Python sklearn库三种常用编码格式实例
目录
- OneHotEncoder独热编码实例
- LabelEncoder标签编码实例
- OrdinalEncoder特征编码实例
OneHotEncoder独热编码实例
class sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error')
- 目的:将分类要素编码为one-hot数字数组
- 输入:为整数或字符串之类的数组,表示分类(离散)特征所采用的值。
- 这将为每个类别创建一个二进制列,并返回一个稀疏矩阵或密集数组(取决于稀疏参数)默认情况下,编码器会根据每个功能中的唯一值得出类别(可改为手动)
- 适用于GBDT、XGBoost、Lgb模型中效果都不错 注意:在最新版本的sklearn中,所有的数据都应该是二维矩阵,所以当它只是单独一行或一列需要进行
reshape(1, -1)数据转换,否则会报错ValueError: Expected 2D array, got 1D array instead
以下面数据为例(数据源):

from sklearn.preprocessing import OneHotEncoder
import pandas as pd
train = pd.read_csv('./train.csv')
enc = OneHotEncoder(handle_unknown='ignore')
numerical_feature = ['policy_annual_premium','insured_education_level','capital-gains','incident_type','incident_severity',\
'property_damage','bodily_injuries','police_report_available','total_claim_amount','injury_claim','property_claim','vehicle_claim']
data = train[numerical_feature]
c = enc.fit_transform(data.values.reshape(1,-1))
c.toarray()#查看转化后的数据
输入数据由处理后的这种格式:

经过编码后得出编码后的数据(数据量过大用元组的形式展现),全部由二进制数0、1表示:

注意:在一对多的情况下y标签需要使用 sklearn.preprocessing.LabelBinarizer() 函数将多类标签转换为二进制标签
LabelEncoder标签编码实例
- 目的:对目标标签进行编码,其值介于0和n_classes-1之间
- 输入可以是数字标签,也可以是非数字标签,这里需要注意的是返回的类型是NumPy的array形式,上述
OneHotEncoder ()返回的是系数矩阵形式。
from sklearn.preprocessing import LabelEncoder
Enc=LabelEncoder()
def yuchuli(data):
numerical_feature = ['policy_annual_premium','insured_education_level','capital-gains','incident_type','incident_severity',\
'property_damage','bodily_injuries','police_report_available','total_claim_amount','injury_claim','property_claim','vehicle_claim','auto_year']
data=pd.DataFrame()
for fea in numerical_feature:
data.insert(len(data.columns),fea,Enc.fit_transform(train[fea].values))
return data
train_data = yuchuli(train)
经过编码后得出编码后的数据:
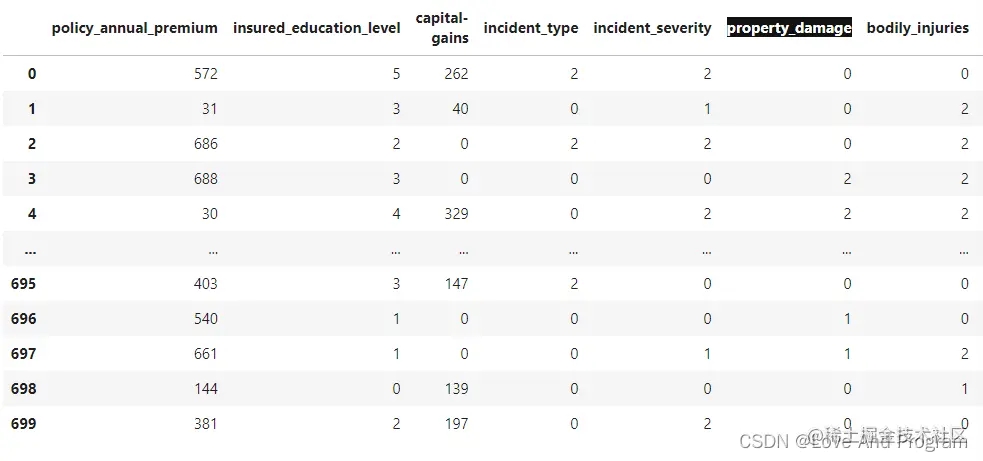
其中最清晰的就是标黑的property_damage一列,使用One-hot编码转换后变成?属于0,Yes属于2,No属于1。
LabelEncoder()只有一个class_属性,是查看每个类别的标签,在上述基础上尝试即最后一个特征所对应的属性标签,通俗来讲就是这里面需要被编码的个数就是这些数:

