ChatGPT编程秀之跨越认知边界
目录
- 作者说
- 碰到了认知边界
- 跨越认知边界
- 总结一下
作者说
最近要忙了,日更的日子要到头了。后面每一篇讲的点就小一点吧,大的点等后面有空了再写。大家见谅。
碰到了认知边界
我的有的朋友跟我说,用ChatGPT编程需要你至少要跟他对等水平,因为现阶段我们还不能做到完全不需要关心它写出来的代码,当你要读懂它写的代码的时候,就必须能力对等。还有的朋友跟我说,ChatGPT的不能超过你的认知水平,你的认知水平的上限决定了它的表现,比如你认知水平不行,导致自己不能分解任务的时候,那么你用ChatGPT也写不出代码。
上面说的都没错,但是如果是以往的工具,它可能到这里就会出现一种分层。这种分层就会导致人和人的差距的鸿沟在企业里可能就会变成一种划分职级的边界。但是ChatGPT跟以往的工具都不同,以往的工具他没有办法提升你的认知,没有办法提升你的水平。但是ChatGPT可以扮演多种角色,除了当一个生产工具之外,它还可以当一个教学工具。也就是说,当你进入到了一种低认知的状态,他可以立刻转变为教学工具,让你通过学习进入高认知状态,提升你的水平。然后你就又可以一种较高认知的水准进行工作了。
举个例子,在我们的这个程序里:

开发最后的png_info_post_inject模块时,我其实并不会操作png的内嵌信息,以前也没有过类似的经验。所以一开始,我只是想当然的认为nodejs应该可以吧。所以我问了他很多的问题,做了很多的设计,甚至改了很多遍。就是想让他用Node.js给我做出来。经过一系列的尝试之后,果然就失败了。(主要是我用的AI自己会在图片里留一些信息,我又不想覆盖掉,我还想它的信息和我的信息在作图AI的软件里都能被看到。)我又让他给了我其他的库或原生的写法,都不太好用。由于我太有自信了,所以这个过程中我全程TDD,为了搭建这个测试环境还浪费了我很多时间。
然后在这个时候我就进入了一种迷茫的状态。我不知道该怎么办了。
跨越认知边界
