一文详解kafka序列化器和拦截器
目录
- 介绍
- 序列化器
- 设置序列化和反序列化
- 自定义序列化
- 自定义反序列化
- 思考
- 拦截器
- 总结
介绍
本篇主要介绍kafka的拦截器和序列化器,序列化器是和数据在网络中的传输有关,数据在网络中的传输为字节流,所以生产者在发送时需要将其序列化为字节流,消费者收到消息时,需要将字节流反序列化为我们能够识别的对象,我们不难看出,这就是RPC通信,kafka中实现了很多自定义协议,我们知道,在RPC通信中,只有生产者和消费者的协议一样,才能相互传输和解析数据,在使用HTTP时,我们就不用去关注协议本身,因为HTTP是TCP的上层建筑,它自己实现了一套协议,我们不用去关注,但是使用RPC,我们是面向TCP编程,所以自然得约定和实现自己的协议,而序列化就是这过程中很重要的一部分。
拦截器是一个随处可见的词,基本上很多框架中都有拦截器机制,它的作用主要是对请求进行拦截,我们可以对请求进行过滤和处理,以达到业务目的,比如Spring中有HandlerInterceptor拦截器,在kafka种也有拦截器,我们可以自定义拦截器,对消息进行拦截,比如某些异常消息我们不需要发送,那么就将其拦截下来。
序列化器
数据在网络中传输是以字节流的形式进行传输,在生产者端发送消息需要先进行序列化,消费者端进行反序列化,序列化的方式有很多,比如jdk,json,protobuf,kryo,hessian,avro等等,在大数据量的传输中,序列化和反序列化的效率对吞吐量有一定的影响,kafka提供了许多序列化和反序列化器,如StringDeserializer和StringSerializer,如果我们需要自定义一个序列化和反序列化器,那么实现Serializer,Deserializer接口即可。
如下,kafka生产者在发送消息到broker之前需要序列化,消费者从broker获取消息后需要反序列化。
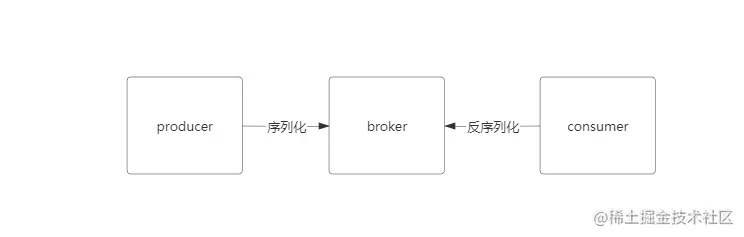
设置序列化和反序列化
生产者端设置序列化
//序列化
props.put("key.serializer", StringSerializer.class.getName());
props.put("value.serializer", StringSerializer.class.getName());
消费者端设置反序列化
props.put("key.deserializer", StringDeserializer.class.getName());
props.put("value.deserializer", StringDeserializer.class.getName());
自定义序列化
/**
* 功能说明: JSON序列化
* <p>
* Original @Author: steakliu , 2022-11-02 15:14
*/
public class JsonSerializer<T> implements Serializer<T> {
@Override
public byte[] serialize(String topic, T obj) {
try {
return obj == null ? null : JSON.toJSONBytes(obj);
}catch (Exception e){
throw new SerializationException("json serializing exception");
}
}
}
自定义反序列化
/**
* 功能说明:JSON反序列化
* <p>
* Original @Author: steakliu-刘牌, 2022-11-11 09:38
*/
public class JsonDeserializer<T> implements Deserializer<T> {
@Override
public T deserialize(String topic, byte[] data) {
return (T) JSON.parse(data);
}
}
如上简单的使用fastjson作为序列化和反序列化工具,演示了自定义kafka的序列化和反序列化机制,我们可以根据实际情况来设计不同的序列化反序列化机制,当然,不会是像上面这些简单,如果使用spring,那么spring提供了JSON序列化和反序列化器直接使用。
思考
虽然我们可以自定义序列化和反序列化器,但是自定义序列化和反序列化器在使用上也要保持一些一致,也就是说生产者和消费者要保持使用一种类型的序列化机制,不然会出现消息转换问题,如果我们以kafka的方式向别人提供服务,那么他们就需要使用我们的制定的序列化方式,所以这可能就存在一定的耦合,如果使用Kafka的String序列化和反序列化机制,因为是它是默认方式并且是字符串,通用性比较好,所以就不用去考虑序列化和反序列化,直接拿到字符串转为对象,再进行业务处理,使用自定义序列化的话,就直接拿到序列化后的对象,不用进行字符串转对象操作。
在实际场景中,我们可以根据自己的业务来使用何种序列化方式,没有最好的,只有合适的。
拦截器
kafka中消费者和生产者都有拦截器,分别为ConsumerInterceptor和ProducerInterceptor,只需实现它们即可实现拦截,加入拦截器后,生产者会在发送消息之前对消息进行拦截处理,消费者在收到消息之前也会经过拦截器,那么我们就可以在拦截器中加入一些自己需要的逻辑。
如下消费者拦截器对消息进行拦截,如果有异常消息,则对异常消息进行处理,只要需要对消息进行处理,监控等,都可以使用拦截器。
/**
* 功能说明: 消费者拦截器
* <p>
* Original @Author: steakliu-刘牌, 2023-03-15 10:17
*/