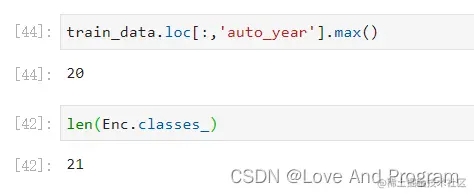
- 果然不出所料,因为这是循环,所以对应的最后一个是
auto_year,原数据如下图:

注意:开头提到的编码值介于 0 和 n_classes-1 之间于下图可以清晰理解,里面有n种不同的值,就分成 n-1 类,因为还包括 0
不过 LabelEncoder 标签编码我想对用的比较少,一般我都是使用 One-hot 独热编码去处理离散特征。
OrdinalEncoder特征编码实例
- 目的:将分类特征编码为整数数组。
- 输入:是一个类似数组的整数或字符串,表示分类(离散)特征所采用的值,特征会被转换为序数整数
from sklearn.preprocessing import OrdinalEncoder
import pandas as pd
import numpy as np
train = pd.read_csv('./train.csv')
test = pd.read_csv('./test.csv')
train.drop_duplicates()
Enc=LabelEncoder()
Enc=OneHotEncoder()
def yuchuli(data_train):
numerical_feature = ['incident_severity', 'insured_hobbies', 'vehicle_claim', 'auto_model', 'insured_education_level', 'insured_zip', 'insured_relationship', 'incident_date','auto_year']
data = pd.DataFrame()
for fea in numerical_feature:
data.insert(len(data.columns), fea, (Enc.fit_transform(train[fea].values.reshape(-1, 1))).tolist())
# return data
train_data = yuchuli(train)

但是我通过输出每一个特征结果的时候发现他和LabelEncoder()编码出的数据大差不离,特征编码则通过categories_查看编码特征

总而言之就是结果数据是一样的,但是类型上是不同的,我通过本文了解到它们本质的区别:
OrdinalEncoder用于形状为 2D 的数据(n_samples, n_features)LabelEncoder用于形状为 1D 的数据(n_samples,)
至于为什么,我们从上面两者的代码中就可以发现,OrdinalEncoder 编码出的数据要想fit_transform拟合,就得使用.reshape(-1, 1)转换成二维数据,这一块和OneHotEncoder编码相同,而LabelEncoder则直接放入即可拟合出数据来,这里也是使用过程中最容易出现的问题。
OrdinalEncoder编码还是有两点需要注意的,第一点,他可以接受np.nan缺失值,可根据需求选择是否处理缺失值;第二点,他有 这么一个参数->handle_unknown=error(默认) ,通过判断是否存在未知的特征来选择是否继续进行程序,当我们们选择handle_unknown=use_encoded_value时会将存在的未知特征打上unknown_value标签
#将缺失值全部处理为-1 Enc.set_params(encoded_missing_value=-1,handle_unknown=use_encoded_value).fit_transform()
以上就是Python sklearn库三种常用编码格式实例的详细内容,更多关于Python sklearn库编码格式的资料请关注我们其它相关文章!
相关推荐
-