幸好我现在的工具是个人工智能。所以我问他:

嗯……Python,我的画图AI也是用的python,这个应该可行。但是这回我学聪明了。我并不直接开始TDD。我先建了个spike文件夹。也就是调研用的。这里的代码呢只是做一个尝试。并不真正作为产品代码使用。
其实这个动作在TDD里面也是被讲究的,你应该先调研,调研完了之后再来tdd。你不应该带着对某一个知识点的不理解工作,并且在你的代码里边试验边学习一个知识点。这种做法非常常见,但是其实是反模式。因为你的代码里往往都有各种各样的其他无关因素,造成了你的学习效率不高。学习一个知识点和将这个知识点用于工作,应该是两个阶段。
所以接下来我是这么做的。我新建了一个spike文件夹。然后开始在里面实验我的代码这个spike文件夹我有可能最终是不会提交到代码库的。
然后我在里面准备了一张test.png
然后调研用python来访问png,但是我毕竟不太了解这个领域,我决定开始之前double check以下,我又问了一遍

hmm……果然有点小坑,也不知道哪个是哪个,看起来PIL更基础一点,行吧,我的功能不复杂,可能PIL就够用了。
于是我问:
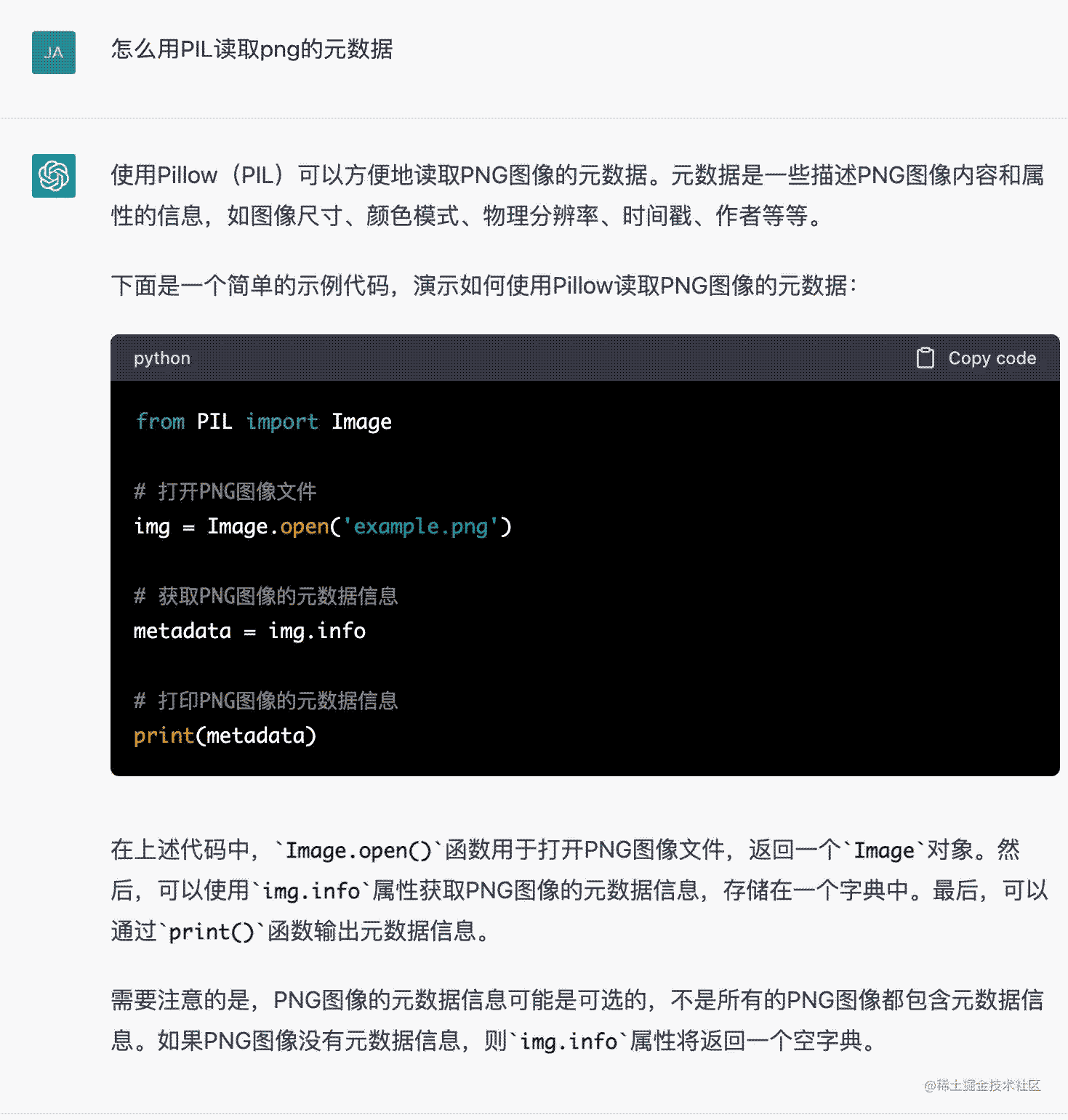
似乎又说PIL就是Pillow,不知道靠不靠谱啊。我们都知道,ChatGPT经常会编造。这也是很多人不信任他的地方。别的领域我们不好说,但是编程领域其实不太有必要不信任他。一个是你看我们可以像这样去做一个double check。另一个就是我们可以让他从他讲的方案直接生成代码。如果他的方案不可行,你代码自然没法执行。甚至你把代码提到ide里,它可能都会有语法错误,对吧?我们有一套完整的IDE、编译器和我们的电脑组成的开发环境来验证它输出的内容是不是可信的。这也是我为什么这么放心大胆用于编程的原因。
那么既然我们得到了代码,我就可以开始试验了,我直接把example.png 改成了test.png,果然打印了出来,这可行!