public class MyConsumerInterceptor implements ConsumerInterceptor<String, Message> {
@Override
public ConsumerRecords<String, Message> onConsume(ConsumerRecords<String, Message> records) {
long currentTimeMillis = System.currentTimeMillis();
records.forEach(record -> {
if ("消息异常".equals(record.value().getMessageText())) {
//处理异常消息
this.handleMsg(record);
}
});
return records;
}
private void handleMsg(ConsumerRecord<String, Message> record) {
//处理异常消息
}
@Override
public void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {}
@Override
public void close() {}
@Override
public void configure(Map<String, ?> configs) { }
}
拦截器可以有多个,如果设置多个拦截器,那么就形成一个拦截器链,一个一个地执行。
下面是使用spring-kafka时所配置的拦截器和序列化器的基本配置。
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
consumer:
# 反序列化器
key-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
properties:
# 拦截器
interceptor:
classes: com.steakliu.kafka.interceptor.MyConsumerInterceptor
spring:
json:
trusted:
packages: '*'
producer:
key-serializer: org.springframework.kafka.support.serializer.JsonSerializer
value-serializer: org.springframework.kafka.support.serializer.JsonSerializer
properties:
# 拦截器
interceptor:
classes: com.steakliu.kafka.interceptor.MyProducerInterceptor,com.steakliu.kafka.interceptor.MyProducerInterceptor2
总结
对于拦截器和序列化器,我们上面作了简单地描述和示例,对于它们,可能我们都不怎么去去用甚至没有用过,但是还是很有必要去了解的,了解它的设计和思想,在一些特殊的场景可能会用到。
以上就是一文详解kafka序列化器和拦截器的详细内容,更多关于kafka序列化器拦截器的资料请关注我们其它相关文章!
相关推荐
-
流式图表拒绝增删改查之框架搭建过程
目录 前言 技术方案 数据库设计 基础模块 整体流程 最终效果 前言 作为一名练习时长两年半的夹娃工程师,常年浸泡在增删改查的业务代码里,每当金三银四来临该迭代自己简历的时候,面对自己的项目经历都十分窘迫.突然有天学弟问我在实习公司一直做缝缝补补的工作或者是一些基于封装好的RBAC(基于角色的权限管理系统)做业务的增删改查,眼下又要找工作了不知道咋写项目经验. 无论是功能.技术栈.设计都平淡无奇,问我咋整,我打开尘封已久的简历一看,操,我不也一样吗. 当时快毕业那会也是有点焦虑,难的项目看不懂简
-
流式图表拒绝增删改查之kafka核心消费逻辑下篇
目录 前篇回顾 kafka消费者线程 任务提交 前篇回顾 流式图表框架搭建 kafka核心消费逻辑线程池搭建 kafka消费者线程 突击检查八股文,实现线程的方法有哪些?嗯?没复习是吧,行没关系,那感谢参加本次面试哈. 常用的几种方式分别是: 继承Thread类,重写run方法 实现Runbale接口,重写run方法 实现Callable接口,重写call方法 这里我们直接创捷出一个任务类实现Runable方法,重写run方法,一个线程当作一个kafka client,所以要在任务类中声明一个K
-
Spring Boot整合Kafka教程详解
目录 正文 步骤一:添加依赖项 步骤二:配置 Kafka 步骤三:创建一个生产者 步骤四:创建一个消费者 正文 本教程将介绍如何在 Spring Boot 应用程序中使用 Kafka.Kafka 是一个分布式的发布-订阅消息系统,它可以处理大量数据并提供高吞吐量. 在本教程中,我们将使用 Spring Boot 2.5.4 和 Kafka 2.8.0. 步骤一:添加依赖项 在 pom.xml 中添加以下依赖项: <dependency> <groupId>org.springfra
-

详解Angular.js中$http拦截器的介绍及使用
前言 $http service在Angular中用于简化与后台的交互过程,其本质上使用XMLHttpRequest或JSONP进行与后台的数据交互.在与后台的交互过程中,可能会对每条请求发送到Server之前进行预处理(如加入token),或者是在Server返回数据到达客户端还未被处理之前进行预处理(如将非JSON格式数据进行转换):当然还有可能对在请求和响应过程过发生的问题进行捕获处理.所有这些需求在开发中都非常常见,所以Angular为我们提供了$http拦截器,用来实现上述需求. 什么
-
