pytorch实现mnist手写彩色数字识别
目录
- 前言
- 一 前期工作
- 1.设置GPU或者cpu
- 2.导入数据
- 二 数据预处理
- 1.加载数据
- 2.可视化数据
- 3.再次检查数据
- 三 搭建网络
- 四 训练模型
- 1.设置学习率
- 2.模型训练
- 五 模型评估
- 1.Loss和Accuracy图
- 2.总结
前言
环境:
- 语言环境:Python3.6
- 编译器:jupyter lab
- 深度学习环境:pytorch1.10
要求:
- 学习如何编写一个完整的深度学习程序()
- 手动推导卷积层与池化层的计算过程()
一 前期工作
环境:python3.6,1080ti,pytorch1.10(实验室服务器的环境)
1.设置GPU或者cpu
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import torchvision
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
2.导入数据
train_ds = torchvision.datasets.MNIST('data',
train=True,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
test_ds = torchvision.datasets.MNIST('data',
train=False,
transform=torchvision.transforms.ToTensor(), # 将数据类型转化为Tensor
download=True)
二 数据预处理
1.加载数据
设置数据尺寸
batch_size = 32
设置dataset
train_dl = torch.utils.data.DataLoader(train_ds,
batch_size=batch_size,
shuffle=True)
test_dl = torch.utils.data.DataLoader(test_ds,
batch_size=batch_size)
2.可视化数据
打印部分图片:
import numpy as np
# 指定图片大小,图像大小为20宽、5高的绘图(单位为英寸inch)
plt.figure(figsize=(20, 5))
for i, imgs in enumerate(imgs[:20]):
# 维度缩减
npimg = imgs.numpy().transpose((1, 2, 0))
# 将整个figure分成2行10列,绘制第i+1个子图。
plt.subplot(2, 10, i+1)
plt.imshow(npimg, cmap=plt.cm.binary)
plt.axis('off')

3.再次检查数据
输出数据的尺寸:
# 取一个批次查看数据格式 # 数据的shape为:[batch_size, channel, height, weight] # 其中batch_size为自己设定,channel,height和weight分别是图片的通道数,高度和宽度。 imgs, labels = next(iter(train_dl)) imgs.shape

三 搭建网络
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential,ReLU
num_classes = 10
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
# 卷积层
self.layers = Sequential(
# 第一层
Conv2d(3, 64, kernel_size=3),
MaxPool2d(2),
ReLU(),
# 第二层
Conv2d(64, 64, kernel_size=3),
MaxPool2d(2),
ReLU(),
Conv2d(64, 128, kernel_size=3),
MaxPool2d(2),
ReLU(),
Flatten(),
Linear(512, 256,bias=True),
ReLU(),
Linear(256, 64,bias=True),
ReLU(),
Linear(64, num_classes,bias=True)
)
def forward(self, x):
x = self.layers(x)
return x
打印网络结构:
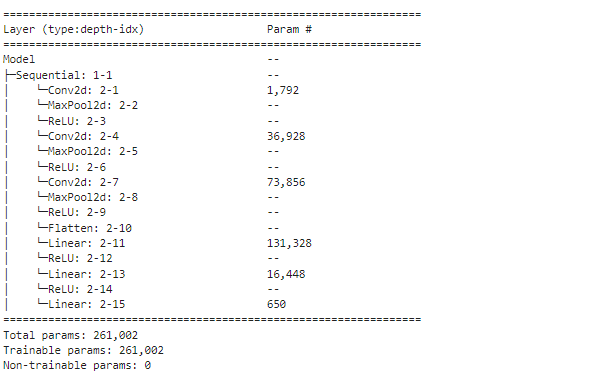
vgg16网络搭建:未修改尺寸
from torch import nn
vgg16=torchvision.models.vgg16(pretrained=True)#经过训练的
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
