impl 时 Point 后面的泛型名称可以任意
// 比如我们之前起名为 K 和 S,但这样容易乱,因为字母太多了
// 所以建议:使用 impl 时的泛型和定义结构体时的泛型保持一致即可
impl<T, U> Point<T, U> {
// 方法类似于函数,它是一个独立的个体,可以有自己独立的泛型
// 然后返回值,因为 Point 里面是泛型,可以代表任意类型
// 那么自然也可以是其它的泛型
fn m1<V, W>(self, a: V, b: W) -> Point<U, W> {
// 所以返回值的成员 x 的类型是 U,那么它应该来自于 self.y
// 成员 y 的类型是 W,它来自于参数 b
Point { x: self.y, y: b }
}
}
fn main() {
// T 是 i32,U 是 f64
let p1 = Point { x: 123, y: 3.14 };
// V 是 &str,W 是 (i32, i32, i32)
println!("{:?}", p1.m1("xx", (1, 2, 3)))
// Point { x: 3.14, y: (1, 2, 3) }
}
以上就是 Rust 的泛型,当然在工作中我们不会声明的这么复杂,这里只是为了更好掌握泛型的语法。
然后注意一下方法里面的 self,不是说方法的第一个参数应该是引用吗?理论上是这样的,但此处不行,而且如果写成 &self 是会报错的,会告诉我们没有实现 Copy 这个 trait。
之所以会有这个现象,是因为我们在返回值当中将 self.y 赋值给了成员 x。那么问题来了,如果方法的第一个参数是引用,就意味着结构体在调用完方法之后还能继续用,那么结构体内部所有成员的值都必须有效,否则结构体就没法用了。这个动态数组相似,如果动态数组是有效的,那么内部的所有元素必须都是有效的,否则就可能访问非法的内存。
因此在构建返回值、将 self.y 赋值给成员 x 的时候,就必须将 self.y 拷贝一份,并且还要满足拷贝完之后数据是各自独立的,互不影响。如果 self.y 的数据全部在栈上(可 Copy 的),那么这是没问题的;如果涉及到堆,那么只能转移 self.y 的所有权,因为 Rust 默认不会拷贝堆数据,但如果转移所有权,那么方法调用完之后结构体就不能用了,这与我们将第一个参数声明为引用的目的相矛盾。
所以 Rust 要求 self.y 必须是可 Copy 的,也就是数据必须都在栈上,这样才能满足在不拷贝堆数据的前提下,让 self.y 赋值之后依旧保持有效。但问题是,self.y 的类型是 U,而 U 代表啥类型 Rust 又不知道,所以 Rust 认为 U 不是可 Copy 的,或者说没有实现 Copy 这个 trait,于是报错。
因此第一个参数必须声明为 self,此时泛型是否实现 Copy 就不重要了,没实现的话会直接转移所有权。因为该结构体实例在调用完方法之后会被销毁,不再被使用,那么此时可以转移内部成员的所有权。正所谓人都没了,还要这所有权有啥用,不如在销毁之前将成员值的所有权交给别人。
最后说一下泛型代码的性能,使用泛型的代码和使用具体类型的速度是一样的,因此这就要求 Rust 在编译的时候能够推断出泛型的具体类型,所以类型要明确。
到此这篇关于深入了解Rust中泛型的使用的文章就介绍到这了,更多相关Rust泛型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

深入了解Rust 结构体的使用
目录 楔子 定义并实例化结构体 简化版的实例化方式 基于已有结构体实例创建 元组结构体 没有字段的空结构体 结构体数据的所有权 使用结构体的示例程序 楔子 结构体是一种自定义的数据类型,它允许我们将多个不同的类型组合成一个整体.下面我们就来学习如何定义和使用结构体,并对比元组与结构体之间的异同.后续我们还会讨论如何定义方法和关联函数,它们可以指定那些与结构体数据相关的行为. 定义并实例化结构体 结构体与我们之前讨论过的元组有些相似,和元组一样,结构体中的数据可以拥有不同的类型.而和元组不一样的是
-
深入了解Rust中函数与闭包的使用
目录 闭包 高阶函数 发散函数 闭包 Rust 的闭包由一个匿名函数加上外层的作用域组成,举个例子: fn main() { let closure = |n: u32| -> u32 { n * 2 }; println!("n * 2 = {}", closure(12)); // n * 2 = 24 } 闭包可以被保存在一个变量中,然后我们注意一下它的语法,参数定义.返回值定义都和普通函数一样,但闭包使用的是两个竖线.我们对
-
深入了解Rust的切片使用
目录 为什么要有切片 字符串切片 其它类型的切片 为什么要有切片 除了引用,Rust 还有另外一种不持有所有权的数据类型:切片(slice),切片允许我们引用集合中某一段连续的元素序列,而不是整个集合. 考虑这样一个小问题:编写一个搜索函数,它接收字符串作为参数,并将字符串中的首个单词作为结果返回.如果字符串中不存在空格,那么就意味着整个字符串是一个单词,直接返回整个字符串作为结果即可. 让我们来看一下这个函数的签名应该如何设计: fn first_word(s: &String) -> ?
