使用LibTorch进行C++调用pytorch模型方式
目录
- 环境
- 具体过程
- 下载LibTorch
- 用pytorch生成模型文件
- VS创建工程并进行环境配置
- 运行VS2017工程文件
- 总结
前天由于某些原因需要利用C++调用PyTorch,于是接触到了LibTorch,配了两天最终有了一定的效果,于是记录一下。
环境
- PyTorch1.6.0
- cuda10.2
- opencv4.4.0
- VS2017
具体过程
下载LibTorch
去PyTorch官网下载LibTorch包,选择对应的版本,这里我选择Stable(1.6.0),Windows,LibTorch,C++/JAVA,10.2,然后我选择release版本下载,如下图
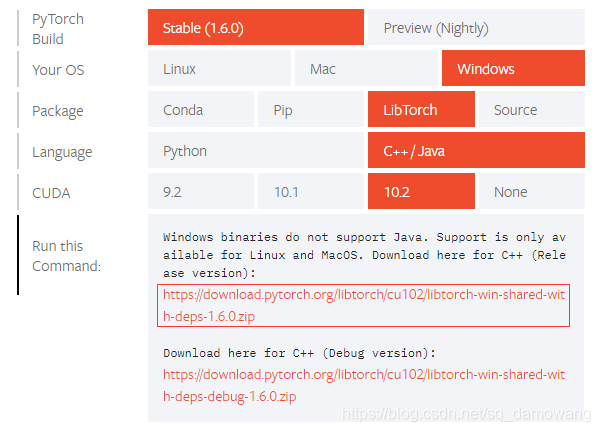
下载完后先不用管它,之后再用
用pytorch生成模型文件
我先创建了一个python文件,加载resnet50预训练模型,用来生成模型文件,代码如下
import torch
import torchvision.models as models
from PIL import Image
import numpy as np
from torchvision import transforms
model_resnet = models.resnet50(pretrained=True).cuda()
# model_resnet.load_state_dict(torch.load("resnet_Epoch_4_Top1_99.75845336914062.pkl"))
model_resnet.eval()
# 自己选择任意一张图片,并将它的路径写在open方法里,用来读取图像,我这里路径就是‘111.jpg'了
image = Image.open("111.jpg").convert('RGB')
tf = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
# transforms.Normalize(mean=[0.5]*3, std=[0.5]*3)
])
img = tf(image)
img = img.unsqueeze(dim=0)
print(img.shape)
input = torch.rand(1, 3, 224, 224).cuda()
traced_script_module_resnet = torch.jit.trace(model_resnet, input)
output = traced_script_module_resnet(img.cuda())
print(output.shape)
pred = torch.argmax(output, dim=1)
print(pred)
traced_script_module_resnet.save("model_resnet_jit_cuda.pt")
最后可以生成一个model_resnet_jit_cuda.pt文件,产生的输出如下所示
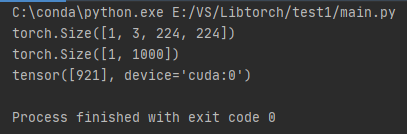
第一行是我们读取图像的shape,我们读取图片之后经过各种resize,增加维度,把图片数据的shape修改成模型接受的格式,可以看到预测的结果是921,之后我们将用到生成的model_resnet_jit_cuda.pt文件。
VS创建工程并进行环境配置