# 卷积层
self.layers = Sequential(
vgg16
)
def forward(self, x):
x = self.layers(x)
return x
vgg16网络搭建:修改尺寸
四 训练模型
1.设置学习率
loss_fn = nn.CrossEntropyLoss() # 创建损失函数 learn_rate = 1e-2 # 学习率 opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
2.模型训练
训练函数:
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
测试函数 :
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
具体训练代码 :
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
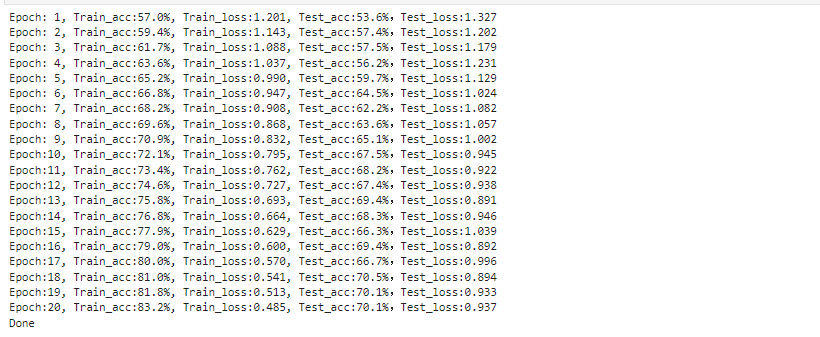
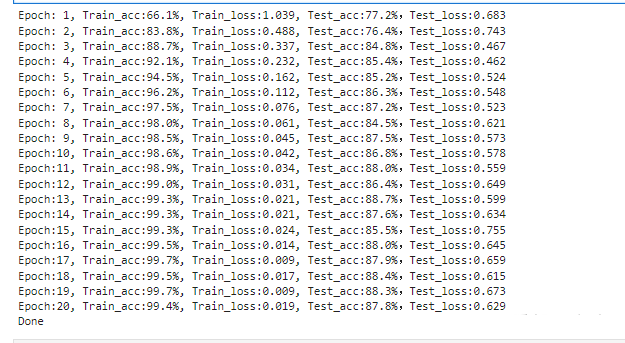
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
五 模型评估
1.Loss和Accuracy图

2.总结
- 1.本文与上篇文章区别在于灰色图像和彩色图像通道数一个为1,一个为3.所以这里的卷积输入都是3.
- 2.关于各层计算这里简单说一下,我们以范文举例:
卷积层:32->30因为((32-3)/1)+1=30
池化池:30->15因为30÷2=15
具体计算可以参考我题目开头的文章,这里不在赘述
我们可以看到本次训练效果不好,那我们可以利用经典网络vgg16进行修改,准确率提高到了百分之88了。
其代码如上:
到此这篇关于pytorch-实现mnist手写彩色数字识别的文章就介绍到这了,更多相关pytorch mnist内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解PyTorch手写数字识别(MNIST数据集)
MNIST 手写数字识别是一个比较简单的入门项目,相当于深度学习中的 Hello World,可以让我们快速了解构建神经网络的大致过程.虽然网上的案例比较多,但还是要自己实现一遍.代码采用 PyTorch 1.0 编写并运行. 导入相关库 import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets, t
-
Pytorch实现的手写数字mnist识别功能完整示例
本文实例讲述了Pytorch实现的手写数字mnist识别功能.分享给大家供大家参考,具体如下: import torch import torchvision as tv import torchvision.transforms as transforms import torch.nn as nn import torch.optim as optim import argparse # 定义是否使用GPU device = torch.device("cuda" if torch
-
pytorch教程实现mnist手写数字识别代码示例
目录 1.构建网络 2.编写训练代码 3.编写测试代码 4.指导程序train和test 5.完整代码 1.构建网络 nn.Moudle是pytorch官方指定的编写Net模块,在init函数中添加需要使用的层,在foeword中定义网络流向. 下面详细解释各层: conv1层:输入channel = 1 ,输出chanael = 10,滤波器5*5 maxpooling = 2*2 conv2层:输入channel = 10 ,输出chanael = 20,滤波器5*5, dropout ma
-
PyTorch实现MNIST数据集手写数字识别详情
目录 一.PyTorch是什么? 二.程序示例 1.引入必要库 2.下载数据集 3.加载数据集 4.搭建CNN模型并实例化 5.交叉熵损失函数损失函数及SGD算法优化器 6.训练函数 7.测试函数 8.运行 三.总结 前言: 本篇文章基于卷积神经网络CNN,使用PyTorch实现MNIST数据集手写数字识别. 一.PyTorch是什么? PyTorch 是一个 Torch7 团队开源的 Python 优先的深度学习框架,提供两个高级功能: 强大的 GPU 加速 Tensor 计算(类似 nump
-
pytorch 利用lstm做mnist手写数字识别分类的实例
代码如下,U我认为对于新手来说最重要的是学会rnn读取数据的格式. # -*- coding: utf-8 -*- """ Created on Tue Oct 9 08:53:25 2018 @author: www """ import sys sys.path.append('..') import torch import datetime from torch.autograd import Variable from torch im