-
深入了解Rust中引用与借用的用法
目录 楔子 什么是引用 可变引用 悬空引用 小结 楔子 好久没更新 Rust 了,上一篇文章中我们介绍了 Rust 的所有权,并且最后定义了一个 get_length 函数,但调用时会导致 String 移动到函数体内部,而我们又希望在调用完毕后能继续使用该 String,所以不得不使用元组将 String 也作为元素一块返回. // 该函数计算一个字符串的长度 fn get_length(s: String) -> (String, usize) { // 因为这里的 s 会获取变量的
-
Rust指南之泛型与特性详解
目录 前言 1.泛型 1.1.在函数中定义泛型 1.2.结构体中的泛型 1.3.枚举类中的泛型 1.4.方法中的泛型 2.特性 2.1.默认特性 2.2.特性做参数 2.3.特性做返回值 前言 在上篇Rust 文章中涉及到了泛型的知识,那么今天就来详细介绍一下Rust 中的泛型与特性.泛型是一个编程语言不可或缺的机制,例如在C++ 语言中用模板来实现泛型.泛型机制是编程语言用于表达类型抽象的机制,一般用于功能确定.数据类型待定的类,如链表.映射表等. 1.泛型 泛型是具体类型或其他属性的抽象代替
-
深入了解Rust中泛型的使用
目录 楔子 函数中的泛型 结构体中的泛型 枚举中的泛型 方法中的泛型 楔子 所有的编程语言都致力于将重复的任务简单化,并为此提供各种各样的工具.在 Rust 中,泛型(generics)就是这样一种工具,它是具体类型或其它属性的抽象替代.在编写代码时,我们可以直接描述泛型的行为,以及与其它泛型产生的联系,而无须知晓它在编译和运行代码时采用的具体类型. 总结一下泛型就是,提高代码的复用能力,处理重复代码.泛型是具体类型或者其它属性的抽象代替,编写的泛型代码不是最终的代码,而是一些模板,里面有一些占
-
Rust中的Struct使用示例详解
Structs是RUST中比较常见的自定义类型之一,又可以分为StructStruct,TupleStruct,UnitStruct三个类型,结合泛型.Trait限定.属性.可见性可以衍生出很丰富的类型. 结构体 1.定义 pub struct User { user_id : u32, user_name: String, is_vip : bool, } 2.实例化这里初始化必须全部给所有的成员赋值,不像C++,可以单独初始化某个值 let user : User = User { user
-
深入了解Rust中trait的使用
目录 楔子 什么是 trait trait 作为参数 trait 作为返回值 实现一个 max 函数 楔子 前面我们提到过 trait,那么 trait 是啥呢?先来看个例子: #[derive(Debug)] struct Point<T> { x: T, } impl<T> Point<T> { fn m(&self) { let var = self.x; } } fn main() { let p = Po
-
Java中泛型的用法总结
本文实例总结了Java中泛型的用法.分享给大家供大家参考.具体如下: 1 基本使用 public interface List<E> { void add(E); Iterator<E> iterator(); } 2 泛型与子类 Child是Parent的子类,List<Child>却不是List<Parent>的子类. 因此:List<Object> list = new ArrayList<String>()是错误的. 如果上面
-
Java中泛型使用实例详解
Java中泛型使用 泛型作用: 泛型:集合类添加对象不用强转 反射机制:将泛型固定的类的所有方法和成员全部显示出来 核心代码: ArrayList<Ls> ff=new ArrayList()<Ls>; Ls ls1=new Ls("薯片",5f); ff.add(ls1); Ls cls=ff.get(0);//这里不再需要强转 代码实例: 说明:这是非泛型的代码,集合类中调用对象时需要强转 import java.util.*; public class L
-
Java中泛型通配符的使用方法示例
本文实例讲述了Java中泛型通配符的使用方法.分享给大家供大家参考,具体如下: 一 点睛 引入通配符可以在泛型实例化时更加灵活地控制,也可以在方法中控制方法的参数. 语法如下: 泛型类名<? extends T> 或 泛型类名<? super T> 或 泛型类名<?> ? extends T:表示T或T的子类 ? super T:表示T或T的父类 ?:表示可以是任意类型 二 通配符在泛型类创建泛型对象中使用 1 代码 class gent<T> { publ
-
Java中泛型总结(推荐)
Java 泛型(generics)是 JDK 5 中引入的一个新特性, 泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型. 泛型的本质是参数化类型,也就是说所操作的数据类型被指定为一个参数. 泛型类 范例:泛型类的基本语法 class MyClass<T> { T value1; } 尖括号 <> 中的 T 被称作是类型参数,用于指代任何类型.实际上这个T你可以任意写,但出于规范的目的,Java还是建议我们用单个大写字母来代表类型参数.常见的如: T 代表
-
详解Java 中泛型的实现原理
泛型是 Java 开发中常用的技术,了解泛型的几种形式和实现泛型的基本原理,有助于写出更优质的代码.本文总结了 Java 泛型的三种形式以及泛型实现原理. 泛型 泛型的本质是对类型进行参数化,在代码逻辑不关注具体的数据类型时使用.例如:实现一个通用的排序算法,此时关注的是算法本身,而非排序的对象的类型. 泛型方法 如下定义了一个泛型方法, 声明了一个类型变量,它可以应用于参数,返回值,和方法内的代码逻辑. class GenericMethod{ public <T> T[] sort(T[]
-
TypeScrip中泛型的案例详解
泛型的定义 // 需求一: 泛型 可以支持不特定的数据类型, 要求,传入的参数和返回参数一致 // 这种方式虽然能实现传入和返回的参数一致,但是失去类型参数检验 /* function getData(value: any): any { return "success" } */ // 定义泛型解决需求一 // T表示泛型(这里的大写字母可以随便定义,但一般默认为T) 具体什么类型是调用这个方法的时候决定的 function getData<T>(value: T):T{
-
Rust 中的文件操作示例详解
目录 文件路径 文件创建和删除 目录创建和删除 文件创建和删除 文件读取和写入 文件打开 文件读取 文件写入 相关资料 文件路径 想要打开或者创建一个文件,首先要指定文件的路径. Rust 中的路径操作是跨平台的,std::path 模块提供的了两个用于描述路径的类型: PathBuf – 具有所有权并且可被修改,类似于 String. Path – 路径切片,类似于 str. 示例: use std::path::Path; use std::path::PathBuf; fn main()