详解Vue中使用Axios拦截器
需求是拦截前端的网络请求和相应. 废话不多说,直接上干货. 我用的是vue-cli3所以这个config文件是我自己创建的. 先介绍env.js //根据不同的环境更改不同的baseUrl let baseUrl = ''; //开发环境下 if (process.env.NODE_ENV == 'development') { baseUrl = ''; } else if (process.env.NODE_ENV == 'production') { baseUrl = '生产地址'; }
-
详解spring面向切面aop拦截器
spring中有很多概念和名词,其中有一些名字不同,但是从功能上来看总感觉是那么的相似,比如过滤器.拦截器.aop等. 过滤器filter.spring mvc拦截器Interceptor .面向切面编程aop,实际上都具有一定的拦截作用,都是拦截住某一个面,然后进行一定的处理. 在这里主要想着手的是aop,至于他们的比较,我想等三个都一一了解完了再说,因此这里便不做过多的比较. 在我目前的项目实践中,只在一个地方手动显示的使用了aop,那便是日志管理中对部分重要操作的记录. 据我目前所知,ao
-
详解SpringMVC中使用Interceptor拦截器
SpringMVC 中的Interceptor 拦截器也是相当重要和相当有用的,它的主要作用是拦截用户的请求并进行相应的处理.比如通过它来进行权限验证,或者是来判断用户是否登陆,或者是像12306 那样子判断当前时间是否是购票时间. 一.定义Interceptor实现类 SpringMVC 中的Interceptor 拦截请求是通过HandlerInterceptor 来实现的.在SpringMVC 中定义一个Interceptor 非常简单,主要有两种方式,第一种方式是要定义的Interce
-
一文详解Java拦截器与过滤器的使用
目录 流程图 拦截器vs过滤器 SpringMVC技术架构图 项目Demo 依赖 Interceptor拦截器 Filter过滤器 1.多Filter不指定过滤顺序 2.多Filter指定过滤顺序 流程图 拦截器vs过滤器 拦截器是SpringMVC的技术 过滤器的Servlet的技术 先过过滤器,过滤器过完才到DispatcherServlet: 拦截器归属于SpringMVC,只可能拦SpringMVC的东西: 拦截器说白了就是为了增强,可以在请求前进行增强,也可以在请求后进行增强,但是不一
-
一文详解Golang协程调度器scheduler
目录 1. 调度器scheduler的作用 2. GMP模型 3. 调度机制 1. 调度器scheduler的作用 我们都知道,在Go语言中,程序运行的最小单元是gorouines. 然而程序的运行最终都是要交给操作系统来执行的,以Java为例,Java中的一个线程对应的就是操作系统中的线程,以此来实现在操作系统中的运行.在Go中,gorouines比线程更轻量级,其与操作系统的线程也不是一一对应的关系,然而,最终我们想要执行程序,还是要借助操作系统的线程来完成,调度器scheduler的工作就
-
一文详解如何创建自己的Python装饰器
目录 1.@staticmethod 2.自定义装饰器 3.带参数的装饰器 python装饰器在平常的python编程中用到的还是很多的,在本篇文章中我们先来介绍一下python中最常使用的@staticmethod装饰器的使用. 之后,我们会使用两种不同的方式来创建自己的自定义python装饰器以及如何在其他地方进行调用. 1.@staticmethod @staticmethod是python开发者经常用来在一个类中声明该函数是一个静态函数时使用到的装饰器,比如创建一个HelloWorld的
-
一文详解Java过滤器拦截器实例逐步掌握
目录 一.过滤器与拦截器相同点 二.过滤器与拦截器区别 三.过滤器与拦截器的实现 四.过滤器与拦截器相关面试题 一.过滤器与拦截器相同点 1.拦截器与过滤器都是体现了AOP的思想,对方法实现增强,都可以拦截请求方法. 2.拦截器和过滤器都可以通过Order注解设定执行顺序 二.过滤器与拦截器区别 在Java Web开发中,过滤器(Filter)和拦截器(Interceptor)都是常见的用于在请求和响应之间进行处理的组件.它们的主要区别如下: 运行位置不同:过滤器是运行在Web服务器和Servl
-
一文详解Java中的类加载机制
目录 一.前言 二.类加载的时机 2.1 类加载过程 2.2 什么时候类初始化 2.3 被动引用不会初始化 三.类加载的过程 3.1 加载 3.2 验证 3.3 准备 3.4 解析 3.5 初始化 四.父类和子类初始化过程中的执行顺序 五.类加载器 5.1 类与类加载器 5.2 双亲委派模型 5.3 破坏双亲委派模型 六.Java模块化系统 一.前言 Java虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验.转换解析和初始化,最 终形成可以被虚拟机直接使用的Java类型,这个过程
-
一文详解Java中Stream流的使用
目录 简介 操作1:创建流 操作2:中间操作 筛选(过滤).去重 映射 排序 消费 操作3:终止操作 匹配.最值.个数 收集 规约 简介 说明 本文用实例介绍stream的使用. JDK8新增了Stream(流操作) 处理集合的数据,可执行查找.过滤和映射数据等操作. 使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询.可以使用 Stream API 来并行执行操作. 简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式. 特点 不是数据结构