我在这个python文件路径下创建了这个vs工程Project1
创建完成之后我们打开Project1文件夹,里面内容如下
现在创建VS工程先告一段落,开始进行工程环境配置。把之前下载的LibTorch,解压到当前目录,解压后会出现一个libtorch的文件夹,文件夹目录里的内容为
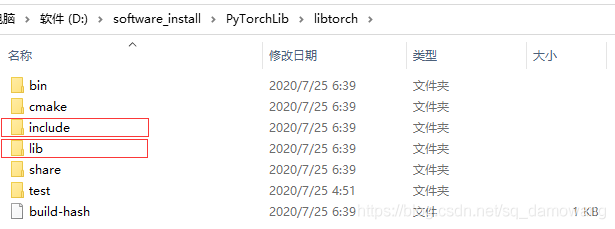
这里将我框选的文件夹路径配置到工程属性当中,打开刚才新建的VS工程,选择项目为relaese的×64版本

然后点击项目->Project1属性,弹出属性页
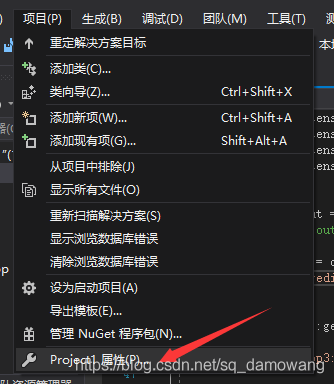
在属性页同样注意是release的×64平台,点击VC++目录,在包含目录下加载我之前框出来的include文件夹路径,在库目录下加载框出来的lib文件夹路径,同时,我们也要用到opencv,所以也需要在包含目录下加载opencv的include文件夹与opencv2文件夹,在库目录下加载opencv\build\x64\vc14\lib,如下图

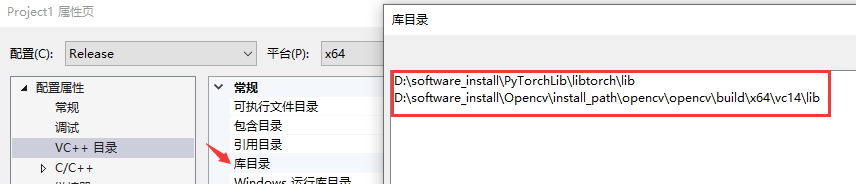
然后在属性页的链接器->输入,添加附加依赖项,首先先把opencv的依赖项添加了
opencv_world440.lib,(如果一直用的Debug模式,就添加opencv_world440d.lib),然后将libtorch/lib里所有后缀为.lib的文件全添加进来,打开这个文件夹
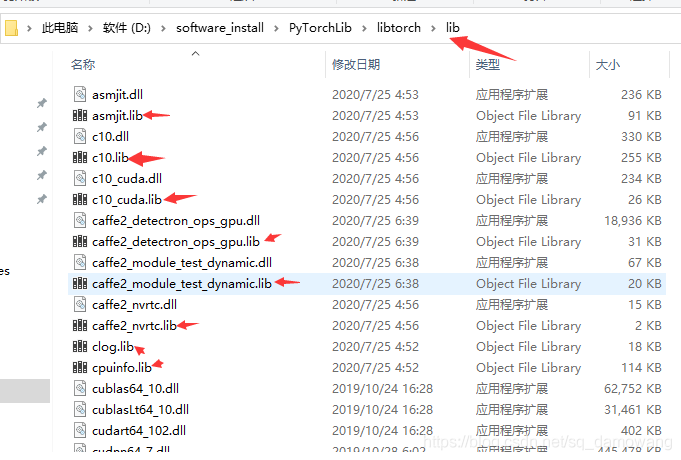
全都写进去,再点击确定,如下图所示
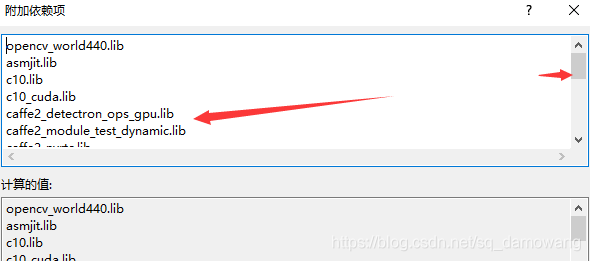
然后点击链接器->命令行,加上/INCLUDE:?warp_size@cuda@at@@YAHXZ 这一句,加上这一句是因为我们要用cuda版本的,如果是cpu版本可以不加。
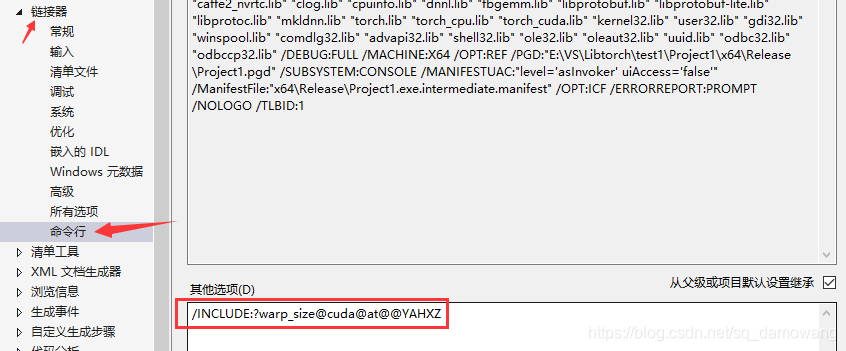
最后点击C/C++ ->常规的SDL检查,设置为否
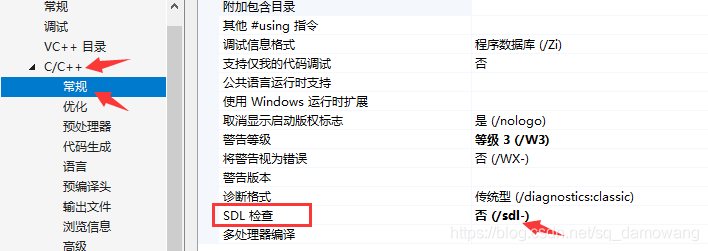
点击C/C++ ->语言的符合模式,设置为否
到此我们的配置就全部结束了!最后!复制libtorch/lib文件夹下所有文件,粘贴到工程文件夹Project1/×64/release文件夹里(点击此处的Project1文件夹可以发现里面也有一个×64/release,之前我也纠结是放在哪,然后我都试了一下,发现这个里面是可以不放的)
运行VS2017工程文件
然后我运行VS工程下一个空的main文件,没有报错,配置大致是没问题的,最后添加完整代码,如下
#include <torch/script.h> // One-stop header.
#include <opencv2/opencv.hpp>
#include <iostream>
#include <memory>
//https://pytorch.org/tutorials/advanced/cpp_export.html
std::string image_path = "../../111.jpg";
int main(int argc, const char* argv[]) {
// Deserialize the ScriptModule from a file using torch::jit::load().