-

PyTorch CNN实战之MNIST手写数字识别示例
简介 卷积神经网络(Convolutional Neural Network, CNN)是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功,在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的. 卷积神经网络CNN的结构一般包含这几个层: 输入层:用于数据的输入 卷积层:使用卷积核进行特征提取和特征映射 激励层:由于卷积也是一种线性运算,因此需要增加非线性映射 池化层:进行下采样,对特征图稀疏处理,减少数据运算量. 全连接层:通常在CNN的尾部进行重新拟合,减
-
pytorch实现mnist手写彩色数字识别
目录 前言 一 前期工作 1.设置GPU或者cpu 2.导入数据 二 数据预处理 1.加载数据 2.可视化数据 3.再次检查数据 三 搭建网络 四 训练模型 1.设置学习率 2.模型训练 五 模型评估 1.Loss和Accuracy图 2.总结 前言 环境: 语言环境:Python3.6 编译器:jupyter lab 深度学习环境:pytorch1.10 要求: 学习如何编写一个完整的深度学习程序() 手动推导卷积层与池化层的计算过程() 一 前期工作 环境:python3.6,1080t
-
Pytorch框架实现mnist手写库识别(与tensorflow对比)
前言最近在学习过程中需要用到pytorch框架,简单学习了一下,写了一个简单的案例,记录一下pytorch中搭建一个识别网络基础的东西.对应一位博主写的tensorflow的识别mnist数据集,将其改为pytorch框架,也可以详细看到两个框架大体的区别. Tensorflow版本转载来源(CSDN博主「兔八哥1024」):https://www.jb51.net/article/191157.htm Pytorch实战mnist手写数字识别 #需要导入的包 import torch impo
-
Python实战小项目之Mnist手写数字识别
目录 程序流程分析图: 传播过程: 代码展示: 创建环境 准备数据集 下载数据集 下载测试集 绘制图像 搭建神经网络 训练模型 测试模型 保存训练模型 运行结果展示: 程序流程分析图: 传播过程: 代码展示: 创建环境 使用<pip install+包名>来下载torch,torchvision包 准备数据集 设置一次训练所选取的样本数Batch_Sized的值为512,训练此时Epochs的值为8 BATCH_SIZE = 512 EPOCHS = 8 device = torch.devi
-
Python使用gluon/mxnet模块实现的mnist手写数字识别功能完整示例
本文实例讲述了Python使用gluon/mxnet模块实现的mnist手写数字识别功能.分享给大家供大家参考,具体如下: import gluonbook as gb from mxnet import autograd,nd,init,gluon from mxnet.gluon import loss as gloss,data as gdata,nn,utils as gutils import mxnet as mx net = nn.Sequential() with net.nam
-
Python tensorflow实现mnist手写数字识别示例【非卷积与卷积实现】
本文实例讲述了Python tensorflow实现mnist手写数字识别.分享给大家供大家参考,具体如下: 非卷积实现 import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data data_path = 'F:\CNN\data\mnist' mnist_data = input_data.read_data_sets(data_path,one_hot=True) #offline da
-
Python利用逻辑回归模型解决MNIST手写数字识别问题详解
本文实例讲述了Python利用逻辑回归模型解决MNIST手写数字识别问题.分享给大家供大家参考,具体如下: 1.MNIST手写识别问题 MNIST手写数字识别问题:输入黑白的手写阿拉伯数字,通过机器学习判断输入的是几.可以通过TensorFLow下载MNIST手写数据集,通过import引入MNIST数据集并进行读取,会自动从网上下载所需文件. %matplotlib inline import tensorflow as tf import tensorflow.examples.tutori