然后就又问了他怎么修改,怎么append,这里就不展示了,其实如果自己走一遍就会发现,这个里面修改可能是完全覆盖可能是append,我前面说,我想保留原有信息,所以我需要的是append,这个就不是那么直接可用了,跟它折腾了一会。
所以spike这一步的其中一个意义就在这里:我可以在一个非常单纯的环境下随意地测试方案是否可行,而不用带上其他复杂的上下文,毕竟我做到这里的时候,程序也挺长的了,输入的intention.yml也挺复杂的了,每次都从头测试也很低效。
接着我又让他给我生成了nodejs怎么调用python,在今天之前,我也从来没用过这个能力。这个能力spike的很快,spike完我就直接封装了一个runPythonScript函数出来。
接着到了真正的集成点。我们需要把Python代码封装成一个node js函数,然后对我们的程序提供服务。这个时候再给大家演示一下,上一篇我们提到的编程语言也是一种语言的场景:

所以可以看到,我们可以直接把代码给他,不用说太多废话。他自己能看懂,然后让他来抹平集成时可能出现的问题。比如传参问题还有返回值问题。我之前并不知道要怎么传参和得到返回值,现在我知道了。
所以前面调研环节的另一个价值就体现出来了:你调研得到的代码可以直接作为prompt使用,并不需要还转化为什么自然语言,语言就是语言,都能作为prompt的一部分,而且啊,搞不好chatgpt还更喜欢编程语言,毕竟人类的自然语言太不严谨了。
总结一下
在本文中,我们探讨了使用ChatGPT进行编程时可能会遇到的认知边界,并分析了ChatGPT与传统工具的不同之处。与传统工具相比,ChatGPT可以扮演多种角色,除了当一个生产工具之外,它还可以当一个学习工具。这意味着,当你遇到认知边界时,ChatGPT可以立即转变为教学角色,帮助你通过学习进入高认知状态。
通过一个实际的例子我们看到了,当我们在编程中遇到自己不会的事情的时候,因为我们自己也分解不出任务,ChatGPT也不能帮我们解决问题,ChatGPT的表现也会下降。这时,我们可以进行调研,也就是进入学习状态。这个时候我们就可以把ChatGPT当成学习工具使用,提升自己的认知,从而提升ChatGPT的表现。
其实编程工作一直是有两个状态的,一个是学习态,一个是工作态。而且经常是要随时切换的,所以我们要时刻提醒自己,意识到自己是处于学习态还是工作态。两种状态的工作流程我总结了一下,如下图所示:
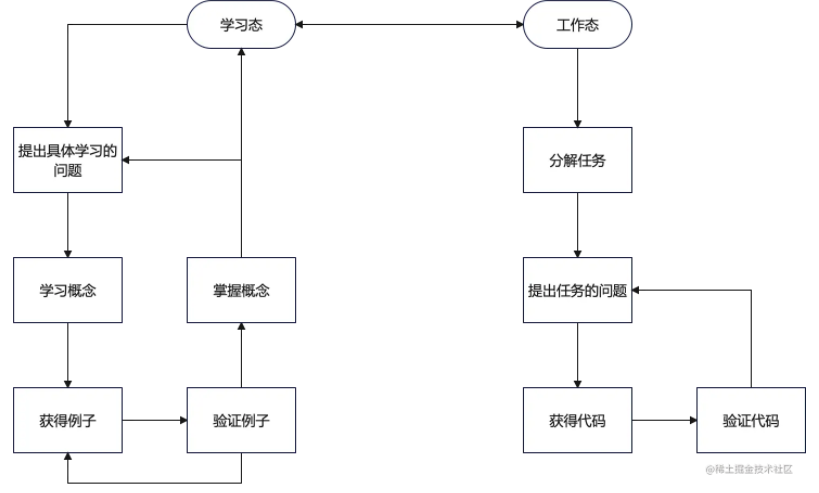
最后再说一点,结合我们上一篇提到的编程语言也是语言的思路,调研过程中得到的代码其实并不是什么浪费,他可以作为prompt的一部分来加速我们后面工作态时的效率。在以前,其实这样做也是可以提效的,但是因为整个过程是在人脑中,并不是很明显,今天我们通过ChatGPT来编程,我们就会发现,这种方法确实是更科学而高效的。
以上就是ChatGPT编程秀之跨越认知边界的详细内容,更多关于ChatGPT 认知边界的资料请关注我们其它相关文章!