//std::shared_ptr<torch::jit::script::Module> module = torch::jit::load("../../model_resnet_jit.pt");
using torch::jit::script::Module;
Module module = torch::jit::load("../../model_resnet_jit_cuda.pt");
module.to(at::kCUDA);
//assert(module != nullptr);
//std::cout << "ok\n";
//输入图像
auto image = cv::imread(image_path, cv::ImreadModes::IMREAD_COLOR);
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
cv::Mat image_transfomed;
cv::resize(image, image_transfomed, cv::Size(224, 224));
// 转换为Tensor
torch::Tensor tensor_image = torch::from_blob(image_transfomed.data,
{ image_transfomed.rows, image_transfomed.cols,3 }, torch::kByte);
tensor_image = tensor_image.permute({ 2,0,1 });
tensor_image = tensor_image.toType(torch::kFloat);
tensor_image = tensor_image.div(255);
tensor_image = tensor_image.unsqueeze(0);
tensor_image = tensor_image.to(at::kCUDA);
// 网络前向计算
at::Tensor output = module.forward({ tensor_image }).toTensor();
//std::cout << "output:" << output << std::endl;
auto prediction = output.argmax(1);
std::cout << "prediction:" << prediction << std::endl;
int maxk = 3;
auto top3 = std::get<1>(output.topk(maxk, 1, true, true));
std::cout << "top3: " << top3 << '\n';
std::vector<int> res;
for (auto i = 0; i < maxk; i++) {
res.push_back(top3[0][i].item().toInt());
}
for (auto i : res) {
std::cout << i << " ";
}
std::cout << "\n";
system("pause");
}
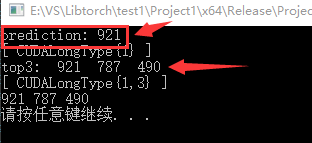
得到最终输出为921,可以看到和之前的python文件下输出一致,这里还输出了它的top前三,分别是921,787,490。
注意到,我的这两个输出相同的前提条件是:
1、确定加载的是由对应python文件生成的模型!