python机器学习sklearn实现识别数字
目录 简介 数据集 数据处理 数据分离 训练数据 数据可视化 完整代码 简介 本文主要简述如何通过sklearn模块来进行预测和学习,最后再以图表这种更加直观的方式展现出来 数据集 学习数据 预测数据 数据处理 数据分离 因为我们打开我们的的学习数据集,最后一项是我们的真实数值,看过小唐上一篇的人都知道,老规矩先进行拆分,前面的特征放一块,后面的真实值放一块,同时由于数据没有列名,我们选择使用iloc[]来实现分离 def shuju(tr_path,ts_path,sep='\t'): tra
-
python pandas 数据排序的几种常用方法
前言: pandas中排序的几种常用方法,主要包括sort_index和sort_values. 基础数据: import pandas as pd import numpy as np data = { 'brand':['Python', 'C', 'C++', 'C#', 'Java'], 'B':[4,6,8,12,10], 'A':[10,2,5,20,16], 'D':[6,18,14,6,12], 'years':[4,1,1,30,30], 'C':[8,12,18,8,2] }
-
Python sklearn分类决策树方法详解
目录 决策树模型 决策树学习 使用Scikit-learn进行决策树分类 决策树模型 决策树(decision tree)是一种基本的分类与回归方法. 分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(internal node)和叶结点(leaf node).内部结点表示一个特征或属性,叶结点表示一个类. 用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子
-
Python 第三方库 Pandas 数据分析教程
目录 Pandas导入 Pandas与numpy的比较 Pandas的Series类型 Pandas的Series类型的创建 Pandas的Series类型的基本操作 pandas的DataFrame类型 pandas的DataFrame类型创建 Pandas的Dataframe类型的基本操作 pandas索引操作 pandas重新索引 pandas删除索引 pandas数据运算 算术运算 Pandas数据分析 pandas导入与导出数据 导入数据 导出数据 Pandas查看.检查数据 Pand
-
python sklearn与pandas实现缺失值数据预处理流程详解
注:代码用 jupyter notebook跑的,分割线线上为代码,分割线下为运行结果 1.导入库生成缺失值 通过pandas生成一个6行4列的矩阵,列名分别为'col1','col2','col3','col4',同时增加两个缺失值数据. import numpy as np import pandas as pd from sklearn.impute import SimpleImputer #生成缺失数据 df=pd.DataFrame(np.random.randn(6,4),colu
-
python库sklearn常用操作
目录 前言 一.MinMaxScaler 前言 sklearn是python的重要机器学习库,其中封装了大量的机器学习算法,如:分类.回归.降维以及聚类:还包含了监督学习.非监督学习.数据变换三大模块.sklearn拥有完善的文档,使得它具有了上手容易的优势:并它内置了大量的数据集,节省了获取和整理数据集的时间.因而,使其成为了广泛应用的重要的机器学习库. sklearn是一个无论对于机器学习还是深度学习都必不可少的重要的库,里面包含了关于机器学习的几乎所有需要的功能,因为sklearn库的内容
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
Python sklearn转换器估计器和K-近邻算法
目录 一.转换器和估计器 1. 转换器 2.估计器(sklearn机器学习算法的实现) 3.估计器工作流程 二.K-近邻算法 1.K-近邻算法(KNN) 2. 定义 3. 距离公式 三.电影类型分析 1 问题 2 K-近邻算法数据的特征工程处理 四.K-近邻算法API 1.步骤 2.代码 3.结果及分析 五.K-近邻总结 一.转换器和估计器 1. 转换器 想一下之前做的特征工程的步骤? 1.实例化 (实例化的是一个转换器类(Transformer)) 2.调用fit_transform(对于文档
-
一文搞懂Python Sklearn库使用
目录 1.LabelEncoder 2.OneHotEncoder 3.sklearn.model_selection.train_test_split随机划分训练集和测试集 4.pipeline 5 perdict 直接返回预测值 6 sklearn.metrics中的评估方法 7 GridSearchCV 8 StandardScaler 9 PolynomialFeatures 4.10+款机器学习算法对比 4.1 生成数据 4.2 八款主流机器学习模型 4.3 树模型 - 随机森林 4.
-
Python sklearn库三种常用编码格式实例