相关推荐
-
ChatGPT用于OA聊天助手导致访问量服务宕机
目录 闲谈 开搞 面临的问题 聊天UI 服务端接口 上线宕机 优化问题处理 流式传输 MD格式 看看效果 闲谈 最近,火到不行的明星团队产品 ChatGPT,热度一度非常高,付费用户都开始通过邀请制,专属登陆链接来限制流量了.开了Plus以后返回内容和速度真是10倍速啊~ 但对于小白或普通用户(也可能非技术行业的大佬),想要访问和体验还是挺麻烦的.除了准备梯子.接码.账号以外还可能遇到节点或网络,多次连接失败的问题. 所以,本着能折腾绝对不休息的原则,2天搞了一个聊天助手,凭借其语义的理解,关联
-
ChatGPT前端编程秀之别拿编程语言不当语言
目录 TDD第一步就卡住了 破门而入,针对性反馈 总结一下 TDD第一步就卡住了 写完小工具,这一篇回来我们接着写我们的程序.再看一眼我们的程序运行视图: 带着TDD思路,我进入了 ejs_and_yaml_dsl_loader 这个模块,这块因为我切的不是很好,所以这代码有点难写,不过没关系,正好我们实际工作大部分的场景都是这样的.看看我们在这里能玩出点什么来. 那么这次的需求呢是这个样子的,我们需要把ejs模版引擎渲染出的yaml转换为json,那么我们这个功能会非常复杂,所以我们没有以上来
-
详解微信小程序如何实现类似ChatGPT的流式传输
目录 正文 小程序上实现流失传输 什么是流式传输? 为什么小程序不支持流式传输? 我的解决方案 常规方案Axios 另辟蹊径:onChunkReceived方案 后端接口配置 正文 最近指导群里小兄弟技术问题,发现一个让我也棘手的难题.于是激发了我潜意识精神力-干到底. 由于最近沉浸在chatgpt中,很久不用google和百度搜索东西了,正如我所料一般,他们也没有这方面的解决方案.于是,记录一下探索研究的过程,给各位水友一个分享扩展. 小程序上实现流失传输 模拟ChatGPT的效果,实现流式传
-
SpringBoot整合chatGPT的项目实践
目录 1 添加依赖 2 创建相关文件 2.1 实体类:OpenAi.java 2.2 配置类:OpenAiProperties.java 2.3 核心业务逻辑OpenAiUtils.java 2.4 自动配置类OpenAiAutoConfiguration.java 2.5 在resources文件夹下的META-INF/spring.factories文件中增加配置 2.6 在yml文件上配置token 3 编写测试类 4 补充 4.1 添加依赖 4.2 添加代码 5 总结 1 添加依赖 <!
-
python借助ChatGPT读取.env实现文件配置隔离保障私有数据安全
目录 正文 Python怎么读取.env配置文件,实现一个代码封装 Python怎么读取.env配置文件,获取所有项,实现一个代码封装 Python怎么读取.env配置文件,获取所有项,只读取.env中的项,实现一个代码封装 正文 今天借助ChatGPT完成我们这步骤,主要涉及三个问题: 1. Python怎么读取.env配置文件,实现一个代码封装 2. Python怎么读取.env配置文件,获取所有项,实现一个代码封装 3. Python怎么读取.env配置文件,获取所有项,只读取.env中的
-
ChatGPT编程秀之跨越认知边界
目录 作者说 碰到了认知边界 跨越认知边界 总结一下 作者说 最近要忙了,日更的日子要到头了.后面每一篇讲的点就小一点吧,大的点等后面有空了再写.大家见谅. 碰到了认知边界 我的有的朋友跟我说,用ChatGPT编程需要你至少要跟他对等水平,因为现阶段我们还不能做到完全不需要关心它写出来的代码,当你要读懂它写的代码的时候,就必须能力对等.还有的朋友跟我说,ChatGPT的不能超过你的认知水平,你的认知水平的上限决定了它的表现,比如你认知水平不行,导致自己不能分解任务的时候,那么你用ChatGPT也
-
ChatGPT编程秀之最小元素的设计示例详解
目录 膨胀的野心与现实的窘境 新时代,新思路 总结一下 膨胀的野心与现实的窘境 上一节随着我能抓openai的列表之后,我的野心开始膨胀,既然我们写了一个框架,可以开始写面向各网站的爬虫了,为什么只面向ChatGPT呢?几乎所有的平台都是这么个模式,一个列表,然后逐个抓取.那我能不能把这个能力泛化呢?可不可以设计一套机制,让所有的抓取功能都变得很简单呢?我抽取一系列的基础能力,而不管抓哪个网站只需要复用这些能力就可以快速的开发出爬虫.公司内的各种平台都是这么想的对吧? 那么我们就需要进行设计建模
-

Python黑帽编程 3.4 跨越VLAN详解