2、输入的图片是同一张!并且在python下和C++下进行了同样的转换,这里我在python下,将它进行了RGB模型的转换,resize(224, 224),并且将它的每一个元素值除以255.0,转换到0~1之间(ToTensor()方法),最后维度转换为1, 3, 224, 224,在C++中同样需要将BGR模型转化为RGB模型,进行图像缩放至224,224,并且将像素值除以255,将类型转化为float类型,最后维度同样转换为1,3,224,224,再进行网络前向计算。
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
PyTorch使用cpu加载模型运算方式
没gpu没cuda支持的时候加载模型到cpu上计算 将 model = torch.load(path, map_location=lambda storage, loc: storage.cuda(device)) 改为 model = torch.load(path, map_location='cpu') 然后删掉所有变量后面的.cuda()方法 以上这篇PyTorch使用cpu加载模型运算方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
如何使用Pytorch搭建模型
1 模型定义 和TF很像,Pytorch也通过继承父类来搭建模型,同样也是实现两个方法.在TF中是__init__()和call(),在Pytorch中则是__init__()和forward().功能类似,都分别是初始化模型内部结构和进行推理.其它功能比如计算loss和训练函数,你也可以继承在里面,当然这是可选的.下面搭建一个判别MNIST手写字的Demo,首先给出模型代码: import numpy as np import matplotlib.pyplot as plt import
-
使用pytorch搭建AlexNet操作(微调预训练模型及手动搭建)
本文介绍了如何在pytorch下搭建AlexNet,使用了两种方法,一种是直接加载预训练模型,并根据自己的需要微调(将最后一层全连接层输出由1000改为10),另一种是手动搭建. 构建模型类的时候需要继承自torch.nn.Module类,要自己重写__ \_\___init__ \_\___方法和正向传递时的forward方法,这里我自己的理解是,搭建网络写在__ \_\___init__ \_\___中,每次正向传递需要计算的部分写在forward中,例如把矩阵压平之类的. 加载预训练ale
-
使用LibTorch进行C++调用pytorch模型方式
目录 环境 具体过程 下载LibTorch 用pytorch生成模型文件 VS创建工程并进行环境配置 运行VS2017工程文件 总结 前天由于某些原因需要利用C++调用PyTorch,于是接触到了LibTorch,配了两天最终有了一定的效果,于是记录一下. 环境 PyTorch1.6.0 cuda10.2 opencv4.4.0 VS2017 具体过程 下载LibTorch 去PyTorch官网下载LibTorch包,选择对应的版本,这里我选择Stable(1.6.0),Windows,LibT
-
浅谈pytorch 模型 .pt, .pth, .pkl的区别及模型保存方式
我们经常会看到后缀名为.pt, .pth, .pkl的pytorch模型文件,这几种模型文件在格式上有什么区别吗? 其实它们并不是在格式上有区别,只是后缀不同而已(仅此而已),在用torch.save()函数保存模型文件时,各人有不同的喜好,有些人喜欢用.pt后缀,有些人喜欢用.pth或.pkl.用相同的torch.save()语句保存出来的模型文件没有什么不同. 在pytorch官方的文档/代码里,有用.pt的,也有用.pth的.一般惯例是使用.pth,但是官方文档里貌似.pt更多,而且官方也
-
pytorch模型预测结果与ndarray互转方式
预测结果转为numpy: logits=model(feature) #如果模型是跑在GPU上 result=logits.data.cpu().numpy() / logits.cpu().numpy() #如果模型跑在cpu上 result=logits.data.numpy() / logits.numpy() 将矩阵转为tensor: np_arr = np.array([1,2,3,4]) tensor=torch.from_numpy(np_arr) 以上这篇pytorch模型预测结