目录 OneHotEncoder独热编码实例 LabelEncoder标签编码实例 OrdinalEncoder特征编码实例 OneHotEncoder独热编码实例 class sklearn.preprocessing.OneHotEncoder(*, categories='auto', drop=None, sparse=True, dtype=<class 'numpy.float64'>, handle_unknown='error') 目的:将分类要素编码为one-hot数字数组
-
python sklearn库实现简单逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Reduction).分类(Classfication).聚类(Clustering)等方法.当我们面临机器学习问题时,便可根据下图来选择相应的方法. Sklearn具有以下特点: 简单高效的数据挖掘和数据分析工具 让每个人能够在复杂环境中重复使用 建立NumPy.Scipy.MatPlotLib之上 代
-
Python sklearn库实现PCA教程(以鸢尾花分类为例)
PCA简介 主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等.矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推. 基本步骤: 具体实现 我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布.样本数据结构如下图: 其中样本总数为150
-
基于python requests库中的代理实例讲解
直接上代码: #request代理(proxy) """ 1.启动代理服务器Heroku,相当于aliyun 2.在主机1080端口启动Socks 服务 3.将请求转发到1080端口 4.获取相应资源 首先要安装包pip install 'requests[socksv5]' """ import requests #定义一个代理服务器,所有的http及https都走socks5的协议,sock5相当于http协议,它是在会话层 #把它转到本机的
-
Python标准库之sqlite3使用实例
Python自带一个轻量级的关系型数据库SQLite.这一数据库使用SQL语言.SQLite作为后端数据库,可以搭配Python建网站,或者制作有数据存储需求的工具.SQLite还在其它领域有广泛的应用,比如HTML5和移动端.Python标准库中的sqlite3提供该数据库的接口. 我将创建一个简单的关系型数据库,为一个书店存储书的分类和价格.数据库中包含两个表:category用于记录分类,book用于记录某个书的信息.一本书归属于某一个分类,因此book有一个外键(foreign key)
-
python爬虫库scrapy简单使用实例详解
最近因为项目需求,需要写个爬虫爬取一些题库.在这之前爬虫我都是用node或者php写的.一直听说python写爬虫有一手,便入手了python的爬虫框架scrapy. 下面简单的介绍一下scrapy的目录结构与使用: 首先我们得安装scrapy框架 pip install scrapy 接着使用scrapy命令创建一个爬虫项目: scrapy startproject questions 相关文件简介: scrapy.cfg: 项目的配置文件 questions/: 该项目的python模块.之
-
ansible作为python模块库使用的方法实例
前言 ansible是新出现的自动化运维工具,基于Python开发,集合了众多运维工具(puppet.cfengine.chef.func.fabric)的优点,实现了批量系统配置.批量程序部署.批量运行命令等功能.ansible是基于模块工作的,本身没有批量部署的能力.真正具有批量部署的是ansible所运行的模块,ansible只是提供一种框架. 主要包括: (1).连接插件connection plugins:负责和被监控端实现通信: (2).host inventory:指定操作的主机,
-
解决Python requests库编码 socks5代理的问题
编码问题 response = requests.get(URL, params=params, headers=headers, timeout=10) print 'self.encoding',response.encoding output: self.encoding ISO-8859-1 查了一些相关的资料,看了下requests的源码,只有在服务器响应的头部包含有Content-Type,且里面有charset信息,requests能够正确识别,否则就会使用默认的 ISO-8859
-
Python使用sklearn库实现的各种分类算法简单应用小结
本文实例讲述了Python使用sklearn库实现的各种分类算法简单应用.分享给大家供大家参考,具体如下: KNN from sklearn.neighbors import KNeighborsClassifier import numpy as np def KNN(X,y,XX):#X,y 分别为训练数据集的数据和标签,XX为测试数据 model = KNeighborsClassifier(n_neighbors=10)#默认为5 model.fit(X,y) predicted = m