VLAN(Virtual Local Area Network),是基于以太网交互技术构建的虚拟网络,既可以将同一物理网络划分成多个VALN,也可以跨越物理网络障碍,将不同子网中的用户划到同一个VLAN中.图2是一个VLAN划分的例子. 图2 实现VLAN的方式有很多种,基于交换设备的VLAN划分,一般有两种: l 基于交换机的端口划分 l 基于IEEE 802.1q协议,扩展以太网帧格式 基于第二层的VLAN技术,有个Trunking的概念,Trunking是用来在不同的交换机之间进行连接,以
-
适合面向ChatGPT编程的架构示例详解
目录 新的需求 领域知识 架构设计 管道架构 分层架构 类分层神经网络的架构 总结一下 新的需求 我们前面爬虫的需求呢,有些平台说因为引起争议,所以不让发,好吧,那我们换个需求,本来那个例子也不好扩展了.最近AI画图也是比较火的,那么我们来试试做个程序帮我们生成AI画图的prompt. 首先讲一下AI话题的prompt的关键要素,大部分的AI画图都是有一个个由逗号分割的关键字,也叫subject,类似下面这样: a cute cat, smile, running, look_at_viewer
-
Python+ChatGPT实现5分钟快速上手编程
目录 1.chatGPT是个啥 2.chatGPT怎么注册 3.chatGPT怎么用 4.小结 最近一段时间chatGPT火爆出圈!无论是在互联网行业,还是其他各行业都赚足了话题. 俗话说:“外行看笑话,内行看门道”,今天从chatGPT个人体验感受以及如何用的角度来分享一下. 1.chatGPT是个啥 chatGPT是最近新出来的玩意?并不是!在国内,chatGPT最早是在2022年11月就由OpenAI于推出的.只是去年底火了一把,后力不足又遇春节,热度草草就结束了. 先讲一下,OpenAI
-
浅析Nginx配置文件中的变量的编写使用
nginx 的配置文件使用的就是一门微型的编程语言,许多真实世界里的 Nginx 配置文件其实就是一个一个的小程序.当然,是不是"图灵完全的"暂且不论,至少据我观察,它在设计上受 Perl 和 Bourne shell 这两种语言的影响很大.在这一点上,相比 Apache 和 Lighttpd 等其他 Web 服务器的配置记法,不能不说算是 Nginx 的一大特色了.既然是编程语言,一般也就少不了"变量"这种东西(当然,Haskell 这样奇怪的函数式语言除外了).
-
.NET正则表达式最佳用法
目录 考虑输入源 适当处理对象实例化 静态正则表达式 已解释与已编译的正则表达式 正则表达式:编译为程序集 控制回溯 使用超时值 只在必要时捕获 .NET 中的正则表达式引擎是一种功能强大而齐全的工具,它基于模式匹配(而不是比较和匹配文本)来处理文本. 在大多数情况下,它可以快速.高效地执行模式匹配. 但在某些情况下,正则表达式引擎的速度似乎很慢. 在极端情况下,它甚至看似停止响应,因为它会用若干个小时甚至若干天处理相对小的输入. 本主题概述开发人员为了确保其正则表达式实现最佳性能可以采纳的一些
-
c#互斥锁Mutex类用法介绍
什么是Mutex “mutex”是术语“互相排斥(mutually exclusive)”的简写形式,也就是互斥量.互斥量跟临界区中提到的Monitor很相似,只有拥有互斥对象的线程才具有访问资源的权限,由于互斥对象只有一个,因此就决定了任何情况下此共享资源都不会同时被多个线程所访问.当前占据资源的线程在任务处理完后应将拥有的互斥对象交出,以便其他线程在获得后得以访问资源.互斥量比临界区复杂,因为使用互斥不仅仅能够在同一应用程序不同线程中实现资源的安全共享,而且可以在不同应用程序的线程之间实现对
-
.NET正则表达式的最佳用法
目录 考虑输入源 适当处理对象实例化 静态正则表达式 已解释与已编译的正则表达式 正则表达式:编译为程序集 控制回溯 使用超时值 只在必要时捕获 .NET 中的正则表达式引擎是一种功能强大而齐全的工具,它基于模式匹配(而不是比较和匹配文本)来处理文本. 在大多数情况下,它可以快速.高效地执行模式匹配. 但在某些情况下,正则表达式引擎的速度似乎很慢. 在极端情况下,它甚至看似停止响应,因为它会用若干个小时甚至若干天处理相对小的输入. 本主题概述开发人员为了确保其正则表达式实现最佳性能可以采纳的一些
-
Go语言中的数据竞争模式详解
目录 前言 Go在goroutine中通过引用来透明地捕获自由变量 切片会产生难以诊断的数据竞争 并发访问Go内置的.不安全的线程映射会导致频繁的数据竞争 Go开发人员常在pass-by-value时犯错并导致non-trivial的数据竞争 消息传递(通道)和共享内存的混合使用使代码变得复杂且易受数据竞争的影响 Add和Done方法的错误放置会导致数据竞争 并发运行测试会导致产品或测试代码中的数据竞争 小结 前言 本文主要基于在Uber的Go monorepo中发现的各种数据竞争模式,分析了其