-
MxNet预训练模型到Pytorch模型的转换方式
预训练模型在不同深度学习框架中的转换是一种常见的任务.今天刚好DPN预训练模型转换问题,顺手将这个过程记录一下. 核心转换函数如下所示: def convert_from_mxnet(model, checkpoint_prefix, debug=False): _, mxnet_weights, mxnet_aux = mxnet.model.load_checkpoint(checkpoint_prefix, 0) remapped_state = {} for state_key in m
-

PyTorch 模型 onnx 文件导出及调用详情
目录 前言 基本用法 高级 API 前言 Open Neural Network Exchange (ONNX,开放神经网络交换) 格式,是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移 PyTorch 所定义的模型为动态图,其前向传播是由类方法定义和实现的 但是 Python 代码的效率是比较底下的,试想把动态图转化为静态图,模型的推理速度应当有所提升 PyTorch 框架中,torch.onnx.export 可以将父类为 nn.Module 的模型导出到 onnx 文件中,
-
pytorch模型的保存和加载、checkpoint操作
其实之前笔者写代码的时候用到模型的保存和加载,需要用的时候就去度娘搜一下大致代码,现在有时间就来整理下整个pytorch模型的保存和加载,开始学习把~ pytorch的模型和参数是分开的,可以分别保存或加载模型和参数.所以pytorch的保存和加载对应存在两种方式: 1. 直接保存加载模型 (1)保存和加载整个模型 # 保存模型 torch.save(model, 'model.pth\pkl\pt') #一般形式torch.save(net, PATH) # 加载模型 model = torc
-
PyTorch模型转TensorRT是怎么实现的?
转换步骤概览 准备好模型定义文件(.py文件) 准备好训练完成的权重文件(.pth或.pth.tar) 安装onnx和onnxruntime 将训练好的模型转换为.onnx格式 安装tensorRT 环境参数 ubuntu-18.04 PyTorch-1.8.1 onnx-1.9.0 onnxruntime-1.7.2 cuda-11.1 cudnn-8.2.0 TensorRT-7.2.3.4 PyTorch转ONNX Step1:安装ONNX和ONNXRUNTIME 网上找到的安装方式是通过
-
如何将pytorch模型部署到安卓上的方法示例
目录 模型转化 安卓部署 新建项目 导入包 页面文件 模型推理 这篇文章演示如何将训练好的pytorch模型部署到安卓设备上.我也是刚开始学安卓,代码写的简单. 环境: pytorch版本:1.10.0 模型转化 pytorch_android支持的模型是.pt模型,我们训练出来的模型是.pth.所以需要转化才可以用.先看官网上给的转化方式: import torch import torchvision from torch.utils.mobile_optimizer import opti
-
加速 PyTorch 模型训练的 9 个技巧(收藏)
目录 Pytorch-Lightning 1.DataLoaders 2.DataLoaders中的workers的数量 3.Batchsize 4.梯度累加 5.保留的计算图 6.单个GPU训练 7.16-bit精度 8.移动到多个GPUs中 9.多节点GPU训练 10.福利!在单个节点上多GPU更快的训练 对模型加速的思考 让我们面对现实吧,你的模型可能还停留在石器时代.我敢打赌你仍然使用32位精度或GASP甚至只在一个GPU上训练. 我明白,网上都是各种神经网络加速指南,但是一个check
-
PyTorch模型保存与加载实例详解
目录 一个简单的例子 保存/加载 state_dict(推荐) 保存/加载整个模型 保存加载用于推理的常规Checkpoint/或继续训练 保存多个模型到一个文件 使用其他模型来预热当前模型 跨设备保存与加载模型 总结 torch.save:保存序列化的对象到磁盘,使用了Python的pickle进行序列化,模型.张量.所有对象的字典. torch.load:使用了pickle的unpacking将pickled的对象反序列化到内存中. torch.nn.Module.load_state_di